پیشرفت ها در مدلهای بازشناسی چهره، ابزارها و مجموعه دادهها

پیشرفتهای حاصله در مدلهای تشخیص چهره، ابزار و مجموعهدادهها
اگر به یادگیری عمیق و face recognition علاقه دارید، این آموزش برای شما مناسب خواهد بود.
در این مقاله به بررسی جامع مدلهای بازشناسی و تشخیص چهره، ابزارها ، ومجموعه دادهها (دیتاستها) و روال تشخیص و بازشناسی چهره پرداخته میشود. این مدلها توسط روشهای اولیه الگوریتم تشخیص چهره با استفاده از مولفه های اصلی((Eigen faces و الگوریتم تشخیص چهره با استفاده از مولفه های خطی(Fisher faces) تا تکنیکهای پیشرفته یادگیری عمیق برای بازشناسی چهره، به طور متوالی هنر تشخیص افراد از تصاویر دیجیتالی را بهبود بخشیدهاند. در این مقاله، این مدلهای جذاب را به صورت دقیق مورد بررسی قرار داده و ویژگیها، قدرتها و ضعف هرکدام را بررسی میکنیم. با تحلیل دقیق، نشان میدهیم که هر مدل، ابزارکیت یا مجموعه داده(دیتاست) بصورت پیاپی کامل کننده نسل قبلی خود هستند و تکنولوژی را به جایگاه جدیدی رهنمون میکنند.
هدف ازاین تحلیل ، ارتقاء دیدگاه شما از مکانیزمهای زیربنایی که سیستمهای تشخیص چهره مدرن را شکل میدهند، میباشد این بررسی به زبان ساده نوشته شده و به امید اینکه بتواند درک شما از سیستمهای بازشناسی چهره را بهبود بخشد.
مدل های پیشرفته بازشناسی چهره(Face recognition)
برای بازشناسی چهره از چه مدل هایی استفاده میشود؟ در حال حاضر برای تشخیص چهره از چندین مدل بهروز و پیشرفته که توسط مجموعه ای از دادههای بزرگ تحلیل و بررسی شده اند استفاده میشود. . در این بخش، نگاهی به برخی ازاین مدل های با توان و قابلیت های بالا خواهیم پرداخت.
سیستم پردازش تصویر(deep face ) در فیس بوک (2014)
نکات کلیدی:
- مدل DeepFace با بیش از ۱۲۰ میلیون پارامتر کار میکند.
- این مدل یک شبکه عصبی عمیق با ۹ لایه است.
- از لایههای محلی به جای شبکههای عصبی کانولوشنی استفاده میکند.
- شامل یک مجموعه داده (دیتاست) آموزش دیده از چهره های مختلف (بیش از 4میلیون تصویر) در شبکههای اجتماعی و دستهبندی آنها بر اساس ویژگیهای مختلف است (SFC)
- دقت پیشبینی آن ۹۷.۳۵ درصد است.
- این یک مدل یادگیری عمیق برای انجام فعالیت های مرتبط با تحلیل چهره ، از جمله تأیید چهره ، شناسایی و بررسی ویژگیهای چهره و تحلیل آن بدون وقفه است. ساختار آن در شکل ۱ نمایش داده شده است.

شکل 1-معماری مدل deepface
چهره های موجود در مجموعه داده (دیتاست) SFC از یک مجموعه بزرگ تصاویر چهره از دادههای پروفایل کاربری فیسبوک جمعآوری شدهاند. همچنین، این مدل میتواند امکان تشخیص چهره یک شخص را در پایگاه داده تصاویر فراهم کند.تحلیل ویژگیهای چهره نیز یکی از قابلیتهای DeepFace است که ویژگیهای بصری تصاویر را شرح میدهد. این مدل در سناریوهای تحلیل چهره به صورت آنی ودر لحظه ، تست شده و توانسته است شناسایی چهره و تحلیل ویژگیهای آن را بر روی ویدیوهای زنده انجام دهد.
سیستم تشخیص چهره FaceNet با دقت بالا در گوگل(2015)
نکات کلیدی:
- مدل FaceNet با بیش از ۱4۰ میلیون پارامتر کار میکند.
- این مدل دارای 22 لایه شبکه عصبی کانولوشنی عمیق با نرمال سازی L2 است
- تابع خطای triplet loss توسط این سیستم معرفی شد
- دقت پیشبینی این مدل بر روی مجموعه داده (دیتاست)های (چهره افراد مختلف در شرایط واقعی )LFW و YFD(چهره افراد مختلف در یوتیوب) به ترتیب ۹۹.۲۵ و ۹۵.۱۲ درصد است.
درحقیقت FaceNet بعنوان راهکار گوگل به مسئله شناسایی چهره معرفی شد. ساختار شبکهی عصبی این مدل در شکل ۲ نمایش داده شده است.

شکل 2-معماری مدل FaceNet
در این روش، یک فضای اقلیدسی کوچک (فضایی که فاصله بین دو نقطه در آن، معیاری از شباهت یا تفاوت آنها باشد و به این صورت میتوان از آن برای تشخیص چهرههای مشابه و یا تفاوتهای آنها استفاده کرد ) پیادهسازی شده است. این مدل چند ویژگی مهم دارد. ابتدا، هر چهره با یک بردار ۱۲۸ بایتی نمایش داده میشود که در خوشهبندی و تشخیص مقیاسپذیر کمک میکند.. ثانیا، گوگل همراه با FaceNet تابع خطای triplet loss را معرفی کرد (نمایش داده شده در شکل ۳). این تابع با کمترین حجم محاسباتی، به بهترین تریپلهای منفی برای آموزش مدل میرسد و قابلیت ایجاد تریپلهای مفید را دارد علاوه براین از تابع خطای triplet loss و مکانیزم انتخاب تریپلها برای آموزش استفاده میکند.
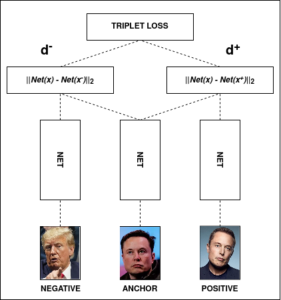
شکل3-نمایش از تابع triplet loss
این تکنیک با استفاده از روشهای انتخاب نمونههای مناسب، تریپلهای مفیدی را شکل میدهد. دادهها به صورت یک سهتایی نقطه (نقطه مرجع ، مثبت و منفی) ترتیب داده میشوند و سپس وارد یک شبکه عصبی عمیق میشوند تا با کاهش فاصله بین نقطه مرجع و مثبت و افزایش فاصله بین نقطه مرجع و منفی، مدل آموزش داده شود. این روش میتواند به صورت ریاضی به شکل زیر بیان شود:
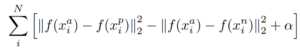
شکل ۴-عبارت ریاضی تابع Triplet Loss
گوگل چندین مدل دیگر را آموزش داد و مدل پایه FaceNet را با آنها مقایسه کرد. در شکل ۵، مشخصات مدلهای سفارشی و معیارهای عملکرد اعتبارسنجی مربوط به هر یک از آنها نشان داده شده است.
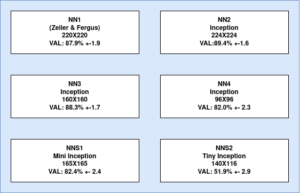
شکل ۵: مدل آموزش داده شده FaceNet و معیارهای اعتبارسنجی
مدل VGG-Face ساخت دانشگاه اکسفورد (2015)
نکات کلیدی :
- این مدل با 145 میلیون پارامتر کار میکند.
- یک شبکه عصبی کانولوشنی ۳۷ لایه، با ۱۱ بلوک ساخته شده است.
- مدل بر روی ۲.۶ میلیون تصویر چهره آموزش داده شده است.
- دقت پیشبینی: ۹۸.۹۵ درصد در مجموعه داده(دیتاست) LFW و ۹۷.۳ درصد در مجموعه داده(دیتاست) YFD.
مدل VGG-Face در دانشکده علوم مهندسی دانشگاه اکسفورد توسط گروه ویژوال جئومتری با هدف ایجاد حس بصیرت در هوش مصنوعی و ماشینها توسعه داده شده است ،. معماری این مدل در شکل ۶ نشان داده شده است. معماری کلی این مدل به سادگی با ترکیب لایههای کانولوشن و ReLU، لایههای مکس پولینگ و تابع فعالسازی softmax طراحی شده است.

شکل 6-معماری VGG-Face
مدل VGG-Face بهمراه FaceNet ، در فرایند آموزش از تابع Triplet Loss , برای یادگیری نشانه گذاری چهره (تبدیل یک چهره به یک بردار عددی با طول ثابت که ویژگیهای مختلف تصویر را با در نظر گرفتن فضای برداری به آن نسبت میدهد )
استفاده میکند
مدل ArcFace (2015)
نکات کلیدی:
- مدل ArcFace از شبکه عصبی کانولوشنی استفاده میکند.
- از تابع اضافهکردن مارجین زاویهای برای بهبود کیفیت نشانه گذاری استفاده میکند.
- برای شناسایی از شباهت کسینوسی استفاده میکند.
- دقت پیشبینی: ۹۹.۴۰ درصد در مجموعه داده (دیتاست). LFW
معماری ArcFace در شکل ۷ نشان داده شده است که شامل چندین اجزای کلیدی میباشد. از بخش اصلی(backbone) برای استخراج ویژگیهای سطح بالا از تصاویر چهره استفاده میشود. این ویژگیها خصوصیت های مهم چهره را به خوبی دربردارند و برای نمایش چهره ورودی استفاده میشوند. همچنین، ArcFace یک لایه کاملاً ارتباطی معرفی میکند، که به عنوان “لایه ArcFace” شناخته میشود و نمایش زاویهای ویژگیهای استخراج شده را محاسبه میکند.

شکل 7- معماری ArcFace
این لایه، تابع arc-cosine را به حاصل ضرب داخلی بین بردارهای ویژگی و بردارهای وزن مربوطه اعمال میکند. زوایای حاصل، سپس برای اندازهگیری شباهت بین هویتهای چهره مختلف استفاده میشود. برای افزایش توانایی تشخیص دهی مدل، ArcFace یک تکنیک نرمالسازی را به نام مارجین زاویهای افزایشی (additive angular margin) دربردارد. این مارجین، فاصله مناسبی بین هویتهای مختلف در فضای زاویهای اعمال میکند. با افزایش مارجین، مدل میتواند بین چهرههای مشابه را راحت تر تشخیص دهد و دقت مدل را بهبود بخشد. پیادهسازی ریاضی روش ArcFace در زیر نشان داده شده است.
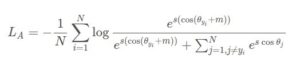
شکل8- عبارت ریاضی ArcFace
در فرآیند آموزش، الگوریتم ArcFace با کمینه کردن خطای تابع هزینهی زاویهای softmax، پارامترهای مدل را بهینهسازی میکند. . این تابع هزینه سعی میکند احتمال درست بودن کلاس موردنظر را افزایش دهد و در عین حال فاصلهی زاویهای بین دستهها را بیشتر کند. این تابع هزینه تمام تلاش خود را دارد اختلاف زاویهای پیشبینی شده با زاویهی هدف، را به حداقل برساند فاصلهی زاویهای بین دستهها را افزایش داده و احتمال درست بودن کلاس موردنظر را بیشتر کند.
در تصویر زیر، مقایسهای بین تابع هزینه softmax و پیادهسازی ArcFace را مشاهده میکنیم.
مشاهده میشود که تابع هزینه softmax، برای جداسازی ویژگیهای دادههای ورودی کافی نیست، در حالی که تابع هزینه ArcFace با ایجاد فاصلهی بیشتری بین دستههای نزدیک به هم، قابلیت تمایز بهتری بین دادههای ورودی را فراهم میکند. به عبارت دیگر، تابع هزینه ArcFace، بهتر از تابع هزینه softmax، دادههای ورودی را از یکدیگر جدا میکند.
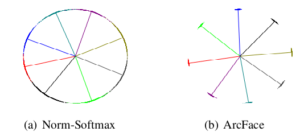
شکل 9-مقایسه تابع هزینه softmax و ArcFace
ابزارهای معروف تشخیص چهره
در بخش قبل، چندین مدل پیشرفته را بررسی کردیم.آیا میخواهید این مدلهای را پیادهسازی و اجرا کنید و با آنها آزمایشهایی انجام دهید؟، به عنوان یک مبتدی، این فرآیند پیچیده و زمانبر خواهد بود. برای حل این مشکل، چندین ابزار اپن سورس برای اجرای این مدلها و انجام آزمایشها با آنها،توسعه داده شده است.
در اینجا نگاهی اجمالی داریم به چند ابزار تشخیص چهره که بیشترین تراکنش در گیتهاب را داشتهاند،.
تشخیص چهره با OpenCV با (Seventh Sense )
تشخیص چهره OpenCV، خدمات پیشرفته تشخیص چهرهای است که به دنبال همکاری بین کتابخانه پردازش تصاویر پیشرو OpenCV و Seventh Sense(سازندگان فناوری تشخیص چهره دارای بالاترین امتیاز جهان) به وجود آمده است.
شکل 10: تشخیص چهره OpenCV.
توسعهدهندگان با استفاده از این ابزارکیت، با چند خط کد ساده، میتوانند به برنامههایشان قابلیت تشخیص چهره اضافه کنند. این پیادهسازی در چالش تشخیص چهره NIST سال 2022 در رتبه ده اول قرار دارد و برای استفاده از آن، تجربه قبلی در یادگیری ماشین یا GPU لازم نیست؛ زیرا کاملاً بر اساس فراخوانی API طراحی شده است. از طریق رابط کاربری وب داخلی، این ابزارکیت قابل دسترسی است. در صورت تمایل به یادگیری بیشتر، میتوانید مقاله جامعی در مورد تشخیص چهره OpenCV را مطالعه کنید.
DeepFace:

شکل 11: نمونه از انبارداده DeepFace در GitHub.
این کتابخانه یک ابزار ساده تجزیه و تحلیل تصویر چهره برای پایتون است که شامل مجموعه ای پایدار , قوی ودقیق برای انجام مراحل پردازش تصاویر(ورودی , پردازش و خروجی ) جهت تشخیص، ترازبندی، نرمالسازی، نمایش و اعتبارسنجی چهرهها است. برای تشخیص، این کتابخانه از الگوریتمهای تشخیص معروفی مانند OpenCV، MTCNN، RetinaFace، MediaPipe، Dlib و SSD پشتیبانی میکند.
علاوه براین ، این کتابخانه از پشتیبانی برای اعتبارسنجی چهره جهت شباهتها و تفاوت های بین چهره ها استفاده میکند
لازم به ذکراست این کتابخانه از آرایه NumPy و تصویر با کدگذاری base64 نیز پشتیبانی میکند
کتابخانه DeepFace یک تابع برای تبدیل چهره به بردار دارد که این بردارها بصورت چند بعدی نشان داده میشوند. شایان ذکر است که ، این کتابخانه یک تابع نمایش اختصاصی دارد که لیستی از اطلاعات تصاویر را جهت تبدیل به بردار از تصویر چهره ورودی برمیگرداند. این کتابخانه همچنین قادر به انجام تحلیل ویژگیهای چهره است که به دنبال پارامترهایی مانند سن، احساسات، جنسیت و همچنین نژاد هستند.
یکی از بزرگترین ویژگیهای کتابخانه DeepFace، پشتیبانی گسترده آن از چندین مدل است که شامل VGG-Face، FaceNet، FaceNet512، OpenFace، DeepFace، DeepID، ArcFace، Dlib و SFace میشود.
این تابع با سیستم های تحلیل بلادرنگ، برای هر 5 فریم بصورت متوالی روی فریم چهره تمرکز میکند. در نهایت، این تابع به عنوان یک سرویس REST-API برای کاربران ارائه میشود و همچنین میتواند به صورت محیط اجرایی جداگانه و قابل حمل برای نرمافزارها(Docker Container)توزیع شود یا بر روی یک کلاستر Kubernetes مستقر شود.
TFace:

شکل 12-انبار داده TFace در GitHub
TFace یک پلتفرم تحقیقاتی اپن سورس برای تحلیل چهره است که توسط شرکت تحقیقاتی فعال در زمینه پردازش تصویر و تشخیص چهره(Tencent Youtu Lab) توسعه داده شده است. این پلتفرم دارای ویژگیهای مفیدی برای پردازش مجموعه داده (دیتاست) است، از جمله پشتیبانی از مجموعه داده(دیتاست) های تک و چندگانه با IndexParser ، ImgSampleParser و TFRecordSampleParser است.
TFaceیک مجموعه مدل پایه دارد که شامل پیادهسازیهای آماده ResNet(SEResNet)، MobileFaceNet، EfficientNet، FBNet و GhostNet است. همچنین، این پلتفرم از توابع خطا مانند CurricularFace، DDL، CIFP و SCF پشتیبانی میکند. علاوه بر توابع جداگانه، این پلتفرم دارای پروتکلهای تست برای ارزیابی عملکرد و زمان تاخیر مدل در ساختارهای ARM و x86 است.
InSightFace

شکل13-مثال تشخیص چهره از انبار داده InSightFace در GitHub
InSightFace یک کتابخانه تحلیل چهره 2D و 3D است که الگوریتمهای پیشرفته تشخیص چهره، شناسایی چهره و ترازبندی چهره راپیادهسازی میکند. این کتابخانه از معماریهای مختلف از قبیل IResNet، RetinaNet، MobileFaceNet، InceptionResNet_v2 و DenseNet و مجموعه داده (دیتاست) های چهرهای مانند MS1M، VGG2 و CASIA-WebFace پشتیبانی میکند. InSightFace علاوه بر مدلها، چند روش ارزیابی بر مبنای دقت وزمان پردازش نیز دارد که شامل IJB و MegaFace میشود.
مجموعه دادههای (دیتا ست)تشخیص و شناسایی چهره
پرسش این است که “برای تشخیص و شناسایی چهره چه تعداد مجموعه داده (دیتاست)در دسترس است؟” در واقع، تعداد زیادی گزینه برای انتخاب وجود داردو هر کدام با مزایا و معایب خود.
دراینجا به برخی از این مجموعههای داده(دیتاست) اپن سورس می پردازیم
مجموعه داده ها (دیتاست ها)ی تشخیص چهره
UMD Faces
- مجموعه داده(دیتاست) شامل تصویر با برچسب چهره است که هر تصویر به یکی از 8،277 فرد موجود در مجموعه داده (دیتاست) مربوط میشود
- مجموعه داده(دیتاست) شامل بیش از 3.7 میلیون فریم ویدیویی با برچسب چهره
- آدرس وب سایت : http://umdfaces.io/
Wider Face
- در این مجموعه داده(دیتاست) تغییرات مختلفی در ویژگیهای چهره مانند اندازه، زاویه، مسدود شدن، عبارات صورت، نورپردازی و آرایش در نظر گرفته شده است
- مجموعه داده (دیتاست) شامل 32,203 تصویر که در آن 393,703 چهره برچسبگذاری شدهاند
- آدرس وب سایت: http://shuoyang1213.me/WIDERFACE/
شکل ۱۴: مجموعه داده (دیتاست)های تشخیص چهره اپن سورس
مجموعه داده (دیتاست) های شناسایی چهره
- چهره های برچسب گذاری شده که از در شرایط عادی ودر موقعیت های مختلف گرفته شده است(Labeled Faces in the Wild – LWF)
- وجود 13,232 تصویر از 5,749 نفر است، که 1,680 نفر دارای دو یا بیشتر تصویر هستند
- آدرس وب سایت http://vis-www.cs.umass.edu/lfw/
- یک میلیون چهره افراد مشهور از سراسر جهان(MS-Celeb-1M)
- داشتن تنوع تصاویر چهره برای هر شخص در این مجموعه داده(دیتاست) در نظر گرفته شده است
- مجموعه داده (دیتاست) شامل 6,464,018 تصویر است
- مجموعه داده (دیتاست) شامل 94,682 فرد مشهوراست
- آدرس وب سایت https://github.com/EB-Dodo/C-MS-Celeb
- مجموعه داده (دیتاست) از منابع مختلفی مانند عکسهای تصادفی از وب، شبکههای اجتماعی و ویدئوهای مختلف (VGG Face2)
- توزیع بیطرفانه بین تصاویر چهره مرد و زن(بدون در نظر گرفتن هر گونه تبعیض جنسیتی)
- وجود بیش از 3.3 میلیون چهره در این مجموعه داده
- مجموعه داده (دیتاست) شامل بیش از 9000فرداسسست
- در تصاویر ممکن است فرد مورد نظر به صورت مختلفی قرار بگیرد، احساسات متفاوتی نشان دهد، در نورپردازی های مختلف قرار بگیرد و یا قسمتی از تصویر ممکن است پوشیده شود
- آدرس وب سایت https://www.robots.ox.ac.uk/~vgg/data/vgg_face2/
- تصاویر افراد مشهور در مجموعه داده (دیتاست ) (IMDB-Wiki)
- ترکیبی از تصاویر چهره از صفحات ویکیپدیا و IMDB استفاده شده است.
- وجود ۴۶۰،۷۲۳تصویر (IMDB)در این مجموعه داده
- وجود 62328تصویر (Wiki)در این مجموعه داده
- آدرس وب سایت: https://data.vision.ee.ethz.ch/cvl/rrothe/imdb-wiki/
- تصاویر افراد در یک مجموعه داده ( دیتاست )بزرگ
- بیش از یک میلیون تصویر در این مجموعه داده
- وجود 62328تصویر (Wiki)در این مجموعه داده
- 740هزارتصویراز 10هزار فرد مختلف
- 500هزار تصویر از100هزار فرد مختلف
- آدرس وب سایت: https://microsoft.github.io/DigiFace1M/
شکل ۱۵: دیتاستهای اپن سورس برای تشخیص چهره
یک فرایندتشخیص چهره برای ساخت یک سیستم یکپارچه
فرض کنید علاقهمند به ساخت یک سیستم نظارتی هستید. ممکن است به ذهنتان برسد که بپرسید: “چه مراحلی در ساخت یک سیستم تشخیص چهره از پایه وجود دارد؟”. بیایید یک قدم جلوتر برداشته و به طور کلی به فرآیندهای مختلف در ساخت این سیستم نگاه کنیم. در شکل ۱۶ یک نمودار بلوکی از فرایندهای مختلف در ساخت این سیستم نشان داده شده است.
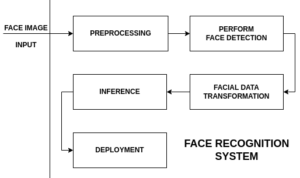
شکل ۱۶: نمودار بلوکی سیستم تشخیص چهره
پیشپردازش تصویر ورودی چهره
در هوش مصنوعی، گفته میشود “یک مدل فقط به اندازه دادههایی که به آن تزریق میشود خوب عمل میکند”، که در واقعیت بسیار درست است. معمولاً تصاویر چهره به طور مستقیم و در قالب اصلی خود قابل استفاده نیستند. در هر تصویر، جزئیات بسیاری در سایهها یا شاید در نوردهی وجود دارند. پیشپردازش تصویر یک روش است که با بازیابی جزئیات و کمک به تفکیک کردن دادههای تصویر چهره خام، قابل استفاده است. عملیات تصویر مانند تغییر اندازه، فیلتر خاکستری، فیلتر همسطحسازی هیستوگرام و ایجاد مجموعه دادههای آموزش و اعتبارسنجی به عنوان مراحل پیشپردازش متداول برای هر مسئله مبتنی بر دید کامپیوتری در نظر گرفته میشوند.

شکل ۱۷: پیشپردازش تصویر چهره
در تصویر بالا، میتوانیم ببینیم که دو فیلتر، سیاه وسفید و همسطحسازی هیستوگرام، روی تصویر اولیه RGB اعمال شدهاند. میتوان نتیجه گرفت که پس از اعمال فیلتر همسطحسازی هیستوگرام، ویژگیهای چهره بیشتر برجسته میشوند. با استفاده از دادههای با کیفیت برای یادگیری، دقت و عملکرد تشخیص سیستم میتواند بهبود یابد.
اجرای فرایند تشخیص چهره
با توجه به تصویر ورودی، مدل باید ابتدا محل چهره در فریم را محدود کند. در حال حاضر، چندین روش برای کمک به این فرآیند وجود دارد. معروفترین تکنیک تشخیص چهره، مبتنی بر هارکساسکید (haar-cascade) است که در سال ۲۰۰۱ معرفی شد. این تکنیک از ویژگیهای مبتنی بر هار استفاده میکند تا چهرهها را از فریم تصویر ورودی تشخیص دهد. اما در استانداردهای امروزی، این تکنیک به دلیل دقت و عملکرد پایین در تشخیص و همچنین اشتباه در تشخیص الگوهای دیگر موجود در فریم برای چهرههای انسان، به عنوان یک روش کند شناخته میشود. همچنین، این تکنیک به شدت وابسته به شرایط نورپردازی است و در محیطهای کم نور به صورت نامناسب عمل میکند.

شکل ۱۸: تشخیص چهره در تصویر پیشپردازش شده
در حال حاضر، بسیاری از مدلهای مبتنی بر یادگیری عمیق در فرآیند تشخیص چهره کمک میکنند. MTCNN در سال ۲۰۱۶ معرفی شد و از ساختار کاسکاد به همراه سه مرحله شبکه عصبی پیچشی بهره میبرد. همچنین، در OpenCV یک تشخیص دهنده چهره مبتنی بر شبکه عصبی عمیق وجود دارد. این تشخیص دهنده از یک مدل Caffe مبتنی بر معماری SSD استفاده میکند و شبکه ResNet-10 را به عنوان اسکلت خود دارد. بیشتر مدلهای مبتنی بر یادگیری عمیق همچنین از تشخیص چند چهره از یک فریم ورودی پشتیبانی میکنند و در نهایت یک جعبه محدود کننده (bounding box) دور چهره تشخیص داده شده رسم میشود. یک نمونه مناسب از این فرآیند در شکل ۱۸ نشان داده شده است.

شکل ۱۹: تبدیل جهت چهره
استنتاج:
در حوزه یادگیری ماشین، استنتاج به معنی استفاده از یک مدل آموزش دیده شده برای پیشبینی خروجی مربوط به ورودی جدید است. به طور کلی، در فرآیند آموزش یک مدل، از دادههای آموزشی برای بهبود عملکرد و دقت آن استفاده میشود. بعد از آموزش، مدل میتواند بر روی دادههای جدید ورودی به کار رود و خروجی از آن استخراج شود. این فرآیند استفاده از مدل برای پیشبینی خروجی جدید، به عنوان استنتاج یا نتیجهگیری شناخته میشود.

شکل ۲۰: استنتاج شناسایی چهره در ویدیو
در تصویر ویدیویی فوق، مشاهده میشود که چهره در فریم تشخیص داده شده و مدل با موفقیت فرد را به عنوان الون ماسک شناسایی کرده است.
استقرار(نصب و راه اندازی سیستم بروی سرور):
برای انجام استنتاج، ابتدا باید مدل را بر روی یک پلتفرم استقرار( نصب و راه اندازی) کرد. در ادامه، به برخی از گزینههای شناخته شده برای استقرار مدلها میپردازیم:
استقرار محلی(نصب و راه اندازی سیستم بروی سرورمحلی)
در این روش، مدل یادگیری ماشین بر روی یک دستگاه محلی یا سرور اختصاصی استقرار مییابد و در برنامه یا سیستمی که قرار است از آن استفاده شود، یکپارچه میشود. این روش برای برنامههایی با نیازمندیهای زمان پاسخگویی کم یا هنگامی که مدل نیاز به دسترسی به منابع محلی مانند پردازشگر گرافیکی (GPU) دارد، مناسب است.
استقرار ابری(نصب و راه اندازی سیستم بروی سرورابری)
پلتفرمهای ابری، زیرساخت و خدماتی را برای استقرار مدلهای سفارشی فراهم میکنند. در این روش، مدل بر روی یک سرویس ابری مانند Amazon Web Services، Google Cloud Platform (GCP) یا Microsoft Azure آپلود میشود که مدیریت استقرار و مقیاسپذیری آن را بر عهده دارد. استقرار ابری، انعطافپذیری، مقیاسپذیری و آسانی ادغام با سایر خدمات ابری را فراهم میکند.
استقرار لبه (نصب و راه اندازی مدل بصورت محلی است و بدون نیاز به ارتباط با سرور ابری پردازش داده ها انجام میشود
استقرار لبه شامل نصب مدل مستقیماً بر روی دستگاههای لبه مانند تلفنهای هوشمند، دستگاههای IoT یا سرورهای لبه است. در این روش امکان پردازش در لحظه وجود دارد و نیاز به انتقال دادهها به صورت مداوم به سرور ابری را کاهش میدهد. استقرار لبه برای برنامههایی با نیازمندیهای لاتانس کم یا هنگامی که حریم شخصی دادهها و محدودیت پهنای باند مهم است، مناسب است. یکی از معایب این روش کاهش دقت پیشبینی و کندی عملکرد است.
نتیجه گیری
مدل های یادگیری عمیق حوزه تشخیص چهره را بهطور چشمگیری تحول دادهاند و نتایج قابل توجهی در دقت و قابلیت اطمینان حاصل شده است. شبکههای عصبی پیچشی (CNN) به عنوان ساختار اصلی برای کارهای پردازش تصویر ظاهر شدند که امکان یادگیری ویژگیهای متمایزکننده را مستقیماً از دادههای پیکسلی فراهم میکنند. مدلهایی مانند DeepFace، FaceNet و ArcFace، عملکرد برتر را به نمایش گذاشتهاند و راه را برای دستاوردهای بیشتر در این حوزه باز کردهاند.
توسعه ابزارهای آماده استفاده مانند DeepFace، TFace و InSightFace، در پیشرفت پذیری گسترده این تکنولوژی نقش بسیار مهمی داشتهاند. موفقیت تشخیص چهره مبتنی بر یادگیری عمیق بیشتر به دسترسی به مجموعه دادههای متنوع و بزرگ مرتبط است
مجموعه داده (دیتاست )هایی مانند LFW، IMDB-Wiki و MS-Celeb-1M، منابع ارزشمندی برای آموزش و ارزیابی مدلهای تشخیص چهره برای محققان و عملگران فراهم کردهاند. این مجموعه داده(دیتاست)ها شامل مجموعهای گسترده از تغییرات در زاویه دید، شرایط نورپردازی، عبارات چهره و هویتهای مختلف است که به مدلها امکان تعمیم و استفاده در شرایط مختلف را میدهد.
رفرنس ها
Advancements in Face Recognition Models, Toolkit and Datasets
با بررسی این منابع، به طور قابل توجهی دانش خود درباره تشخیص چهره را گسترش خواهید داد. لذا اطمینان حاصل کنید که آنها را نادیده نمیگیرید. برای دسترسی آسان، در نظر داشته باشید که این صفحه را به عنوان نشانی (Bookmark) ذخیره کنید. در و مهارتهای خود را به سطح بعدی ارتقا دهید!
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

دیدگاهتان را بنویسید