هوش مصنوعی، یادگیری ماشین، یادگیری عمیق و شبکههای عصبی: تفاوت آنها در چیست؟

هوش مصنوعی (AI)، یادگیری ماشین (ML) و دیپ لرنینگ (DeepLearning)
این اصطلاحات در علوم کامپیوتر اغلب به جای هم استفاده میشوند، اما چه تفاوتهایی بین آنها وجود دارد؟
در عصر حاضر، فناوری لحظه به لحظه در زندگی روزمرهی ما بیشتر نمود پیدا میکند و در همه ابعاد زندگی ما دیده میشود. برای همگام شدن با سرعت انتظارات مصرفکنندگان، شرکتها امروزه بیشتر به الگوریتمهای یادگیری ماشین تکیه میکنند تا کارها را آسانتر انجام دهند. میتوانید کاربرد آنها را در شبکههای اجتماعی (از طریق تشخیص اشیا در عکسها) یا در مکالمهی مستقیم با دستگاههای شخصی (مانند Alexa یا Siri) ببینید.
در حالی که هوش مصنوعی (Artificial Intelligence) یا AI، یادگیری ماشین (Machine Leaning) یا ML، یادگیری عمیق (Deep Learning) و شبکههای عصبی (Neural Networks) فناوریهای مرتبط هستند، این اصطلاحات اغلب به جای هم استفاده میشوند، که منجر به سردرگمی در مورد تفاوتهای آنها میشود. این پست برخی از ابهامات را روشن خواهد کرد.
هوش مصنوعی، یادگیری ماشین، یادگیری عمیق و شبکههای عصبی چگونه با یکدیگر ارتباط دارند؟
سادهترین راه برای فکر کردن در مورد هوش مصنوعی، یادگیری ماشین، یادگیری عمیق یا همان ذیپ لرنینگ و شبکه های عصبی این است که آنها را به عنوان زیرمجموعههایی از هوش مصنوعی مرتبشده از بزرگترین تا کوچکترین در نظر بگیرید که هر کدام سیستمهای بعدی را دربر میگیرند.
هوش مصنوعی سیستمی فراگیر است. یادگیری ماشین زیر مجموعهای از هوش مصنوعی است. یادگیری عمیق زیر شاخهای از یادگیری ماشین است و شبکههای عصبی ستون فقرات الگوریتمهای یادگیری عمیق را تشکیل میدهند. تعداد لایههای گره یا عمق شبکههای عصبی است که یک شبکه عصبی ساده را از یک الگوریتم یادگیری عمیق متمایز میکند (برای قرار گرفتن در دستهی یادگیری عمیق، این شبکهها باید بیش از سه لایه داشته باشند).
هوش مصنوعی چیست؟
هوش مصنوعی یا AI، گستردهترین اصطلاح در این بین، برای طبقهبندی ماشینهایی استفاده میشود که هوش انسانی و عملکردهای شناختی انسان مانند حل مسئله و یادگیری را تقلید میکنند. هوش مصنوعی از پیشبینیها و اتوماسیون برای بهینهسازی و حل کارهای پیچیدهای که انسانها در طول تاریخ انجام دادهاند، مانند تشخیص چهره و گفتار، تصمیمگیری و ترجمه، استفاده میکند.
دستههای هوش مصنوعی
سه دستهی اصلی هوش مصنوعی عبارتند از:
- هوش ضعیف مصنوعی یا هوش مصنوعی محدود (Artificial Narrow Intelligence) یا ANI
- هوش مصنوعی عمومی (Artificial General Intelligence) یا AGI
- ابر هوش مصنوعی یا فراهوش (Arificial Super Intelligence) یا ASI
ANI هوش مصنوعی “محدود” یا “ضعیف” (Narrow یا weak) در نظر گرفته میشود، در حالی که دو نوع دیگر به عنوان هوش مصنوعی “قوی” یا “strong” طبقهبندی میشوند. ما هوش مصنوعی ضعیف را با توانایی آن در انجام یک کار خاص، مانند برنده شدن در یک بازی شطرنج یا شناسایی یک فرد خاص در یک سری عکس، تعریف میکنیم. پردازش زبان طبیعی (Natural Language Processing) یا NLP و بینایی ماشین (Computer Vision)، که به شرکتها اجازه میدهد وظایف را خودکار کنند و زیربنای چتباتها و دستیاران مجازی مانند Siri و Alexa را توسعه دهند، نمونههایی از ANI هستند. بینایی کامپیوتر، عاملی در توسعهی خودروهای خودران است.
انواع قویتر هوش مصنوعی، مانند AGI و ASI، رفتارهای انسانی را بهطور برجستهتری شامل میشوند، مانند توانایی تفسیر لحن و احساسات. هوش مصنوعی قوی با توانایی آن در مقایسه با انسان تعریف میشود. هوش مصنوعی عمومی (AGI) همتراز با انسان عمل میکند، در حالی که ابر هوش مصنوعی (ASI)، که به عنوان ابرهوش نیز شناخته میشود ، از هوش و توانایی یک انسان پیشی میگیرد. هیچکدام از این دو نوع هوش مصنوعی قوی هنوز وجود ندارد، اما تحقیقات در این زمینه ادامه دارد.
استفاده از هوش مصنوعی در کسبوکارها
تعداد فزایندهای از کسبوکارها، حدود ۳۵ درصد در سطح جهان، از هوش مصنوعی استفاده میکنند و ۴۲ درصد دیگر در حال بررسی این فناوری هستند. توسعهی هوش مصنوعی مولد، که از مدلهای پایهی قدرتمندی استفاده میکند که بر روی مقادیر زیادی از دادههای بدون برچسب آموزش میبینند، میتواند با موارد استفادهی جدید تطبیق داده شود و انعطافپذیری و مقیاسپذیری را به ارمغان بیاورد که احتمالاً پذیرش هوش مصنوعی را به میزان قابل توجهی تسریع میکند. در آزمایشهای اولیه، IBM شاهد بوده است که هوش مصنوعی مولد زمان را تا ۷۰ درصد سریعتر از هوش مصنوعی سنتی به ارزش میرساند.
چه از برنامههای هوش مصنوعی مبتنی بر مدلهای یادگیری ماشین استفاده کنید و چه از مدلهای پایه، هوش مصنوعی میتواند به کسبوکار شما مزیت رقابتی بدهد. ادغام مدلهای هوش مصنوعی سفارشیشده در جریانهای کاری و سیستمهای شما، و خودکارسازی عملکردهایی مانند خدمات مشتری، مدیریت زنجیره تامین و امنیت سایبری، میتواند به یک کسبوکار کمک کند تا انتظارات مشتریان را چه امروز و چه با افزایش آنها در آینده، برآورده کند.
نکته کلیدی این است که مجموعه دادههای مناسب را از ابتدا شناسایی کنید تا اطمینان حاصل کنید که از دادههای با کیفیت، برای دستیابی به بیشترین مزیت رقابتی استفاده میکنید. همچنین باید یک معماری ترکیبی و آماده برای هوش مصنوعی ایجاد کنید که بتواند با موفقیت از دادهها در هر کجا که زندگی میکنید استفاده کند – روی مینفریمها، مراکز داده، در ابرهای خصوصی و عمومی و در لبهها.
هوش مصنوعی شما باید قابل اعتماد باشد زیرا هر چیز کمتری به معنای آسیب رساندن به اعتبار یک شرکت و اعمال جریمههای قانونی است. مدلهای گمراهکننده و آنهایی که حاوی سوگیری یا توهم هستند، میتوانند هزینهی زیادی برای حریم خصوصی، حقوق دادهها و اعتماد مشتریان داشته باشند. هوش مصنوعی شما باید قابل توضیح، منصفانه و شفاف باشد.
یادگیری ماشین چیست؟
یادگیری ماشین زیرمجموعهای از هوش مصنوعی است که امکان بهینهسازی را فراهم میکند. هنگامی که به درستی تنظیم شود، به شما کمک میکند تا پیشبینیهایی انجام دهید که خطاهای ناشی از حدس زدن صرف را به حداقل میرساند. به عنوان مثال، شرکتهایی مانند آمازون از یادگیری ماشین برای توصیه محصولات به یک مشتری خاص بر اساس آنچه قبلاً به آن نگاه کرده و خریداری کرده است، استفاده میکنند.
یادگیری ماشین کلاسیک یا “غیر عمیق” به مداخلهی انسان بستگی دارد تا به سیستم کامپیوتری اجازه دهد الگوها را شناسایی کند، یاد بگیرد، وظایف خاص را انجام دهد و نتایج دقیق ارائه کند. متخصصان انسانی سلسلهمراتب ویژگیها را برای درک تفاوتهای بین ورودیهای داده تعیین میکنند و معمولاً برای یادگیری به دادههای ساختاریافته بیشتری نیاز دارند.
برای مثال، فرض کنید من مجموعهای از تصاویر انواع فستفود را به شما نشان دادم، «پیتزا»، «برگر» و «تاکو». یک متخصص انسانی که روی این تصاویر کار میکند، ویژگیهایی را که هر تصویر را به عنوان یک نوع فستفود خاص متمایز میکند، تعیین میکند. نان در هر نوع غذایی ممکن است یک ویژگی متمایز باشد. از طرف دیگر، ممکن است از برچسبهایی مانند «پیتزا»، «برگر» یا «تاکو» برای سادهسازی فرآیند یادگیری از طریق یادگیری نظارتشده استفاده کنند.
در حالی که زیرمجموعهای از هوش مصنوعی به نام یادگیری ماشین عمیق میتواند از مجموعه دادههای برچسبگذاریشده برای آموزش الگوریتم خود در یادگیری نظارتشده استفاده کند، لزوماً به یک مجموعه داده برچسبدار نیاز ندارد. میتواند دادههای بدون ساختار را به شکل خام (مثلاً متن، تصاویر) دریافت کند و بهطور خودکار مجموعهای از ویژگیهایی را تعیین کند که «پیتزا»، «برگر» و «تاکو» را از یکدیگر متمایز میکند. همانطور که دادههای بزرگ بیشتری تولید میکنیم، دانشمندان داده از یادگیری ماشین بیشتری استفاده خواهند کرد. برای بررسی عمیقتر تفاوتهای بین این رویکردها، یادگیری نظارتشده، یادگیری بدون ناظر: تفاوت چیست؟ را بررسی کنید.
دستهی سوم از یادگیری ماشین، یادگیری تقویتی (Reinforcement Learning) است، که در آن کامپیوتر با تعامل با محیط اطراف خود و دریافت بازخورد (پاداش یا جریمه) برای اقدامات خود، یاد میگیرد. یادگیری آنلاین (Online Learning) هم نوعی یادگیری ماشین است که در آن یک دانشمند داده، مدل ML را با در دسترس قرار گرفتن دادههای جدید، بهروز میکند.
برای کسب اطلاعات بیشتر در مورد یادگیری ماشین، ویدیوی زیر را ببینید:
یادگیری عمیق چه تفاوتی با یادگیری ماشین دارد؟
همانطور که مقالهی یادگیری عمیق توضیح میدهد، یادگیری عمیق زیر مجموعهای از یادگیری ماشین است. تفاوت اصلی بین یادگیری ماشین و یادگیری عمیق این است که هر نوع الگوریتم چگونه یاد میگیرد و چقدر داده استفاده میکند.
یادگیری عمیق بیشتر فرایند استخراج ویژگی را خودکار میکند و نیاز به برخی از مداخلات دستی انسان را حذف میکند. همچنین امکان استفاده از مجموعهدادههای بزرگ را فراهم میکند و عنوان یادگیری ماشین مقیاسپذیر را به خود اختصاص میدهد. این قابلیت بسیار هیجانانگیز است؛ چرا که ما را قادر میسازد تا استفادهی بیشتری از دادههای بدون ساختار داشته باشیم، به ویژه این که تخمین زده میشود بیش از ۸۰٪ از دادههای یک سازمان بدون ساختار هستند.
مشاهده الگوها در دادهها به یک مدل یادگیری عمیق اجازه میدهد تا ورودیها را به طور مناسب خوشهبندی کند. با در نظر گرفتن همان مثال قبلی، میتوانیم تصاویر پیتزا، همبرگر و تاکو را بر اساس شباهتها یا تفاوتهای مشخصشده در تصاویر در دستههای مربوطه گروهبندی کنیم. یک مدل یادگیری عمیق به نقاط دادهی بیشتری برای بهبود دقت نیاز دارد، در حالی که یک مدل یادگیری ماشین با توجه به ساختار دادهی زیربنایی خود، به دادههای کمتری متکی است. شرکتها معمولاً از یادگیری عمیق برای کارهای پیچیدهتر مانند دستیاران مجازی یا کشف تقلب استفاده میکنند.
شبکهی عصبی چیست؟
شبکههای عصبی که شبکههای عصبی مصنوعی (Artificial Neural Networks یا ANN) یا شبکههای عصبی شبیهسازیشده (Simulated Neural Networks یا SNN) نیز نامیده میشوند، زیرمجموعهای از یادگیری ماشین و ستون فقرات الگوریتمهای یادگیری عمیق هستند. آنها را “عصبی” مینامند چرا که نحوهی سیگنالدهی نورونهای مغز به یکدیگر را تقلید میکنند.
شبکههای عصبی از لایههای ساختهشده از گرهها، یک لایهی ورودی، یک یا چند لایهی پنهان و یک لایه خروجی تشکیل شدهاند. هر گره یک نورون مصنوعی است که به گره بعدی متصل میشود و هر گره دارای وزن و مقدار آستانه است. هنگامی که خروجی یک گره بالاتر از مقدار آستانه باشد، آن گره فعال میشود و دادههای خود را به لایهی بعدی شبکه میفرستد. اگر زیر آستانه باشد، هیچ دادهای از آن عبور نمیکند.
دادههای آموزشی شبکههای عصبی را آموزش میدهند و به بهبود دقت آنها در طول زمان کمک میکنند. هنگامی که الگوریتمهای یادگیری دقیق تنظیم شوند، به ابزارهای قدرتمند علوم کامپیوتر و هوش مصنوعی تبدیل میشوند و به ما این امکان را میدهند تا خیلی سریع دادهها را طبقهبندی و خوشهبندی کنیم. با استفاده از شبکههای عصبی، وظایف تشخیص گفتار و تصویر به جای ساعتهایی که به صورت دستی زمان میبرند، میتوانند در چند دقیقه انجام شوند. الگوریتم جستجوی گوگل یک نمونهی شناخته شده از شبکهی عصبی است.
تفاوت یادگیری عمیق و شبکهی عصبی چیست؟
همانطور که در توضیح شبکههای عصبی در بالا ذکر شد، اما اشکالی در بیان واضحتر آن وجود ندارد، “عمیق” در یادگیری عمیق به عمق لایهها در یک شبکهی عصبی اشاره دارد. یک شبکهی عصبی با بیش از سه لایه شامل ورودی و خروجی را میتوان یک الگوریتم یادگیری عمیق در نظر گرفت؛ که میتواند با شکل زیر نشان داده شود:
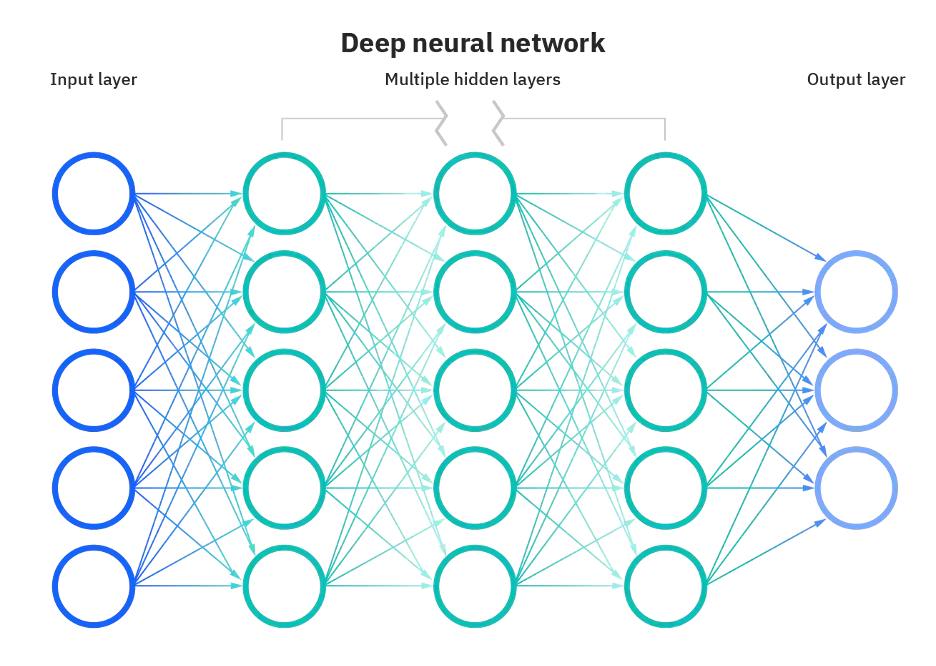
بیشتر شبکههای عصبی عمیق از نوع Feed-Forward هستند، به این معنی که فقط یک جریان و آن هم در جهت ورودی به سمت خروجی دارند. با این حال، شما میتوانید مدل خود را از طریق الگوریتم پسانتشار یا backpropagation، به معنای حرکت در جهت مخالف، از خروجی به ورودی، آموزش دهید. الگوریتم پسانتشار به ما این اجازه را میدهد تا خطای مربوط به هر نورون را محاسبه و نسبت دهیم و الگوریتم را به طور مناسب تنظیم و برازش کنیم.
مدیریت دادههای هوش مصنوعی
در حالی که همهی حوزههای هوش مصنوعی میتوانند به سادهسازی کسبوکار شما و بهبود تجربهی مشتری کمک کنند، دستیابی به اهداف هوش مصنوعی میتواند چالشبرانگیز باشد؛ چرا که ابتدا باید مطمئن شوید که سیستمهای مناسبی برای ایجاد الگوریتمهای یادگیری و مدیریت دادههای خود در دست دارید. مدیریت داده بیش از ساختن مدلهایی است که برای کسبوکار خود استفاده میکنید. قبل از اینکه بتوانید شروع به ساختن هر چیزی کنید، به مکانی برای ذخیرهی دادهها و مکانیسمهایی برای پاکسازی و کنترل سوگیریها نیاز دارید.
منبع:
AI vs. Machine Learning vs. Deep Learning vs. Neural Networks: What’s the difference?
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

دیدگاهتان را بنویسید