یادگیری متضاد یا مقایسهای (Contrastive Learning) – SimCLR و BYOL

یادگیری نیمهنظارتی یا Semi-supervised learning
در یادگیری ماشین (Machine Learning)، روش یادگیری نظارتشده (Supervised Learning) سالها روش غالب بوده است، اما وابستگی آن به دادههای برچسبدار یا Labeled Data که جمعآوری آنها پرهزینه و زمانبر است، چالشهایی ایجاد میکند؛ بهویژه در حوزههای تخصصی مانند تصویربرداری پزشکی. از سوی دیگر، یادگیری بدون نظارت (Unsupervised Learning) هرچند مقیاسپذیر است، فاقد ساختار کافی برای دستیابی به عملکرد بالا میباشد. Contrastive Learning این فاصله را پر میکند و با یادگیری بازنمایی (Representation)های معنادار بدون نیاز به برچسبهای صریح، به مدلها امکان میدهد شباهتها و تفاوتها را تشخیص دهند؛ مانند تمایز بین عکسهای گربه و ماشین با گروهبندی آیتمهای مشابه در یک فضای تعبیه یا امبدینگ (Embedding).
Contrastive Learning در حوزه یادگیری خودنظارتشده (Self-Supervised Learning) بسیار مؤثر است، جایی که مدلها سیگنالهای نظارتی خود را از دادههای بدون برچسب تولید میکنند. رویکردهای مدرن اغلب عناصر خودنظارتشده (Self-Supervised) و نظارتشده (Supervised) را ترکیب میکنند؛ به این صورت که بازنمایی های یادگرفتهشده را با دادههای برچسبدار انسانی بهبود میبخشند و چارچوبی نیمهنظارتشده (Semi-Supervised) ایجاد میکنند. این روش به محققان امکان میدهد با دادههای بزرگ و بدون برچسب Pre-train کنند و سپس روی مجموعه دادههای کوچک و برچسبدار Fine-Tune انجام دهند. به این ترتیب، مقیاسپذیری یادگیری بدون نظارت با دقت روشهای نظارتشده ترکیب میشود. نتیجه آن است که Contrastive Learning به ابزاری قدرتمند برای غلبه بر محدودیتهای روشهای سنتی تبدیل شده است.
در این مقاله که به مفهوم کلی Contrastive Learning اختصاص دارد، ابتدا یک تعریف مختصر از آن ارائه میکنیم و سپس تمامی اصطلاحات فنی غیرعمومی را توضیح خواهیم داد.
Contrastive Learning
Contrastive Learning یک تکنیک خودنظارتشده (Self-Supervised) است که به مدلها امکان میدهد بازنماییهایی را از دادههای بدون برچسب یاد بگیرند. به جای تکیه بر برچسبها، این روش بر Pretraining متمرکز است و از یک انکودر (Encoder) برای استخراج ویژگیهای معنادار استفاده میکند. این بازنماییهای یادگرفتهشده در وظایف پاییندستی (Downstream Tasks) مانند طبقهبندی (Classification)، تشخیص اشیا (Object Detection) یا بخشبندی (Segmentation) که برچسبها در دسترس هستند، به کار گرفته میشوند.
ایده اصلی بسیار ساده است:
- نزدیک کردن جفتهای مثبت: آیتمهایی که از نظر معنایی مشابه هستند (مانند دو نمای مختلف از یک شیء) باید در فضای جاسازی (Embedding) به هم نزدیک باشند.
- دور کردن جفتهای منفی: آیتمهایی که از نظر معنایی متفاوت هستند (مانند نمایی از دو شیء متفاوت) باید در فضای جاسازی از هم دور باشند.
برای درک بهتر، بیایید به یک مثال نگاه کنیم:
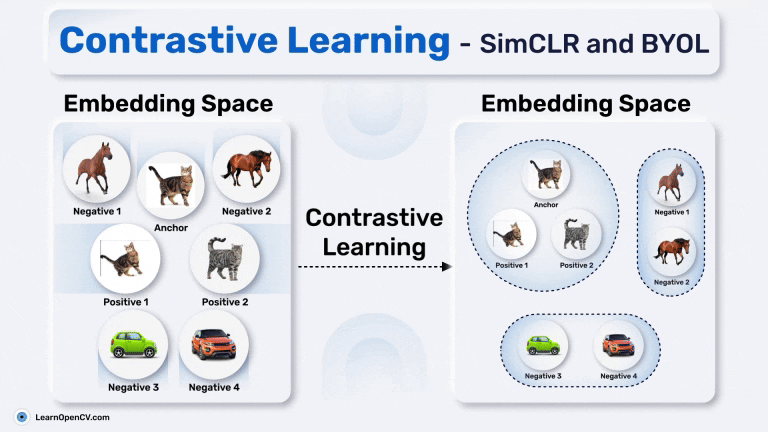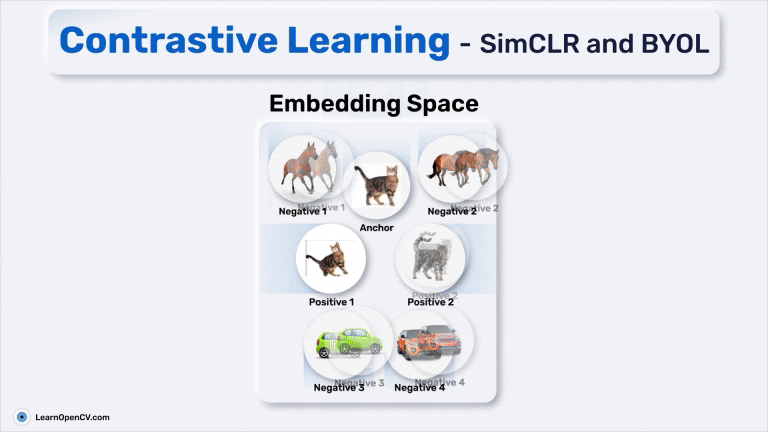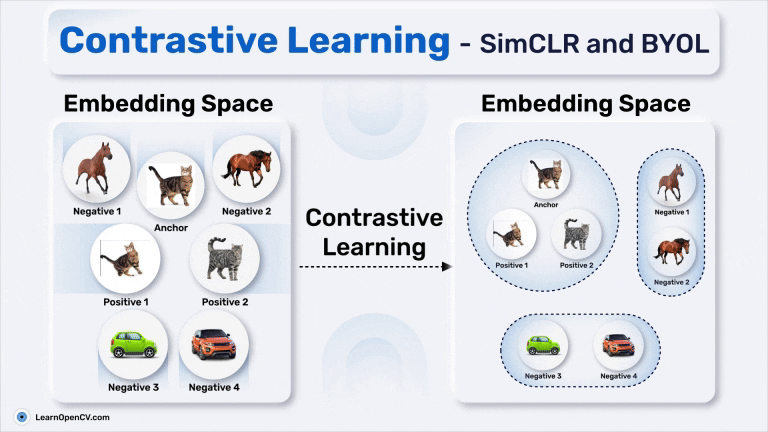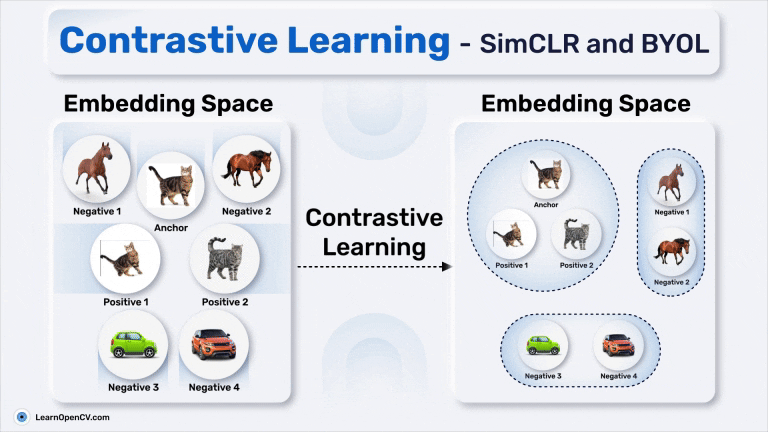
Anchor، Positive Pair و Negative Pair در Contrastive Learning
- Anchor: تصویر ورودی، مانند عکس یک گربه.
- Positive Pair: تصویری که از نظر معنایی مشابه تصویر اصلی است (مانند نمایی تغییرشکلیافته از همان گربه یا عکس دیگری از همان کلاس که گربه به آن تعلق دارد).
- Negative Pair: تصویری که از نظر معنایی متفاوت است (مانند عکس یک ماشین یا اسب).
در Contrastive Learning، مدل یاد میگیرد که جفتهای مثبت را به Anchor نزدیکتر کند و جفتهای منفی را از آن دورتر سازد. این فرآیند منجر به ایجاد یک فضای تعبیه (Embedding Space) با ساختار مناسب میشود که در آن آیتمهای مشابه در کنار یکدیگر خوشهبندی شده و آیتمهای متفاوت از هم جدا میشوند. این ویژگی، Contrastive Learning را به ابزاری اساسی برای Pretraining در یادگیری ماشین تبدیل میکند و راه را برای وظایفی هموار میسازد که دادههای برچسبدار کمیاب هستند اما نیاز به بازنماییهای دقیق دارند.
تولید جفتهای مثبت و منفی
- جفتهای مثبت معمولاً با اعمال تغییراتی (مانند برش، چرخش) روی یک داده واحد ایجاد میشوند.
- جفتهای منفی، بازنماییهای (Representations) تمامی نقاط داده دیگر موجود در دسته (Batch) یا مجموعه داده (Dataset) هستند، بهجز بازنماییهایی که در جفت مثبت موردنظر قرار دارند.
تابع هزینه در Contrastive Learning
یک تابع هزینه Contrastive (Contrastive Loss) برای اطمینان از نزدیک بودن بازنماییهای جفتهای مثبت و دور بودن بازنماییهای جفتهای منفی استفاده میشود. این تابع بهصراحت فاصله بین جفتهای مثبت و منفی را محاسبه کرده و بر اساس شباهت آنها جریمه میکند.
- Triplet Loss: این تابع فاصله بین Anchor و مثبت را حداقل و فاصله بین Anchor و منفی را حداکثر میکند.
- NT-Xent Loss (Normalized Temperature-Scaled Cross-Entropy Loss): که در SimCLR استفاده میشود، از Cosine Similarity بهره میگیرد و با استفاده از دمای مقیاسشده، مقادیر را به محدوده معناداری تنظیم میکند. این کار باعث بهینهسازی هماهنگی و جداسازی بازنماییها میشود.
Contrastive Learning با ترکیب این مفاهیم، مدلی مقیاسپذیر و دقیق برای استخراج بازنماییهای معنادار ارائه میدهد.
برخی از تکنولوژیهای محبوبی که از Contrastive Learning استفاده میکنند:
- SimCLR, MoCo, BYOL و غیره (بینایی کامپیوتری – Computer Vision).
- CLIP و ALIGN (یادگیری میانوجهی – Cross-Modal Learning).
- Sentence-BERT (پردازش زبان طبیعی – NLP).
- اسپاتیفای (Spotify) و پینترست (Pinterest) (سیستمهای توصیه مبتنی بر جلسه – Session-Based Recommendation Systems).
- تسلا اتوپایلوت (Tesla Autopilot) (درک صحنه و تشخیص اشیا – Scene Understanding and Object Detection).
- Wav2Vec (پردازش گفتار – Speech Processing)
ریشههای Contrastive Learning: سفری در طول زمان
پایههای اولیه: الگوریتم Contrastive Divergence (سال 2002)
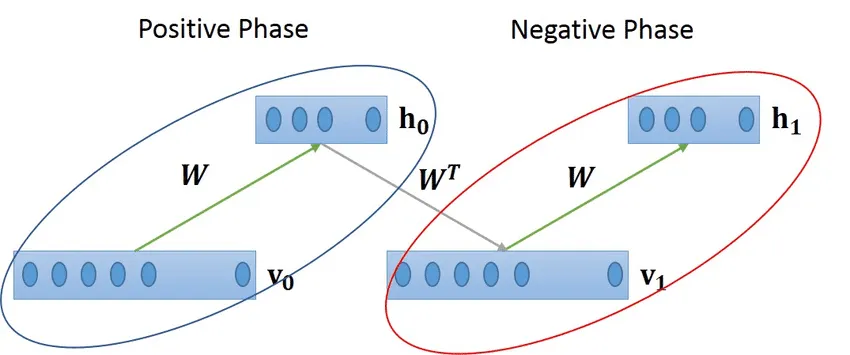
ریشههای Contrastive Learning به سال 2002 و الگوریتم Contrastive Divergence (CD) معرفیشده توسط Geoffrey Hinton بازمیگردد. CD که برای Pretraining شبکههای عمیق و ماشین بولتزمن محدود (Restricted Boltzmann Machines – RBMs) توسعه داده شد، رویکردی نوآورانه ارائه کرد:
- مرحله مثبت (Positive Phase): تمرکز بر دادههای واقعی و مشاهدهشده.
- مرحله منفی (Negative Phase): مقایسه با دادههایی که توسط خود مدل تولید شدهاند.
هرچند CD بر روی کمینهسازی تفاوت انرژی در مدلهای مولد تمرکز داشت، ایده اصلی آن در مورد تضاد دادهها، پایهای برای روشهای مدرن یادگیری بازنمایی فراهم کرد.
Word2Vec و بازنماییهای اولیه (2013)
در سال 2013، Word2Vec با معرفی Skip-gram Negative Sampling تحولی ایجاد کرد که در آن:
- نمونههای مثبت (Positive Samples): کلمات واقعی و مرتبط با زمینه بودند.
- نمونههای منفی (Negative Samples): کلمات تصادفی بودند.
هرچند Word2Vec بهصراحت Contrastive Learning نامیده نشد، این روش تکنیکهای مدرن را با موارد زیر الهام بخشید:
- معرفی Negative Sampling برای تمایز بین جفتهای مثبت و منفی.
- تعمیم Dense Embeddings – که از بازنمایی کلمات به تصاویر، ویدئوها و موارد دیگر گسترش یافت.
- استفاده از دادههای بدون برچسب، مشابه روشهای خودنظارتشده مدرن.
روشهای Contrastive Learning مدرن (2018-2020)
این تکنیک با روشهایی مانند:
- SimCLR (2020): این فریمورک که توسط محققان Google Brain منتشر شد، Contrastive Learning مدرن را برای یادگیری بازنماییهای بدون نظارت (Unsupervised Representation Learning) بر روی تصاویر تعریف کرد.
- MoCo (2019): Momentum Contrast از Facebook AI.
این روشها اصطلاح Contrastive Learning را در معنای فعلی آن تثبیت کردند، که بر یادگیری بازنماییها از طریق مقایسه جفتهای مثبت و منفی تمرکز دارد. Contrastive Learning بهعنوان یک تکنیک خاص برای یادگیری بازنماییها، بین سالهای 2018 تا 2020 با مدلهایی مانند SimCLR و MoCo به محبوبیت رسید.
اولین استفاده برجسته از Contrastive Learning در حوزه بینایی کامپیوتری (Computer Vision) در مقاله “Unsupervised Feature Learning via Non-Parametric Instance Discrimination” توسط Wu و همکاران در Facebook AI Research (FAIR) نشان داده شد. در این مقاله، Instance Discrimination بهعنوان یک وظیفه معرفی شد، جایی که هر تصویر بهعنوان کلاس خودش در نظر گرفته میشد و تغییرات تصویر مشابه با دیگر تصاویر مقایسه میشد. این مقاله پیشدرآمدی برای فریمورکهای مدرن مانند SimCLR و MoCo بود.
در ادامه، محدودیتهای Contrastive Learning مدرن را بررسی خواهیم کرد. برخی از این محدودیتها حل شدهاند، اما برخی دیگر همچنان موضوعات تحقیقاتی باز هستند. سپس به بررسی SimCLR، فریمورکی که Contrastive Learning مدرن را محبوب کرد، خواهیم پرداخت و به معرفی BYOL، یک رویکرد پیشرفتهتر و بهینهشده، خواهیم پرداخت که شامل کد پیادهسازی آن میشود.
با وجود قابلیتها و پیشرفتهای قابلتوجه Contrastive Learning مدرن، این تکنیک همچنان با برخی محدودیتها مواجه است. بسیاری از این محدودیتها با راهحلهای جزئی برطرف شدهاند یا همچنان بهعنوان موضوعات تحقیقاتی فعال باقی ماندهاند. در زیر توضیحات دقیقی در مورد این محدودیتها و چگونگی برخورد محققان با آنها ارائه شده است.
محدودیتها و تحقیقهای جاری در Contrastive Learning
Contrastive Learning تحول بزرگی در یادگیری خودنظارتی بازنماییها ایجاد کرده است، اما مانند هر رویکرد دیگری، با چالشهایی مواجه است. این محدودیتها باعث ایجاد نوآوریها و تحقیقات جاری برای بهبود کارایی و مقیاسپذیری آن شدهاند.
وابستگی به نمونههای منفی
Contrastive Learning مدرن به شدت به نمونههای منفی برای مقایسه با جفتهای مثبت وابسته است، اما این امر با چالشهایی همراه است. نمونهبرداری از نمونههای منفی کافی و معنادار در مجموعه دادههای بزرگ نیاز به منابع محاسباتی زیادی دارد و نمونههای منفی اشتباه—جایی که اقلام مشابه از نظر معنایی بهعنوان نامشابه در نظر گرفته میشوند—میتوانند نویز ایجاد کنند.
برای حل این مشکل، روشهایی مانند BYOL (Bootstrap Your Own Latent) نیازی به نمونههای منفی ندارند و تنها بر روی جفتهای مثبت تمرکز میکنند و از یک momentum encoder برای ثبات بازنمایی استفاده میکنند. بهطور مشابه، Barlow Twins از نمونههای منفی اجتناب میکند و ویژگیها را در بازنماییها از هم تفکیک میکند.
هزینههای بالای محاسباتی و حافظه
روشهایی مانند SimCLR به اندازههای بزرگ دسته نیاز دارند تا نمونههای منفی کافی جمعآوری شود، که این امر منابع زیادی میطلبد و آموزش آنها را بر روی دستگاههای کوچکتر دشوار میسازد. MoCo (Momentum Contrast) راهحلی با معرفی یک صف حافظه ارائه میدهد که بازنماییهای دستههای قبلی را دوباره استفاده میکند و نیاز به اندازههای بزرگ دسته را کاهش میدهد. علاوه بر این، تکنیکهای distillation اجازه میدهند که دانش از مدلهای بزرگتر به مدلهای کوچکتر و سبکتر منتقل شود که راحتتر قابل پیادهسازی هستند.
کمبود درک معنایی
Contrastive Learning اغلب هر نقطه داده را بهعنوان یک کلاس منحصربهفرد در نظر میگیرد و بر تمایز سطح نمونهها تمرکز میکند تا گروهبندی معنایی سطح بالا (مثلاً خوشهبندی گربهها) را. این میتواند محدودیتهایی در تعمیمپذیری آن به وظایفی که نیاز به درک معنایی دارند ایجاد کند.
روشهایی مانند Prototypical Contrastive Learning (PCL) و Contrastive Clustering بهدنبال غلبه بر این محدودیت با گروهبندی نمونههای مشابه در خوشهها هستند و این امکان را به مدل میدهند که روابط معنایی را بهتر درک کند.
حساسیت به تعصب دادهها
تعصبات در مجموعههای داده آموزشی میتوانند منجر به بازنماییهای نامتوازن در مدلهای Contrastive Learning شوند. برای مثال، اگر مجموعه دادهای بیشتر تصاویری از کلاسهای خاص (مثلاً گربهها نسبت به سگها) داشته باشد، مدل ممکن است این الگوهای غالب را بیش از حد تطبیق دهد، حتی ممکن است روی تعصبات ناشی از تغییرات (augmentation) نیز بیش از حد تطبیق دهد.
برای مقابله با این مشکل، Contrastive Learning بدون تعصب از تکنیکهایی مانند hard negative mining برای تضمین تنوع استفاده میکند، در حالی که پیشپردازش دادهها برای متوازن کردن توزیع کلاسها انجام میشود.
مقیاسپذیری به دادههای چندوجهی
گسترش Contrastive Learning به وظایف چندوجهی مانند همراستاسازی ویدیو، متن و صدا به طور ذاتی چالشبرانگیز است و نیاز به مجموعه دادههای مقیاس بزرگ و معماریهای پیچیده دارد. فریمورکهایی مانند CLIP و ALIGN با همراستاسازی بازنماییها در میان متن و تصاویر پیشرفتهایی داشتهاند. این روشها پتانسیل Contrastive Learning چندوجهی را از طریق آموزش مشترک و نمونههای منفی به دقت انتخابشده نشان میدهند.
حساسیت بیش از حد به نمونههای منفی سخت
در حالی که نمونههای منفی سخت—جفتهایی که از نظر بصری یا معنایی مشابه مثبتها هستند—میتوانند یادگیری را غنیتر کنند، اما همچنین خطر بیثباتی آموزش را به همراه دارند. بهعنوان مثال، تمایز بین نژادهای مشابه سگ ممکن است مدل را گیج کند.
راهحلهای تطبیقی مانند hard-negative mining نمونههای چالشبرانگیز را بهطور استراتژیک انتخاب میکنند، در حالی که توابع هزینه تطبیقی اهمیت این نمونههای منفی را تعدیل کرده و فرآیند آموزش را بدون قربانی کردن یادگیری دقیقتر پایدار میکنند.
جدول 1. محدودیتها در Contrastive Learning مدرن
| محدودیتها | راهحلها و تحقیقات جاری | هدفها |
|---|---|---|
| وابستگی به نمونههای منفی | BYOL، Barlow Twins | سادهسازی فرآیند آموزش |
| نیازهای محاسباتی و حافظه | MoCo، Distillation | کاهش استفاده از حافظه |
| کمبود درک معنایی | رویکردهای ترکیبی، PCL | عملکرد بهتر برای وظایف خاص |
| تعصب در مجموعه دادهها | یادگیری بدون تعصب، مجموعه دادههای متوازن | کاهش تعصب |
| مقیاسپذیری چندوجهی | CLIP، ALIGN | گسترش به وظایف چندوجهی |
| حساسیت به نمونههای منفی سخت | Curriculum Learning، توابع هزینه تطبیقی | بهبود دینامیکهای آموزش |
نقاط عطف اصلی در تکامل فریمورکهای Contrastive Learning
قبل از بررسی SimCLR، نیاز است کمی بیشتر در مورد تکنولوژیها و تکاملاتی که به توسعه SimCLR منجر شدهاند، بدانیم.
قبل از MoCo (Momentum Contrast) و SimCLR، چندین فریمورک بنیادی دیگر زمینهسازی برای Contrastive Learning را انجام دادند، اما این فریمورکها به اندازه کافی مقیاسپذیر یا کارآمد نبودند. بیایید تکامل فریمورکهای Contrastive Learning و تحولات کلیدی که به MoCo منجر شد را بررسی کنیم.
جدول 2. تکامل Contrastive Learning
| سال | فریمورک | مهمترین ویژگی |
|---|---|---|
| 2018 | Non-Parametric Instance-level Discrimination | اولین فریمورک برای در نظر گرفتن هر تصویر به عنوان یک کلاس منحصر به فرد با استفاده از Contrastive Learning. معرفی بانک حافظه. |
| 2018 | Contrastive Predictive Coding (CPC) | استفاده از Contrastive Loss برای پیشبینی حالات نهفته آینده در دنبالهها. |
| 2019 | PIRL | یادگیری نمایشهای ثابت در برابر پیشزمینه با استفاده از Contrastive Learning. |
| 2020 | MoCo | حل مشکل بانک حافظه قدیمی با استفاده از یک Momentum Encoder و یک صف پویا. |
یک ماه پس از انتشار MoCo، SimCLR معرفی شد.
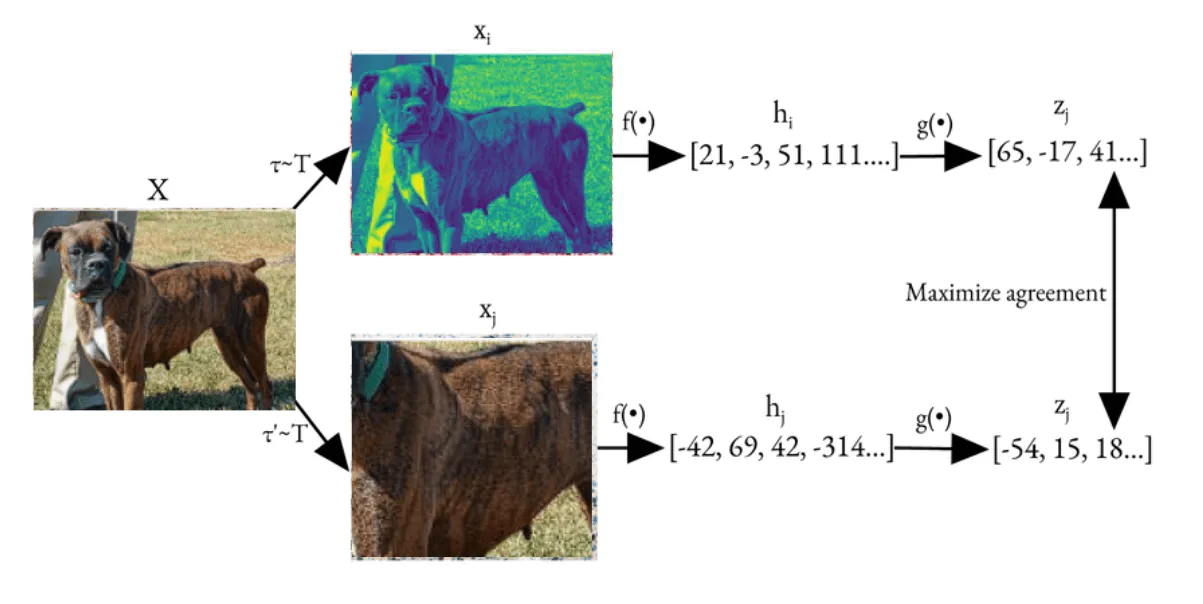
روند آموزش SimCLR
1. تصاویر ورودی را به دو نسخه  و
و  افزایش دهید.
افزایش دهید.
2. هر دو دیدگاه را با استفاده از **ResNet encoder** رمزگذاری کرده و به  و
و  دست پیدا کنید.
دست پیدا کنید.
3. نمایشهای رمزگذاریشده را از طریق **projection head** عبور دهید تا به  و
و  برسید.
برسید.
4. **NT-Xent loss** را بر روی تمامی جفتها (مثبت و منفی) محاسبه کنید.
5. گرادیانها را پسانتشار دهید و پارامترها را با استفاده از LARS Optimizer بهروزرسانی کنید (که در ادامه مقاله توضیح داده خواهد شد).
الگوریتم SimCLR

یک ماه پس از انتشار MoCo، SimCLR معرفی شد.
بیایید این موضوع را با جزئیات بیشتری بررسی کنیم
1. ایجاد نمای augmented
هدف: تولید نماهای متنوع از یک تصویر برای تحمیل عدم تغییر در برابر تغییرات. یک ترکیب از augmentations همیشه برجسته است: برش تصادفی و تغییر رنگ تصادفی.
تکنیکهای Augmentation:
– برش و تغییر اندازه تصادفی.
– تغییر رنگ (مانند روشنایی، کنتراست).
– تاری گوسی تصادفی.
– معکوس کردن افقی تصادفی.
حلقه بر روی  :
:
برای هر داده  در مینیبچ: دو تابع augmentation
در مینیبچ: دو تابع augmentation  و
و  را اعمال کنید تا دو نمای augmented ایجاد کنید:
را اعمال کنید تا دو نمای augmented ایجاد کنید:
 و
و  .
.

2. Base Encoder
معماری: از یک ResNet (مثلاً ResNet-50) بهعنوان encoder پایه  استفاده میشود.
استفاده میشود.
عملکرد: نماهای augmented را به نمایشهای نهفته رمزگذاری میکند:

برای هر نمای augmented  و
و  ، آنها را از طریق شبکه encoder
، آنها را از طریق شبکه encoder  عبور داده تا نمایشهای
عبور داده تا نمایشهای  و
و  به دست آید.
به دست آید.
نقش نرمالسازی:
Batch Normalization (BN) تضمین میکند که آموزش بهطور پایدار انجام شود، با نرمالسازی فعالیتها در mini-batchها. آمار ناسازگار از BN محلی (مثلاً هر GPU فقط از mini-batch محلی خود استفاده میکند) میتواند نویز وارد کند که منجر به کاهش عملکرد میشود.
Global BN در حین آموزش توزیعشده برای حفظ سازگاری در سراسر دستگاهها استفاده میشود. در آموزش توزیعشده بین چندین GPU، batch در دستگاهها تقسیم میشود. بدون Global BN، لایههای BN فعالیتها را بر اساس mini-batch کوچک محلی نرمالسازی میکنند، که ممکن است توزیع کامل batch را نمایندگی نکند.
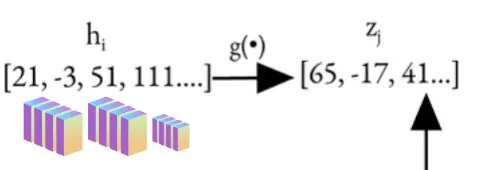
3. Projection Head
معماری: یک Multi-Layer Perceptron (MLP) با:
یک لایه مخفی.
فعالسازی ReLU.
خروجی با استفاده از نرمالسازی L2 نرمال میشود.
هدف: نمایشهای و را از طریق projection head  نقشهبرداری کرده و نمایشهای projected
نقشهبرداری کرده و نمایشهای projected  و
و  را به فضایی که برای contrastive loss بهینه شده است تولید کند:
را به فضایی که برای contrastive loss بهینه شده است تولید کند:
![\[ z_i = g(h_i) = W^{(2)} \sigma(W^{(1)} h_i) \]](https://class.vision/wp-content/ql-cache/quicklatex.com-fd738de656aea9e680aa2e7d76b2ffb0_l3.png "Rendered by QuickLaTeX.com")
برای مثال:
 و
و 
دلیل استفاده از Projection Head:
این لایه کیفیت نمایش در  را با اعمال contrastive loss بر روی
را با اعمال contrastive loss بر روی  بهبود میبخشد.
بهبود میبخشد.
مشاهده کلیدی: یک projection غیرخطی بهتر از یک projection خطی است (+3%) و خیلی بهتر از عدم استفاده از projection است (>10%). حتی زمانی که projection غیرخطی استفاده میشود، لایه قبل از projection head، ، هنوز بسیار بهتر است (>10%) از لایه بعد از آن، یعنی  ، که نشان میدهد لایه مخفی قبل از projection head نمایشی بهتر از لایه بعد از آن است. Projection Head با فدا کردن برخی اطلاعات (مثلاً رنگ، جهت) برای بهینهسازی contrastive loss، باعث میشود که برای وظایف دیگر مناسبتر باشد.
، که نشان میدهد لایه مخفی قبل از projection head نمایشی بهتر از لایه بعد از آن است. Projection Head با فدا کردن برخی اطلاعات (مثلاً رنگ، جهت) برای بهینهسازی contrastive loss، باعث میشود که برای وظایف دیگر مناسبتر باشد.
4. محاسبه شباهتهای جفتی ( Pairwise Similarities):
بر روی تمام مثالهای تقویتشده  حلقه بزنید: \\
حلقه بزنید: \\
شباهت کسینوسی  را بین تمام جفتهای امبدینگ محاسبه کنید:
را بین تمام جفتهای امبدینگ محاسبه کنید:
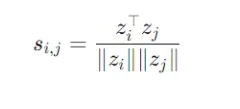
این مقدار نشان میدهد که چقدر دو امبدینگ  و
و  در فضای پیشنمایش مشابه هستند.
در فضای پیشنمایش مشابه هستند.
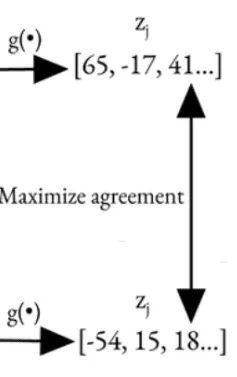
۵. تابع خطا
Contrastive Loss (NT-Xent):
فرمول جدیدی که ارائه شده را میتوان جایگزین نسخه قبلی کرد. متن بهروز شده برای وردپرس به صورت زیر خواهد بود:
- این تابع خطا، شباهت جفتهای مثبت و را با استفاده از تشابه کسینوسی حداکثر میکند.
- شباهت جفتهای منفی (سایر نمونههای موجود در دسته یا بچ) را حداقل میکند.
فرمول خطای زیر برای یک جفت مثبت ( ) تعریف شده است:
) تعریف شده است:
![\[ \ell_{i,j} = -\log \frac{\exp(\text{sim}(z_i, z_j)/\tau)}{\sum_{k=1}^{2N} \mathbb{1}_{[k \neq i]} \exp(\text{sim}(z_i, z_k)/\tau)} \]](https://class.vision/wp-content/ql-cache/quicklatex.com-85c2b9cc290ccfdd54b2b407592a9410_l3.png "Rendered by QuickLaTeX.com")
در اینجا:
–  : تشابه کسینوسی بین نمایشهای جفت مثبت است.
: تشابه کسینوسی بین نمایشهای جفت مثبت است.
–  : پارامتر دما (temperature) برای تنظیم مقیاسبندی.
: پارامتر دما (temperature) برای تنظیم مقیاسبندی.
– ![\mathbb{1}_{[k \neq i]}](https://class.vision/wp-content/ql-cache/quicklatex.com-a7370e6f272fa84d73579853b89d663a_l3.png "Rendered by QuickLaTeX.com") : شاخص حذف نمونه مثبت مرتبط.
: شاخص حذف نمونه مثبت مرتبط.
–  : تعداد کل نمونهها در دسته است.
: تعداد کل نمونهها در دسته است.
تابع خطای نهایی  بهصورت میانگین روی تمام زوجهای مثبت در دسته محاسبه میشود:
بهصورت میانگین روی تمام زوجهای مثبت در دسته محاسبه میشود:
![\mathcal{L} = \frac{1}{2N} \sum_{k=1}^N \left[ \ell(2k-1, 2k) + \ell(2k, 2k-1) \right]](https://class.vision/wp-content/ql-cache/quicklatex.com-2c687f0e24d5ff721e9abfdbb2522f05_l3.png "Rendered by QuickLaTeX.com")
این فرمول تضمین میکند که جفتهای مثبت در فضای تعبیه نزدیکتر به هم و جفتهای منفی دورتر قرار گیرند.
6. بهینهساز (Optimizer)
مقایسهکننده f و سر projection g را بهگونهای بهروزرسانی کنید که ضرر تقابلی L حداقل شود. سپس، در پایان آموزش، سر projection g را دور بیاندازید و تنها از encoder f برای وظایف پاییندستی استفاده کنید.
LARS (مقیاسبندی نرخ یادگیری بهطور لایهای)
بهینهساز نرخ یادگیری هر لایه یا گروه پارامتر را بهطور تطبیقی بر اساس بزرگی وزنها و گرادیانها اصلاح میکند. این روش برای اندازههای بزرگ بچها استفاده میشود تا نرخهای یادگیری لایههای مختلف بهطور تطبیقی مقیاسگذاری شوند با کمک نسبت اعتماد (که اطمینان حاصل میکند که نرخهای یادگیری با مقیاس وزنها و گرادیانها تطبیق مییابند). بهطور کلی، LARS از نرخهای یادگیری خاص هر لایه برای جلوگیری از جریمه بیشازحد لایههای خاص در حین بهینهسازی استفاده میکند.
چرا LARS؟
چالشهای بچهای بزرگ را مدیریت کرده و آموزش را در سراسر لایهها تثبیت میکند. LARS به SimCLR کمک میکند تا بهطور مؤثر بهروزرسانیهای گرادیان را در لایهها مدیریت کند، زمانی که با دادههای مقیاس بزرگ و ضرر تقابلی کار میکند، که شامل محاسبه شباهتهای جفت به جفت میشود.
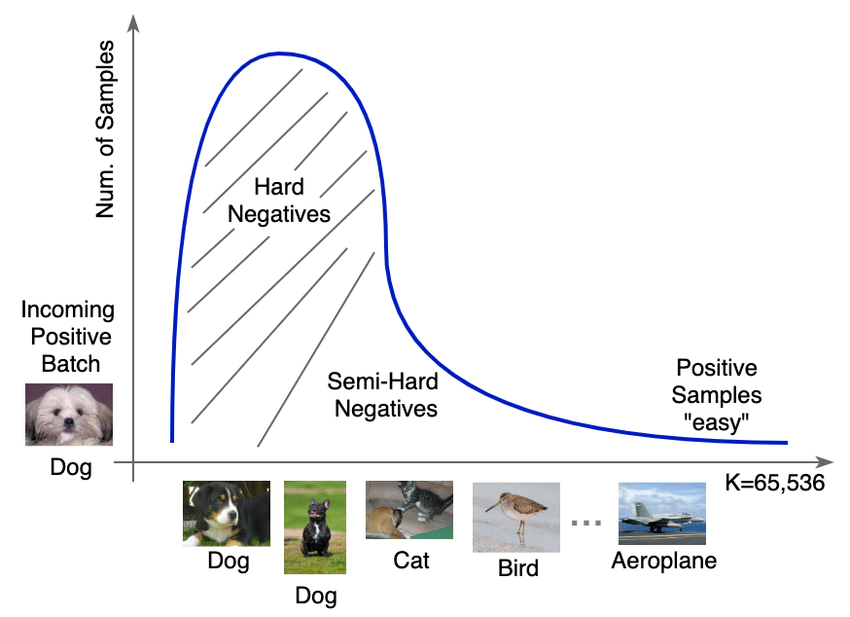
در SimCLR، اگر یک بچ شامل N تصویر باشد، 2N نما (دو نما برای هر تصویر) تولید میشود. برای هر نما zi، جفت مثبت آن نمای دیگر همان تصویر است. این به این معنی است که همه نماهای دیگر (2N-2) در بچ بهعنوان جفتهای منفی در نظر گرفته میشوند، صرفنظر از شباهت معنایی واقعی آنها. هنگامی که چندین نمونه از همان تصویر یا کلاس در بچ حضور دارند، این تنظیم میتواند منجر به منفیهای کاذب شود. منفیهای کاذب زمانی رخ میدهند که مدل به اشتباه نماهای معنایی مشابه (مانند نمونههای مختلف از همان تصویر یا کلاس) را بهعنوان جفتهای منفی در نظر میگیرد، حتی اگر باید جفتهای مثبت باشند.
چگونه SimCLR این مشکل را حل میکند
- اندازه بچ بزرگ: با بچهای بزرگ (مثلاً 4096 نمونه)، نسبت منفیهای کاذب به حداقل میرسد.
- data Augmentation قوی
- Projection Head: Projection head تضمین میکند که نمایشها برای یادگیری تقابلی به فضایی نهفته نگاشت شوند که برای هدف تقابلی بهینهسازی شده باشد، که ممکن است برخی از مشکلات ناشی از منفیهای کاذب را کاهش دهد.
- استخراج منفیهای سخت: بهجای اینکه تمام نماهای دیگر بهعنوان منفی در نظر گرفته شوند، از یک آستانه شباهت برای شامل کردن منفیهای سختتر استفاده میشود که بهطور انتخابی از انکر متفاوت هستند.
ادامه دارد…
منبع:
https://learnopencv.com/contrastive-learning-simclr-and-byol-with-code-example
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

دیدگاهتان را بنویسید