تابع ضرر یادگیری متضاد: NT-Xent و InfoNCE
“تابع هزینه NT-Xent: Normalized temperature-scaled cross entropy loss” و InfoNCE اساساً مشابه هستند. هر دو بهعنوان توابع هزینه (loss functions) رایج در وظایف یادگیری خودنظارتی (self-supervised learning) استفاده میشوند، جایی که هدف، یادگیری نمایشهای معنادار از طریق به حداکثر رساندن شباهت بین زوجهای مثبت (positive pairs) (نماهای افزایشیافته از یک نمونه) و به حداقل رساندن شباهت با زوجهای منفی (negative pairs) (نماهای افزایشیافته از نمونههای متفاوت) است.
نام تابع هزینه NT-Xent در مقاله SimCLR با عنوان “A Simple Framework for Contrastive Learning of Visual Representations“ معرفی شد. تفاوت اصلی بین این دو تابع هزینه، همانطور که در شکل 1 نشان داده شده است، در معیار شباهت (similarity measure) و نحوه نامگذاری ورودیهای افزایشیافته مختلف است. مقاله SimCLR از Google از معیار شباهت کسینوسی (cosine similarity measure) استفاده کرد، در حالی که مقاله MoCo از MetaAI (مقاله با عنوان “Momentum Contrast for Unsupervised Visual Representation Learning“) از ضرب داخلی (dot product) بهعنوان معیار شباهت بهره برده است.
توجه کنید که در اینجا نحوه پیادهسازی تابع هزینه InfoNCE در مقاله MoCo نشان داده شده است. نسخه اصلی پیشنهادی این تابع هزینه، شامل یک هایپر پارامتر دما (temperature) نبود.
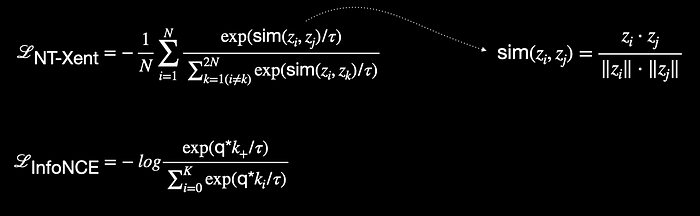
از اینجا به بعد، بر روی NT-Xent تمرکز میکنیم. بیایید آن را به بخشهای کوچکتر تقسیم کنیم.
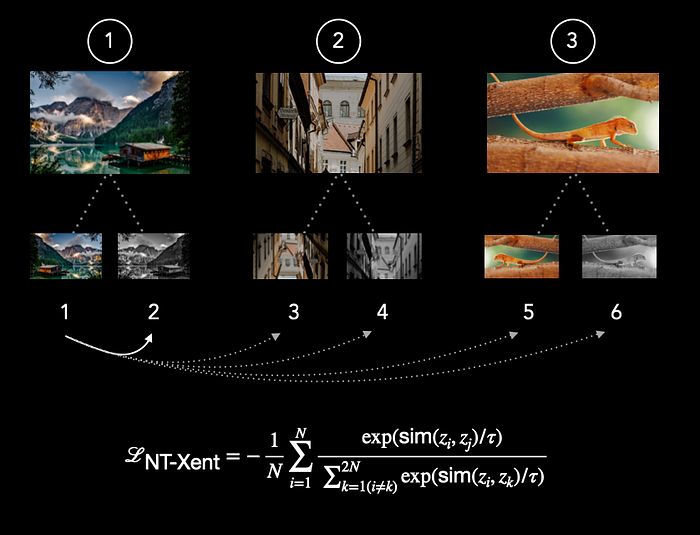
در تصویر زیر، ما سه تصویر متفاوت در یک batch داریم. ابتدا دو تغییر (augmentation) از هر تصویر ایجاد میکنیم که منجر به یک batch جدید با اندازه  میشود. بنابراین بهجای ۳ تصویر، اکنون ۶ تصویر متفاوت داریم. در این مرحله، تصاویر اصلی را بهطور ذهنی کنار میگذاریم و فقط با این ۶ تغییر (augmentations) کار میکنیم.
میشود. بنابراین بهجای ۳ تصویر، اکنون ۶ تصویر متفاوت داریم. در این مرحله، تصاویر اصلی را بهطور ذهنی کنار میگذاریم و فقط با این ۶ تغییر (augmentations) کار میکنیم.
این تغییرات ممکن است شامل تبدیلهایی مانند چرخش (rotation)، معکوس کردن (flip)، برش (cropping)، تغییر در روشنایی (brightness)، و موارد دیگر در حالت دادههای تصویری باشد. برای ورودیهای دیگر، مانند دادههای سری زمانی (time-series) نظیر EEG، تغییراتی مانند ماسک کردن (masking)، جابهجایی زمانی (time shift)، و نویز گاوسی (Gaussian noise) مناسب هستند.
ایده این است که شباهت بین زوج مثبت (1,2) را افزایش دهیم و در عین حال شباهت با تصاویر دیگر که به تصویر اول مرتبط نیستند را کاهش دهیم.
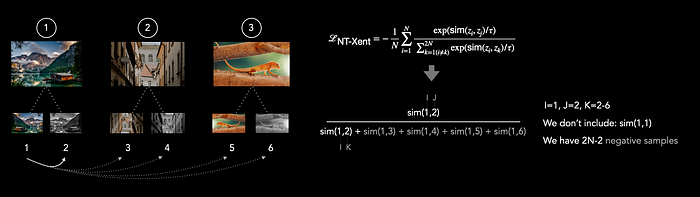
ما شباهت کسینوسی (cosine similarity) زوج مثبت  را با تمام نمونههای افزایشیافته دیگر درون minibatch مقایسه میکنیم، به جز زوج
را با تمام نمونههای افزایشیافته دیگر درون minibatch مقایسه میکنیم، به جز زوج  . سایر نمونهها بهعنوان نمونههای منفی (negative examples) در نظر گرفته میشوند. بنابراین در این حالت ما ۴ نمونه منفی داریم:
. سایر نمونهها بهعنوان نمونههای منفی (negative examples) در نظر گرفته میشوند. بنابراین در این حالت ما ۴ نمونه منفی داریم:  . به طور کلی، تعداد نمونههای منفی برابر است با
. به طور کلی، تعداد نمونههای منفی برابر است با  .
.
تابع هزینه NT-Xent مدل را تشویق میکند که نمایشهای زوجهای افزایشیافته مثبت (positive augmentation pairs) را در فضای تعبیه (embedding space) به یکدیگر نزدیکتر کند، در حالی که نمایشهای زوجهای افزایشیافته منفی (negative augmentation pairs) را از یکدیگر دورتر میکند. این رویکرد یادگیری خودنظارتی (self-supervised learning) به مدل کمک میکند تا نمایشهای معناداری را از طریق در نظر گرفتن نماهای متنوع از یک نمونه داده بیاموزد.
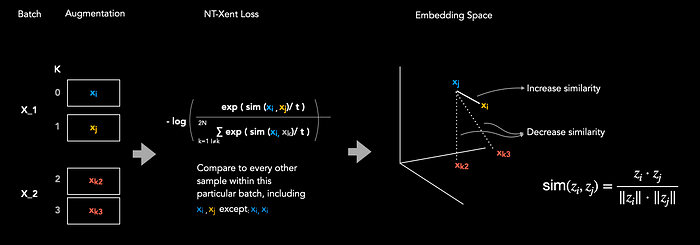
چگونگی محاسبه شباهت کسینوسی (Cosine Similarity) بین دو بردار:
بهعنوان یادآوری کلی، بهسرعت مرور میکنیم که شباهت کسینوسی چگونه محاسبه میشود. شباهت کسینوسی معیاری است برای سنجش میزان شباهت جهتهای تعبیهها (embeddings) در فضای تعبیه. فرض کنید دو تعبیه ![z_i = [1, 2, 3]](https://class.vision/wp-content/ql-cache/quicklatex.com-72e23f3f15c5e06fbad17fe6cfc03d27_l3.png "Rendered by QuickLaTeX.com") و
و ![z_j = [2, 3, 4]](https://class.vision/wp-content/ql-cache/quicklatex.com-0b07284740f81e761b07b74d0fa49331_l3.png "Rendered by QuickLaTeX.com") باشند. شباهت کسینوسی
باشند. شباهت کسینوسی  به صورت زیر محاسبه میشود:
به صورت زیر محاسبه میشود:
![\[ \text{sim}(z_i, z_j) = \frac{z_i \cdot z_j}{\|z_i\| \|z_j\|} \]](https://class.vision/wp-content/ql-cache/quicklatex.com-efa78a40d21cadbcc8e47f6e599016a7_l3.png "Rendered by QuickLaTeX.com")
که در آن:
–  ضرب داخلی (dot product) بین دو بردار است.
ضرب داخلی (dot product) بین دو بردار است.
–  و
و  اندازه (norm) بردارهای
اندازه (norm) بردارهای  و
و  هستند.
هستند.
– نتیجه یک مقدار نرمالشده بین -1 و 1 است، که 1 نشاندهنده بیشترین شباهت در جهت، 0 نشاندهنده بیارتباطی، و -1 نشاندهنده جهتهای کاملاً مخالف است.
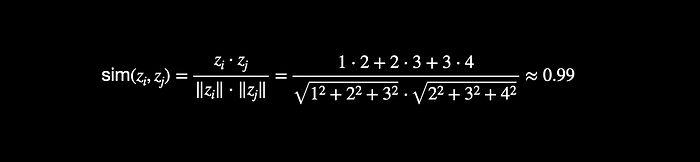
شباهت کسینوسی مقادیر بین -1 تا +1 را باز میگرداند. مقادیر نزدیک به +1 نشاندهنده شباهت بالای دو بردار هستند، در حالی که مقادیر نزدیک به -1 نشاندهنده بردارهای ناهماهنگ (dissimilar) هستند.
در مثال بالا، امتیاز شباهت 0.99 نشاندهنده بردارهای بسیار مشابه است.
اثر پارامتر دما (Temperature) بر روی تابع هزینه
در نهایت، یکی از ابرپارامترهای مهم تابع هزینه NT-Xent، یعنی دما (temperature) را بررسی میکنیم. در مثال زیر، تابع هزینه را با سه مقدار مختلف دما 1، 0.5 و 2 محاسبه میکنیم تا اثرات آن را بر روی تابع هزینه مشاهده کنیم:
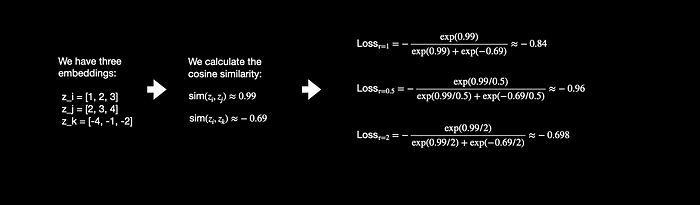
مقدار بالاتر دما (τ بزرگتر) منجر به مقادیر کوچکتری از امتیاز شباهت نرمالشده (normalized similarity) میشود، در حالی که مقدار پایینتر دما (τ کوچکتر) منجر به مقادیر بزرگتری از امتیاز شباهت نرمالشده میشود. این مقیاسبندی به کنترل حساسیت تابع هزینه به تفاوتهای کوچک در شباهت کمک میکند.
پارامتر دما بر توزیع شباهتها تأثیر میگذارد. مقدار بالاتر دما منجر به توزیع نرمتری میشود، جایی که شباهتها بین زوجها به طور یکنواختتری در سراسر دامنه توزیع میشوند. در مقابل، مقدار پایینتر دما منجر به توزیع تیزتری میشود، جایی که شباهتها بیشتر حول مقادیر افراطی متمرکز میشوند (شباهت بالا برای زوجهای مثبت و شباهت پایین برای زوجهای منفی).
منبع:
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

دیدگاهتان را بنویسید