مدل هوش مصنوعی چیست؟

مدل هوش مصنوعی (AI model) برنامهای است که روی مجموعهای از دادهها آموزش دیده تا الگوهای خاصی را تشخیص دهد یا تصمیمات معینی را بدون دخالت بیشتر انسان اتخاذ کند. مدلهای هوش مصنوعی الگوریتمهای مختلفی را روی دادههای ورودی مرتبط اعمال میکنند تا به وظایف یا خروجیهایی که برای آنها برنامهریزی شدهاند، دست یابند.
به زبان ساده، مدل هوش مصنوعی با تواناییاش در تصمیمگیری یا پیشبینی خودکار تعریف میشود، نه با شبیهسازی هوش انسانی. از جمله اولین مدلهای موفق هوش مصنوعی، برنامههای بازی چکرز و شطرنج در اوایل دهه ۱۹۵۰ بودند: این مدلها به برنامهها امکان میدادند تا مستقیماً در پاسخ به حرکت حریف انسانی واکنش نشان دهند، به جای اینکه از یک سری حرکات از پیش تعیین شده پیروی کنند.
انواع مختلف مدلهای هوش مصنوعی برای وظایف یا حوزههای خاصی مناسبتر هستند که منطق تصمیمگیری خاص آنها مفیدتر یا مرتبطتر است. سیستمهای پیچیده اغلب به طور همزمان از چندین مدل استفاده میکنند و از تکنیکهای یادگیری ترکیبی (ensemble learning) مانند bagging، boosting یا stacking بهره میبرند.
با پیچیدهتر و انعطافپذیرتر شدن ابزارهای هوش مصنوعی، آنها به مقادیر چالشبرانگیز بیشتری از داده و قدرت محاسباتی برای آموزش و اجرا نیاز دارند. در پاسخ به این نیاز، سیستمهایی که برای اجرای وظایف خاص در یک حوزه طراحی شدهاند، جای خود را به مدلهای پایه (foundation models) میدهند که روی مجموعههای بزرگ دادههای بدون برچسب پیشآموزش دیدهاند و قابلیت کاربردهای گستردهای دارند. این مدلهای پایه انعطافپذیر سپس میتوانند برای وظایف خاص fine-tune شوند.
تفاوت الگوریتمها و مدلها
هرچند این دو اصطلاح در این زمینه اغلب به جای یکدیگر استفاده میشوند، اما دقیقاً یک معنا ندارند.
- الگوریتمها فرآیندهایی هستند که اغلب به زبان ریاضی یا شبهکد توصیف میشوند و برای دستیابی به یک عملکرد یا هدف خاص روی یک مجموعه داده اعمال میشوند.
- مدلها خروجی الگوریتمی هستند که روی یک مجموعه داده اعمال شده است.
به زبان ساده، یک مدل AI برای پیشبینی یا تصمیمگیری استفاده میشود و یک الگوریتم منطق اصلی است که مدل AI بر اساس آن عمل میکند.
مدلهای AI و یادگیری ماشین
مدلهای AI میتوانند تصمیمگیری را خودکار کنند، اما تنها مدلهایی که قابلیت یادگیری ماشین (ML) دارند قادرند به صورت خودمختار عملکرد خود را در طول زمان بهینه کنند.
در حالی که همه مدلهای ML نوعی AI هستند، همه AIها شامل یادگیری ماشین نمیشوند. ابتداییترین مدلهای AI مجموعهای از عبارات if-then-else هستند که قوانین آنها به صورت صریح توسط دانشمند داده برنامهریزی شده است. این مدلها با نامهای دیگری مانند موتورهای قانونمحور، سیستمهای خبره، گرافهای دانش یا AI نمادین شناخته میشوند.
مدلهای یادگیری ماشین از AI آماری به جای AI نمادین استفاده میکنند. در حالی که مدلهای AI قانونمحور باید به صورت صریح برنامهریزی شوند، مدلهای ML با اعمال چارچوبهای ریاضی خود روی یک مجموعه داده نمونه “آموزش داده میشوند”. نقاط داده در این مجموعه، مبنای پیشبینیهای آینده مدل در دنیای واقعی هستند.
تکنیکهای مدل ML به طور کلی به سه دسته اصلی تقسیم میشوند:
- یادگیری نظارتشده (Supervised Learning):
که به عنوان یادگیری ماشین “کلاسیک” شناخته میشود، نیاز به یک متخصص انسانی دارد تا دادههای آموزشی را برچسبگذاری کند. برای مثال، یک دانشمند داده که یک مدل تشخیص تصویر را برای شناسایی سگها و گربهها آموزش میدهد باید تصاویر نمونه را با برچسبهایی مانند “سگ” یا “گربه” مشخص کند و همچنین ویژگیهای کلیدی مانند اندازه، شکل یا خز که این برچسبهای اصلی را مشخص میکنند. سپس مدل میتواند در طول آموزش از این برچسبها برای استنتاج ویژگیهای بصری معمولی سگها و گربهها استفاده کند. - یادگیری بدون نظارت (Unsupervised Learning):
برخلاف روشهای یادگیری نظارتشده، یادگیری بدون نظارت فرض نمیکند که پاسخهای “درست” یا “غلط” از قبل وجود دارند و بنابراین نیازی به برچسبگذاری ندارد. این الگوریتمها الگوهای ذاتی در مجموعه دادهها را شناسایی میکنند تا نقاط داده را به گروههایی دستهبندی کنند و پیشبینیها را اطلاع دهند. به عنوان مثال، کسبوکارهای تجارت الکترونیک مانند آمازون از مدلهای ارتباطی بدون نظارت برای ارائه پیشنهادات در موتورهای توصیه استفاده میکنند. - یادگیری تقویتی (Reinforcement Learning):
در یادگیری تقویتی، یک مدل به صورت کلی از طریق آزمون و خطا یاد میگیرد و با پاداش دادن به خروجیهای درست (یا جریمه کردن خروجیهای نادرست) بهینه میشود. مدلهای تقویتی برای پیشنهادات شبکههای اجتماعی، معاملات الگوریتمی سهام، و حتی خودروهای خودران استفاده میشوند.
یادگیری عمیق (Deep Learning)
یادگیری عمیق زیرمجموعهای پیشرفتهتر از یادگیری بدون نظارت است که ساختار شبکههای عصبی آن تلاش میکند تا ساختار مغز انسان را شبیهسازی کند. لایههای متعدد از گرههای بههمپیوسته به تدریج دادهها را دریافت میکنند، ویژگیهای کلیدی را استخراج میکنند، روابط را شناسایی میکنند و تصمیمات را در فرایندی به نام Forward Propagation اصلاح میکنند. فرایند دیگری به نام Backpropagation مدلهایی را اعمال میکند که خطاها را محاسبه کرده و وزنها و بایاسهای سیستم را تنظیم میکنند. بیشتر برنامههای پیشرفته AI، مانند مدلهای زبانی بزرگ (LLM) که چتباتهای مدرن را قدرت میبخشند، از یادگیری عمیق استفاده میکنند. این روش نیازمند منابع محاسباتی بسیار زیادی است.
مدلهای مولد در مقابل مدلهای تمایزی
یکی از روشهای تفکیک مدلهای یادگیری ماشین، بررسی روششناسی بنیادی آنها است. بیشتر مدلها را میتوان به دو دسته مولد یا تمایزی تقسیم کرد. تفاوت این دو در نحوه مدلسازی دادهها در فضای مشخصی است.
مدلهای مولد (Generative Models)
مدلهای مولد، که معمولاً شامل یادگیری بدون نظارت هستند، توزیع نقاط داده را مدلسازی کرده و هدفشان پیشبینی احتمال مشترک P(x,y) برای ظاهر شدن یک نقطه داده خاص در یک فضای مشخص است. برای مثال، یک مدل مولد در حوزه بینایی کامپیوتری ممکن است همبستگیهایی مانند “چیزهایی که شبیه ماشین هستند معمولاً چهار چرخ دارند” یا “چشمها بعید است بالای ابروها ظاهر شوند” را شناسایی کند.
این پیشبینیها میتوانند به تولید خروجیهایی که مدل آنها را بسیار محتمل میداند کمک کنند. به عنوان مثال، یک مدل مولد آموزشدیده بر دادههای متنی میتواند پیشنهادات املا یا تکمیل خودکار را ارائه دهد؛ در پیچیدهترین سطح، حتی میتواند متن کاملاً جدید تولید کند. به طور خلاصه، زمانی که یک مدل زبانی بزرگ (LLM) متن تولید میکند، احتمال بالایی برای ترتیب خاصی از کلمات در پاسخ به ورودی دادهشده محاسبه کرده است.
کاربردهای رایج مدلهای مولد
کاربردهای رایج مدلهای مولد شامل تولید تصویر، ساخت موسیقی، انتقال سبک و ترجمه زبان میشوند.
مثالهایی از مدلهای مولد:
- مدلهای انتشار (Diffusion Models):
این مدلها به تدریج نویز گوسی را به دادههای آموزشی اضافه میکنند تا دادهها غیرقابل تشخیص شوند و سپس فرآیند معکوس “کاهش نویز” را یاد میگیرند که میتواند خروجی (معمولاً تصاویر) را از نویز تصادفی تولید کند. - خودرمزگذارهای تنوعی (Variational Autoencoders یا VAEs):
VAEs شامل یک رمزگذار هستند که دادههای ورودی را فشردهسازی میکند و یک رمزگشا که فرآیند را معکوس کرده و توزیع احتمالی دادههای محتمل را مدلسازی میکند. - مدلهای ترانسفورمر (Transformer Models):
مدلهای ترانسفورمر از تکنیکهای ریاضی به نام توجه (Attention) یا توجه به خود (Self-Attention) استفاده میکنند تا مشخص کنند چگونه عناصر مختلف در یک سری داده بر یکدیگر تأثیر میگذارند. به عنوان مثال، “GPT” در Chat-GPT شرکت OpenAI مخفف Generative Pretrained Transformer است.
مدلهای تمایزی (Discriminative Models)
مدلهای تمایزی، که معمولاً شامل یادگیری نظارتشده هستند، مرزهای بین کلاسهای داده (یا “مرزهای تصمیمگیری”) را مدلسازی میکنند. هدف این مدلها پیشبینی احتمال شرطی P(y|x) است، یعنی احتمال اینکه یک نقطه داده مشخص (x) به یک کلاس خاص (y) تعلق داشته باشد.
برای مثال، یک مدل تمایزی در حوزه بینایی کامپیوتری ممکن است تفاوت بین “ماشین” و “غیرماشین” را از طریق شناسایی تفاوتهای کلیدی یاد بگیرد (مانند “اگر چرخ نداشته باشد، ماشین نیست”) و به این ترتیب میتواند بسیاری از همبستگیهایی که یک مدل مولد باید بررسی کند را نادیده بگیرد. به همین دلیل، مدلهای تمایزی معمولاً به قدرت محاسباتی کمتری نیاز دارند.
کاربرد مدلهای تمایزی
مدلهای تمایزی به طور طبیعی برای وظایف طبقهبندی مانند تحلیل احساسات مناسب هستند، اما کاربردهای زیادی دارند.
برای مثال:
درخت تصمیمگیری و مدلهای جنگل تصادفی فرآیندهای پیچیده تصمیمگیری را به مجموعهای از گرهها تقسیم میکنند که هر “برگ” نشاندهنده یک تصمیم بالقوه برای طبقهبندی است.
موارد استفاده
در حالی که مدلهای تمایزی یا مولد ممکن است به طور کلی در موارد خاص دنیای واقعی عملکرد بهتری نسبت به یکدیگر داشته باشند، بسیاری از وظایف را میتوان با هر دو نوع مدل انجام داد.
برای مثال:
مدلهای تمایزی کاربردهای زیادی در پردازش زبان طبیعی (NLP) دارند و اغلب در وظایفی مانند ترجمه ماشین (که مستلزم تولید متن ترجمهشده است) عملکرد بهتری نسبت به AI مولد دارند.
به همین ترتیب، مدلهای مولد میتوانند برای طبقهبندی با استفاده از قضیه بیز به کار روند.
به جای تعیین اینکه یک نمونه در کدام طرف مرز تصمیم قرار دارد (مانند مدل تمایزی)، مدل مولد میتواند احتمال تولید نمونه توسط هر کلاس را تعیین کرده و کلاس با احتمال بالاتر را انتخاب کند.
ترکیب مدلهای مولد و تمایزی
بسیاری از سیستمهای AI از هر دو نوع مدل به صورت ترکیبی استفاده میکنند.
برای مثال:
در یک شبکه مولد تخاصمی (Generative Adversarial Network یا GAN):
- یک مدل مولد دادههای نمونه تولید میکند.
- یک مدل تمایزی تعیین میکند که آیا آن دادهها “واقعی” هستند یا “جعلی”.
- خروجی مدل تمایزی برای آموزش مدل مولد استفاده میشود تا زمانی که مدل تمایزی دیگر نتواند دادههای “جعلی” تولیدشده را تشخیص دهد.
مدلهای طبقهبندی در مقابل مدلهای رگرسیون
یکی دیگر از روشهای دستهبندی مدلها، ماهیت وظایفی است که برای آنها استفاده میشوند. بیشتر الگوریتمهای کلاسیک مدلهای AI یا طبقهبندی انجام میدهند یا رگرسیون. برخی مدلها برای هر دو مناسب هستند، و بیشتر مدلهای پایه از هر دو نوع عملکرد بهره میبرند.
این اصطلاحات گاهی ممکن است باعث سردرگمی شوند. برای مثال، رگرسیون لجستیک یک مدل تمایزی است که برای طبقهبندی استفاده میشود.
مدلهای رگرسیون (Regression Models)
مدلهای رگرسیون مقادیر پیوسته را پیشبینی میکنند (مانند قیمت، سن، اندازه یا زمان). این مدلها عمدتاً برای تعیین رابطه بین یک یا چند متغیر مستقل (x) و یک متغیر وابسته (y) استفاده میشوند: با داشتن x، مقدار y را پیشبینی کنید.
نمونههایی از الگوریتمهای رگرسیون:
- رگرسیون خطی و انواع مرتبط مانند رگرسیون کوانتیل:
- کاربرد: پیشبینی، تحلیل کشش قیمت، و ارزیابی ریسک.
- رگرسیون چندجملهای و رگرسیون بردار پشتیبان (SVR):
- مدلسازی روابط پیچیده غیرخطی بین متغیرها.
- مدلهای مولد مانند خودرگرسیون و خودرمزگذارهای تنوعی (VAEs):
- این مدلها علاوه بر روابط همبستگی بین مقادیر گذشته و آینده، روابط علّی را نیز در نظر میگیرند.
- کاربرد: پیشبینی سناریوهای آب و هوایی و رویدادهای شدید اقلیمی.
مدلهای طبقهبندی (Classification Models)
مدلهای طبقهبندی مقادیر گسسته را پیشبینی میکنند. این مدلها عمدتاً برای تعیین یک برچسب مناسب یا دستهبندی (یعنی طبقهبندی) استفاده میشوند.
این طبقهبندی میتواند باینری باشد—مانند “بله یا خیر”، “پذیرش یا رد”—یا چندکلاسه (مانند موتور توصیه که محصول A، B، C یا D را پیشنهاد میدهد).
کاربردها:
الگوریتمهای طبقهبندی برای وظایف مختلفی استفاده میشوند، از دستهبندی ساده گرفته تا استخراج ویژگیهای خودکار در شبکههای یادگیری عمیق، تا پیشرفتهای پزشکی مانند طبقهبندی تصاویر تشخیصی در رادیولوژی.
نمونههایی از الگوریتمهای طبقهبندی:
- Naïve Bayes:
- الگوریتم مولد نظارتشده که معمولاً در فیلتر کردن اسپم و طبقهبندی اسناد استفاده میشود.
- تحلیل تمایز خطی (Linear Discriminant Analysis):
- برای حل تناقضات ناشی از همپوشانی بین ویژگیهای متعدد که بر طبقهبندی تأثیر میگذارند.
- رگرسیون لجستیک:
- پیشبینی احتمالات پیوسته که به عنوان جایگزین برای محدودههای طبقهبندی استفاده میشوند.
آموزش مدلهای AI
فرآیند یادگیری در یادگیری ماشین از طریق آموزش مدلها با مجموعه دادههای نمونه انجام میشود. روندها و همبستگیهای احتمالی شناساییشده در این مجموعههای نمونه سپس برای عملکرد سیستم اعمال میشوند.
یادگیری نظارتشده و نیمهنظارتشده:
- دادههای آموزشی باید توسط دانشمندان داده با دقت برچسبگذاری شوند تا نتایج بهینه شوند.
- در صورت استخراج ویژگیهای مناسب، یادگیری نظارتشده به طور کلی به مقدار کمتری داده آموزشی نسبت به یادگیری بدون نظارت نیاز دارد.
دادههای واقعی:
مدلهای ML در حالت ایدهآل باید با دادههای دنیای واقعی آموزش داده شوند. این روش به طور شهودی بهترین تضمین را برای انعکاس شرایط دنیای واقعی که مدل برای تحلیل یا شبیهسازی آن طراحی شده، فراهم میکند.
اما تکیه صرف بر دادههای واقعی همیشه ممکن، عملی یا بهینه نیست.
افزایش اندازه و پیچیدگی مدلها
هرچه یک مدل پارامترهای بیشتری داشته باشد، به دادههای بیشتری برای آموزش نیاز دارد. با افزایش اندازه مدلهای یادگیری عمیق، جمعآوری این دادهها دشوارتر میشود.
این موضوع بهویژه در مدلهای زبانی بزرگ (LLMs) مشهود است:
- مدلهای GPT-3 شرکت OpenAI و BLOOM منبعباز هر دو بیش از 175 میلیارد پارامتر دارند.
مشکلات دادههای عمومی:
استفاده از دادههای عمومی، علیرغم راحتی آن، میتواند مشکلات نظارتی ایجاد کند—مانند زمانی که دادهها باید ناشناس شوند—و همچنین مشکلات عملی.
برای مثال: مدلهای زبانی که بر اساس پستهای شبکههای اجتماعی آموزش داده شدهاند ممکن است عادتها یا نادرستیهایی را “یاد بگیرند” که برای استفاده در سازمانها مناسب نیستند.
دادههای مصنوعی:
دادههای مصنوعی یک راهحل جایگزین ارائه میدهند: مجموعهای کوچکتر از دادههای واقعی برای تولید دادههای آموزشی استفاده میشود که شباهت زیادی به دادههای اصلی دارند و نگرانیهای مربوط به حریم خصوصی را برطرف میکنند.
حذف سوگیری
مدلهای ML که با دادههای واقعی آموزش داده میشوند به طور اجتنابناپذیری سوگیریهای اجتماعی موجود در آن دادهها را جذب میکنند. اگر این سوگیریها حذف نشوند، در هر زمینهای که مدلها اطلاعرسانی میکنند، مانند مراقبتهای بهداشتی یا استخدام، نابرابری را تداوم و تشدید میکنند.
تحقیقات علوم داده الگوریتمهایی مانند FairIJ و تکنیکهای اصلاح مدل مانند FairReprogram را برای مقابله با نابرابری ذاتی در دادهها ارائه دادهاند.
Overfitting و Underfitting
- Overfitting: زمانی رخ میدهد که یک مدل ML دادههای آموزشی را بیش از حد نزدیک به خود تطبیق دهد، و اطلاعات نامربوط (یا “نویز”) موجود در مجموعه نمونه بر عملکرد مدل تأثیر بگذارد.
- Underfitting: حالت مخالف است: آموزش ناکافی یا نامناسب مدل.
مدلهای پایه (Foundation Models)
مدلهای پایه، که با نامهای مدلهای اولیه یا مدلهای از پیش آموزشدیده نیز شناخته میشوند، مدلهای یادگیری عمیقی هستند که بر روی مجموعه دادههای بزرگ مقیاس آموزش داده شدهاند تا ویژگیها و الگوهای عمومی را یاد بگیرند. این مدلها به عنوان نقطه شروعی برای fine-tune کردن یا تطبیق برای کاربردهای خاص AI استفاده میشوند.
مزایا و کاربردها:
به جای ساخت مدلها از ابتدا، توسعهدهندگان میتوانند لایههای شبکه عصبی را تغییر دهند، پارامترها را تنظیم کنند یا معماریها را به نیازهای خاص حوزه تطبیق دهند.
این روش، با توجه به عمق و گستردگی دانش موجود در یک مدل بزرگ و اثباتشده، زمان و منابع قابل توجهی در فرآیند آموزش مدل صرفهجویی میکند.
مدلهای پایه به این ترتیب توسعه و پیادهسازی سریعتر سیستمهای AI را ممکن میسازند.
تکنیکهای جدید برای تطبیق مدلهای پایه:
تطبیق مدلهای از پیش آموزشدیده برای وظایف تخصصی اخیراً جای خود را به تکنیکی به نام prompt-tuning داده است.
در این روش، نشانههای جلویی به مدل معرفی میشوند تا مدل را به سمت نوع خاصی از تصمیمگیری یا پیشبینی هدایت کنند.
صرفهجویی در منابع:
به گفته David Cox، مدیر مشترک آزمایشگاه MIT-IBM Watson AI، بازاستفاده از یک مدل یادگیری عمیق آموزشدیده (به جای آموزش یا بازآموزی یک مدل جدید) میتواند مصرف کامپیوتر و انرژی را بیش از ۱,۰۰۰ برابر کاهش دهد.
این صرفهجویی منجر به کاهش چشمگیر هزینهها میشود.
منبع: https://www.ibm.com/think/topics/ai-model
مطالب زیر را حتما مطالعه کنید

تفاوت انتقال یادگیری و فاینتیونینگ در یادگیری عمیق
فاینتیونینگ (Fine-tuning) چیست؟
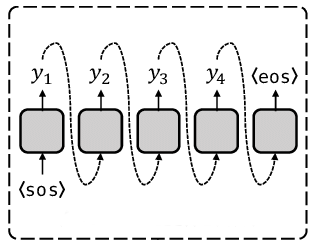
مدلهای خودهمبسته یا Autoregressive
دیدگاهتان را بنویسید