مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

Fine-Tuning
همانطور که در بخش قبلی (مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 1) دیدهاید، آموزش مدلهای انتشار از صفر میتواند زمانبر باشد! بهویژه وقتی بخواهیم به رزولوشنهای بالاتر برسیم، زمان و داده لازم برای آموزش یک مدل از صفر ممکن است غیرعملی شود.
خوشبختانه یک راهحل وجود دارد: شروع با مدلی که قبلاً آموزش دیده است!
به این ترتیب، ما از مدلی شروع میکنیم که قبلاً یاد گرفته تصاویر را denoise کند و امید داریم که این نقطه شروع بهتر از شروع با یک مدل کاملاً تصادفی باشد.
فاین تیون کردن معمولاً زمانی بهترین نتیجه را میدهد که دادههای جدید تا حدودی شبیه دادههای آموزشی اصلی مدل پایه باشند (برای مثال، شروع با مدلی که روی تصاویر چهره آموزش دیده است، احتمالاً ایده خوبی است اگر بخواهید چهرههای کارتونی تولید کنید). با این حال، به طور شگفتانگیزی، این مزایا حتی زمانی که دامنه دادهها بهطور قابل توجهی تغییر کند نیز باقی میمانند.
تصویر بالا از مدلی تولید شده است که ابتدا روی مجموعه داده LSUN Bedrooms آموزش دیده و سپس برای ۵۰۰ مرحله روی مجموعه WikiArt فاین تیون شده است. اسکریپت آموزش نیز برای مرجع همراه با نوتبوکهای این واحد ارائه شده است.
Guidance (راهنمایی)
مدلهای unconditional کنترل زیادی بر آنچه تولید میشود ارائه نمیدهند. میتوانیم یک مدل conditional آموزش دهیم، که در ادامه بیشتر در این باره صحبت میکنیم، که ورودیهای اضافی میگیرد تا فرآیند تولید را هدایت کند. اما اگر ما قبلاً یک مدل unconditional آموزشدیده داشته باشیم و بخواهیم از آن استفاده کنیم چه؟
اینجاست که guidance وارد میشود: فرآیندی که در آن پیشبینیهای مدل در هر مرحله تولید با یک تابع راهنما (guidance function) ارزیابی شده و تغییر داده میشوند تا تصویر نهایی تولیدشده بهترجیح ما نزدیکتر باشد.

این guidance function میتواند تقریباً هر چیزی باشد و همین موضوع آن را به یک تکنیک قدرتمند تبدیل میکند! در نوتبوک، از یک مثال ساده شروع میکنیم (کنترل رنگ، همانطور که در خروجی نمونه بالا نشان داده شده است) و سپس به سراغ استفاده از یک مدل از پیش آموزشدیده قدرتمند به نام CLIP میرویم که به ما اجازه میدهد فرایند تولید را بر اساس توصیف متنی هدایت کنیم.
Conditioning (شرطیسازی)
Guidance راه بسیار خوبی است برای اینکه از یک مدل diffusion بدون شرط (unconditional) استفاده بیشتری ببریم. اما اگر هنگام آموزش اطلاعات اضافی (مثل یک برچسب کلاس یا یک توضیح تصویری) در دسترس داشته باشیم، میتوانیم آن را هم به مدل بدهیم تا در پیشبینیهایش از آن استفاده کند.
با این کار، یک مدل conditional ایجاد میکنیم که میتوانیم در زمان inference آن را کنترل کنیم، با اینکه چه چیزی را به عنوان conditioning به آن میدهیم. نوتبوک یک نمونه از مدل class-conditioned نشان میدهد که یاد میگیرد بر اساس برچسب کلاس، تصاویر تولید کند.

روشهای مختلفی برای وارد کردن اطلاعات conditioning وجود دارد، از جمله:
-
اضافه کردن بهعنوان کانالهای اضافی در ورودی UNet
این روش زمانی رایج است که اطلاعات conditioning همان شکل (shape) تصویر را داشته باشد، مثل segmentation mask، depth map یا یک نسخه تار تصویر (در مدلهای ترمیم / اَبَر وضوح). این روش برای سایر انواع conditioning هم کار میکند.
برای مثال، در نوتبوک برچسب کلاس به یک embedding نگاشته میشود و سپس به گونهای گسترش مییابد که عرض و ارتفاعی برابر با تصویر ورودی داشته باشد، تا بتوان آن را بهعنوان کانالهای اضافی به مدل داد. -
ساخت embedding و فشردهسازی آن به اندازهای که با تعداد کانالهای خروجی یکی از لایههای داخلی UNet تطابق داشته باشد
سپس embedding به آن خروجیها اضافه میشود. برای نمونه، conditioning بر اساس timestep دقیقاً به این شکل انجام میشود: خروجی هر بلاک ResNet یک embedding فشرده timestep دریافت میکند.
این رویکرد زمانی مفید است که یک بردار (مثلاً embedding تصویری CLIP) را بهعنوان اطلاعات conditioning داشته باشیم. یکی از نمونههای معروف، نسخهی Image Variations از Stable Diffusion است که دقیقاً از همین روش استفاده میکند. -
اضافه کردن لایههای cross-attention که میتوانند روی یک دنباله (sequence) از conditioning تمرکز کنند.
این روش زمانی بیشترین کاربرد را دارد که conditioning به شکل متن باشد — متن ابتدا توسط یک مدل transformer به یک دنباله embedding تبدیل میشود، سپس لایههای cross-attention در UNet برای ترکیب این اطلاعات در مسیر denoising به کار میروند.
Fine-Tuning و Guidance
در ادامه، ما در کد به دو رویکرد اصلی برای انطباق مدلهای diffusion موجود میپردازیم:
-
با Fine-Tuning، مدلهای موجود را روی دادههای جدید دوباره آموزش میدهیم تا نوع خروجی آنها تغییر کند.
-
با Guidance، یک مدل موجود را در زمان inference هدایت میکنیم تا کنترل بیشتری بر فرایند تولید داشته باشیم.
Setup و Imports
برای ذخیره کردن مدلهای Fine-Tuned خود در Hugging Face Hub، لازم است با یک token که دسترسی نوشتن دارد وارد شوید.
اگر میخواهید در حین آموزش، نمونهها (samples) را با استفاده از Weights & Biases ثبت کنید، باید یک حساب کاربری در این سرویس هم داشته باشید.
علاوه بر این، تنها کاری که باقی میماند نصب چند وابستگی (dependencies)، وارد کردن کتابخانههای موردنیاز و مشخص کردن دستگاه (device) مورد استفاده است:
%pip install -qq diffusers datasets accelerate wandb open-clip-torch
# Code to log in to the Hugging Face Hub, needed for sharing models # Make sure you use a token with WRITE access from huggingface_hub import notebook_login notebook_login()
Token is valid. Your token has been saved in your configured git credential helpers (store). Your token has been saved to /root/.huggingface/token Login successful
import numpy as np import torch import torch.nn.functional as F import torchvision from datasets import load_dataset from diffusers import DDIMScheduler, DDPMPipeline from matplotlib import pyplot as plt from PIL import Image from torchvision import transforms from tqdm.auto import tqdm
device = "mps" if torch.backends.mps.is_available() else "cuda" if torch.cuda.is_available() else "cpu"
لود یک Pipeline از قبل آموزش داده شده
برای شروع این نوتبوک، بیایید یک pipeline از پیش آموزشدیده (Pre-Trained) بارگذاری کنیم و ببینیم چه کارهایی میتوان با آن انجام داد
image_pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
image_pipe.to(device)
تولید تصاویر به سادگی اجرای متد __call__ از pipeline است؛ کافی است آن را مثل یک تابع صدا بزنید:
images = image_pipe().images images[0]

جالب، اما کند بود! ♂️
پس، قبل از اینکه به موضوعات اصلی امروز برسیم، بیایید نگاهی به sampling loop واقعی بیندازیم و ببینیم چطور میتوانیم با استفاده از یک سمپلر پیشرفتهتر این فرایند را سریعتر کنیم:
سمپل گیری سریعتر با DDIM
در هر مرحله، مدل یک ورودی نویزی دریافت میکند و باید نویز را پیشبینی کند (و در نتیجه تخمینی از آنچه تصویرِ کاملاً بدون نویز خواهد بود ارائه دهد). در ابتدا این پیشبینیها چندان خوب نیستند، به همین دلیل فرآیند را به مراحل زیادی تقسیم میکنیم. با این حال، تحقیقات اخیر نشان دادهاند که استفاده از بیش از ۱۰۰۰ مرحله ضروری نیست و پژوهشهای زیادی بررسی کردهاند که چگونه میتوان با کمترین تعداد مرحله به نمونههای باکیفیت رسید.
در کتابخانه Diffusers، این روشهای sampling توسط یک scheduler مدیریت میشوند که باید هر بهروزرسانی را از طریق تابع step() انجام دهد.
برای تولید یک تصویر:
- ابتدا با یک نویز تصادفی
 شروع میکنیم.
شروع میکنیم. - سپس برای هر timestep در noise schedule، ورودی نویزی را به مدل میدهیم.
- خروجی مدل به تابع
step()پاس داده میشود. - این تابع یک خروجی شامل ویژگی
prev_sampleبرمیگرداند — که به آن «previous» میگوییم چون در واقع داریم برعکس زمان (backward) حرکت میکنیم: از نویز زیاد به نویز کم (برخلاف فرآیند دیفیوژن یا انتشار رو به جلو – forward diffusion process).
بیایید این را در عمل ببینیم! ابتدا یک scheduler بارگذاری میکنیم — در اینجا یک DDIMScheduler بر اساس مقاله
Denoising Diffusion Implicit Models که میتواند با تعداد مراحل بسیار کمتر از پیادهسازی اصلی DDPM، نمونههای مناسبی تولید کند:
![\[~\]](https://class.vision/wp-content/ql-cache/quicklatex.com-9a90cf069d9fa0b0f2a1ef135783e1db_l3.png "Rendered by QuickLaTeX.com")
# Create new scheduler and set num inference steps
scheduler = DDIMScheduler.from_pretrained("google/ddpm-celebahq-256")
scheduler.set_timesteps(num_inference_steps=40)
میبینید که این مدل مجموعاً ۴۰ مرحله اجرا میکند، که هر کدام معادل پرش ۲۵ مرحله از برنامهزمانبندی اصلی ۱۰۰۰ مرحلهای هستند:
scheduler.timesteps
بیایید ۴ تصویر تصادفی ایجاد کنیم و آنها را از طریق sampling loop اجرا کنیم، هم x فعلی و هم نسخه پیشبینیشده بدون نویز را در طول فرایند مشاهده کنیم:
# The random starting point
x = torch.randn(4, 3, 256, 256).to(device) # Batch of 4, 3-channel 256 x 256 px images
# Loop through the sampling timesteps
for i, t in tqdm(enumerate(scheduler.timesteps)):
# Prepare model input
model_input = scheduler.scale_model_input(x, t)
# Get the prediction
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
# Calculate what the updated sample should look like with the scheduler
scheduler_output = scheduler.step(noise_pred, t, x)
# Update x
x = scheduler_output.prev_sample
# Occasionally display both x and the predicted denoised images
if i % 10 == 0 or i == len(scheduler.timesteps) - 1:
fig, axs = plt.subplots(1, 2, figsize=(12, 5))
grid = torchvision.utils.make_grid(x, nrow=4).permute(1, 2, 0)
axs[0].imshow(grid.cpu().clip(-1, 1) * 0.5 + 0.5)
axs[0].set_title(f"Current x (step {i})")
pred_x0 = scheduler_output.pred_original_sample # Not available for all schedulers
grid = torchvision.utils.make_grid(pred_x0, nrow=4).permute(1, 2, 0)
axs[1].imshow(grid.cpu().clip(-1, 1) * 0.5 + 0.5)
axs[1].set_title(f"Predicted denoised images (step {i})")
plt.show()

همانطور که میبینید، پیشبینیهای اولیه چندان دقیق نیستند، اما با پیش رفتن فرایند، خروجیهای پیشبینیشده رفته رفته بهتر میشوند.
اگر کنجکاو هستید که چه ریاضیات و محاسباتی در داخل تابع step() انجام میشود، میتوانید کد (که به خوبی کامنتگذاری شده است) را بررسی کنید:
# ??scheduler.step
شما همچنین میتوانید این scheduler جدید را جایگزین نمونه اصلی که همراه pipeline بود کنید و به این شکل نمونهگیری کنید:
image_pipe.scheduler = scheduler images = image_pipe(num_inference_steps=40).images images[0]

خوب — حالا میتوانیم نمونهها را در زمان معقولی دریافت کنیم! این باید فرایند را در ادامه نوتبوک سریعتر کند 🙂
فاین تیون کردن (Fine-Tuning) در کتابخانه diffusers
حالا بخش جالب! با داشتن این pipeline از پیش آموزشدیده، چگونه میتوانیم مدل را دوباره آموزش دهیم تا تصاویر را بر اساس دادههای جدید تولید کند؟
مشخص شد که این تقریباً مشابه آموزش مدل از صفر است (همانطور که در بخش قبلی دیدیم)، با این تفاوت که با مدل موجود شروع میکنیم. بیایید این را در عمل ببینیم و در طول مسیر چند نکته اضافی را بررسی کنیم.
ابتدا، مجموعه داده (Dataset):
میتوانید از مجموعه داده چهرههای قدیمی (vintage faces) یا چهرههای انیمه برای چیزی نزدیکتر به دادههای اصلی آموزش این مدل چهره استفاده کنید، اما برای تفنن، بیایید از همان مجموعه داده کوچک پروانهها که در بخش ۱ برای آموزش از صفر استفاده کردیم، بهره ببریم.
کد زیر را اجرا کنید تا مجموعه داده پروانهها دانلود شود و یک dataloader ایجاد شود که بتوانیم یک دسته (batch) از تصاویر را از آن نمونهگیری کنیم:
# @markdown load and prepare a dataset:
# Not on Colab? Comments with #@ enable UI tweaks like headings or user inputs
# but can safely be ignored if you're working on a different platform.
dataset_name = "huggan/smithsonian_butterflies_subset" # @param
dataset = load_dataset(dataset_name, split="train")
image_size = 256 # @param
batch_size = 4 # @param
preprocess = transforms.Compose(
[
transforms.Resize((image_size, image_size)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5], [0.5]),
]
)
def transform(examples):
images = [preprocess(image.convert("RGB")) for image in examples["image"]]
return {"images": images}
dataset.set_transform(transform)
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
print("Previewing batch:")
batch = next(iter(train_dataloader))
grid = torchvision.utils.make_grid(batch["images"], nrow=4)
plt.imshow(grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5)
ملاحظه 1:
اندازه batch ما در اینجا (۴) نسبتاً کوچک است، چون داریم روی تصاویر بزرگ (۲۵۶px) و با یک مدل نسبتاً بزرگ آموزش میدهیم و اگر اندازه batch را خیلی بالا ببریم، رم GPU تمام میشود. میتوانید اندازه تصویر را کاهش دهید تا سرعت آموزش افزایش یابد و امکان استفاده از batchهای بزرگتر فراهم شود، اما این مدلها برای تولید تصاویر ۲۵۶px طراحی و آموزش داده شدهاند.
حالا به training loop میرسیم. ما وزنهای مدل از پیش آموزشدیده را با تعیین هدف به image_pipe.unet.parameters() بهروزرسانی میکنیم.
اجرای این بخش در Colab حدود ۱۰ دقیقه طول میکشد:
num_epochs = 2 # @param
lr = 1e-5 # 2param
grad_accumulation_steps = 2 # @param
optimizer = torch.optim.AdamW(image_pipe.unet.parameters(), lr=lr)
losses = []
for epoch in range(num_epochs):
for step, batch in tqdm(enumerate(train_dataloader), total=len(train_dataloader)):
clean_images = batch["images"].to(device)
# Sample noise to add to the images
noise = torch.randn(clean_images.shape).to(clean_images.device)
bs = clean_images.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(
0,
image_pipe.scheduler.num_train_timesteps,
(bs,),
device=clean_images.device,
).long()
# Add noise to the clean images according to the noise magnitude at each timestep
# (this is the forward diffusion process)
noisy_images = image_pipe.scheduler.add_noise(clean_images, noise, timesteps)
# Get the model prediction for the noise
noise_pred = image_pipe.unet(noisy_images, timesteps, return_dict=False)[0]
# Compare the prediction with the actual noise:
loss = F.mse_loss(
noise_pred, noise
) # NB - trying to predict noise (eps) not (noisy_ims-clean_ims) or just (clean_ims)
# Store for later plotting
losses.append(loss.item())
# Update the model parameters with the optimizer based on this loss
loss.backward(loss)
# Gradient accumulation:
if (step + 1) % grad_accumulation_steps == 0:
optimizer.step()
optimizer.zero_grad()
print(f"Epoch {epoch} average loss: {sum(losses[-len(train_dataloader):])/len(train_dataloader)}")
# Plot the loss curve:
plt.plot(losses)
Epoch 0 average loss: 0.013324214214226231
ملاحظه 2:
نمودار loss ما بسیار نویزی است، چون در هر مرحله فقط با چهار نمونه و سطوح نویز تصادفی کار میکنیم. این وضعیت برای آموزش ایدهآل نیست. یک راه حل این است که از learning rate بسیار پایین استفاده کنیم تا اندازه بهروزرسانی در هر مرحله محدود شود.
اما بهتر است اگر بتوانیم همان مزیت استفاده از batch بزرگتر را بدون نیاز به حافظه اضافی به دست آوریم…
اینجاست که gradient accumulation وارد میشود.
اگر قبل از اجرای optimizer.step() و optimizer.zero_grad() چندین بار loss.backward() را صدا بزنیم، PyTorch گرادیانها را جمع میکند و در واقع سیگنال چند batch را با هم ترکیب میکند تا یک تخمین بهتر به دست آید، که سپس برای بهروزرسانی پارامترها استفاده میشود. این باعث میشود تعداد کل بهروزرسانیها کاهش یابد، درست مثل زمانی که از batch بزرگتر استفاده میکردیم.
بسیاری از فریمورکها این کار را برای شما ساده میکنند (مثلاً Accelerate)، اما دیدن پیادهسازی آن از صفر مفید است، چون تکنیک کاربردی برای آموزش با محدودیت حافظه GPU است!
همانطور که از کد بالا (بعد از کامنت # Gradient accumulation) میبینید، نیازی به کد زیادی نیست.
ملاحظه 3:
این کار هنوز زمان زیادی میبرد و چاپ یک بهروزرسانی تکخطی در هر epoch بازخورد کافی برای فهمیدن وضعیت آموزش به ما نمیدهد. بهتر است کارهای زیر را انجام دهیم:
-
گاهی اوقات چند نمونه تولید کنیم تا عملکرد مدل را بهصورت کیفی و بصری بررسی کنیم.
-
مقادیری مثل loss و تولید نمونهها را در طول آموزش ثبت (log) کنیم، مثلاً با استفاده از Weights & Biases یا TensorBoard.
یک اسکریپت سریع (finetune_model.py) وجود دارد که کد آموزش بالا را گرفته و حداقل قابلیت logging را اضافه میکند. شما میتوانید لاگهای یک اجرای آموزشی را در زیر مشاهده کنید:
%wandb johnowhitaker/dm_finetune/2upaa341 # You'll need a W&B account for this to work - skip if you don't want to log in
جالب است که ببینیم نمونههای تولیدشده چگونه با پیشرفت آموزش تغییر میکنند — حتی اگر loss چندان بهبود پیدا نکند، میتوانیم حرکتی از دامنه اصلی (تصاویر اتاقخواب) به سمت دادههای جدید آموزشی (WikiArt) را مشاهده کنیم.
در انتهای این نوتبوک، کدی که کامنت شده است برای فاینتیون کردن مدل با استفاده از این اسکریپت قرار دارد، بهعنوان جایگزینی برای اجرای سلول بالا.
# Exercise: see if you can modify the official example training script we saw # in Unit 1 to begin with a pre-trained model rather than training from scratch. # Compare it to the minimal script linked above - what extra features is the minimal script missing?
با تولید چند تصویر با این مدل، میتوان دید که چهرهها کمی عجیب و غریب به نظر میرسند!
# @markdown Generate and plot some images:
x = torch.randn(8, 3, 256, 256).to(device) # Batch of 8
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x, nrow=4)
plt.imshow(grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5)

ملاحظه 4:
فاینتیون کردن میتواند کاملاً غیرقابل پیشبینی باشد! اگر مدت زمان طولانیتری آموزش میدادیم، شاید نمونههای پروانه کامل و عالی میدیدیم. اما مراحل میانی خودشان میتوانند بسیار جالب باشند، به ویژه اگر علاقه شما بیشتر به جنبه هنری باشد!
میتوانید آموزش کوتاه یا طولانی و تغییر نرخ یادگیری (learning rate) را امتحان کنید تا ببینید چگونه بر نوع خروجی مدل نهایی تأثیر میگذارد.
کد فاینتیون کردن مدل با استفاده از اسکریپت حداقلی که در مثال WikiArt استفاده کردیم:
اگر میخواهید مدلی مشابه مدلی که من روی WikiArt ساختهام آموزش دهید، میتوانید سلولهای زیر را از حالت کامنت خارج کرده و اجرا کنید. از آنجا که این کار زمانبر است و ممکن است حافظه GPU شما را پر کند، توصیه میکنم این کار را بعد از پیش رفتن در بقیه نوتبوک انجام دهید
## To download the fine-tuning script: # !wget https://github.com/huggingface/diffusion-models-class/raw/main/unit2/finetune_model.py
## To run the script, training the face model on some vintage faces ## (ideally run this in a terminal): # !python finetune_model.py --image_size 128 --batch_size 8 --num_epochs 16\ # --grad_accumulation_steps 2 --start_model "google/ddpm-celebahq-256"\ # --dataset_name "Norod78/Vintage-Faces-FFHQAligned" --wandb_project 'dm-finetune'\ # --log_samples_every 100 --save_model_every 1000 --model_save_name 'vintageface'
ذخیره و بارگذاری Pipelineهای فاینتیون شده
حالا که U-Net مدل دیفیوژن خود را فاینتیون کردهایم، بیایید آن را با اجرای دستور زیر در یک پوشه ذخیره کنیم:
image_pipe.save_pretrained("my-finetuned-model")
کما آنکه در بخش گذشته دیدیم این کار مدل، config و scheduler را سیو میکند
!ls {"my-finetuned-model"}
model_index.json scheduler unet
سپس میتوانید همان مراحل که قبلا توضیح داده شد را دنبال کنید تا مدل را برای استفاده بعدی به Hub منتقل کنید:
# @title Upload a locally saved pipeline to the hub
# Code to upload a pipeline saved locally to the hub
from huggingface_hub import HfApi, ModelCard, create_repo, get_full_repo_name
# Set up repo and upload files
model_name = "ddpm-celebahq-finetuned-butterflies-2epochs" # @param What you want it called on the hub
local_folder_name = (
"my-finetuned-model" # @param Created by the script or one you created via image_pipe.save_pretrained('save_name')
)
description = "Describe your model here" # @param
hub_model_id = get_full_repo_name(model_name)
create_repo(hub_model_id)
api = HfApi()
api.upload_folder(folder_path=f"{local_folder_name}/scheduler", path_in_repo="", repo_id=hub_model_id)
api.upload_folder(folder_path=f"{local_folder_name}/unet", path_in_repo="", repo_id=hub_model_id)
api.upload_file(
path_or_fileobj=f"{local_folder_name}/model_index.json",
path_in_repo="model_index.json",
repo_id=hub_model_id,
)
# Add a model card (optional but nice!)
content = f"""
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Example Fine-Tuned Model for Unit 2 of the [Diffusion Models Class ](https://github.com/huggingface/diffusion-models-class)
{description}
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('{hub_model_id}')
image = pipeline().images[0]
image
تبریک! شما اولین مدل دیفیوژن (diffusion model) خود را فاینتیون کردید!
برای بقیه این نوتبوک، از مدلی استفاده خواهیم کرد که آن روی این مدل آموزشدیده روی LSUN bedrooms تقریباً یک epoch روی مجموعه داده WikiArt فاینتیون شده است.
اگر بخواهید، میتوانید این سلول را رد کنید و از pipeline چهرهها/پروانهها که در بخش قبلی فاینتیون کردیم استفاده کنید، یا یکی دیگر را از Hub بارگذاری نمایید:
# Load the pretrained pipeline
pipeline_name = "johnowhitaker/sd-class-wikiart-from-bedrooms"
image_pipe = DDPMPipeline.from_pretrained(pipeline_name).to(device)
# Sample some images with a DDIM Scheduler over 40 steps
scheduler = DDIMScheduler.from_pretrained(pipeline_name)
scheduler.set_timesteps(num_inference_steps=40)
# Random starting point (batch of 8 images)
x = torch.randn(8, 3, 256, 256).to(device)
# Minimal sampling loop
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
x = scheduler.step(noise_pred, t, x).prev_sample
# View the results
grid = torchvision.utils.make_grid(x, nrow=4)
plt.imshow(grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5)

Guidance در کتابخانه diffusers
اگر بخواهیم کنترلی روی نمونههای تولیدشده داشته باشیم چه کاری انجام دهیم؟
بهعنوان مثال، فرض کنید میخواهیم تصاویر تولیدشده به رنگ خاصی تمایل داشته باشند. چگونه این کار را انجام دهیم؟
اینجاست که guidance وارد میشود، تکنیکی برای افزودن کنترل بیشتر به فرآیند نمونهگیری.
مرحله اول ایجاد تابع conditioning است: معیاری (loss) که میخواهیم حداقل شود.
در اینجا یک مثال برای رنگ داریم، که پیکسلهای تصویر را با یک رنگ هدف (بهصورت پیشفرض teal روشن) مقایسه میکند و میانگین خطا را بازمیگرداند:
def color_loss(images, target_color=(0.1, 0.9, 0.5)):
"""Given a target color (R, G, B) return a loss for how far away on average
the images' pixels are from that color. Defaults to a light teal: (0.1, 0.9, 0.5)"""
target = torch.tensor(target_color).to(images.device) * 2 - 1 # Map target color to (-1, 1)
target = target[None, :, None, None] # Get shape right to work with the images (b, c, h, w)
error = torch.abs(images - target).mean() # Mean absolute difference between the image pixels and the target color
return error
سپس یک نسخه اصلاحشده از حلقه نمونهگیری میسازیم که در هر مرحله کارهای زیر را انجام میدهد:
-
یک نسخه جدید از x ایجاد میکنیم که
requires_grad = Trueباشد. -
نسخه بدون نویز (x0) را محاسبه میکنیم.
-
خروجی پیشبینیشده x0 را از طریق تابع loss خود عبور میدهیم.
-
گرادیان این تابع loss نسبت به x را پیدا میکنیم.
-
از این گرادیان conditioning استفاده میکنیم تا x را قبل از اجرای گام بعدی با scheduler اصلاح کنیم، با این امید که x را به سمتی هدایت کند که loss کاهش یابد طبق تابع guidance ما.
دو نوع متد برای این کار وجود دارد که میتوانید آنها را بررسی کنید:
-
در نوع اول، بعد از اینکه پیشبینی نویز از UNet را گرفتیم،
requires_gradروی x قرار میدهیم. این روش حافظه کمتری مصرف میکند (چون نیازی نیست گرادیانها را از طریق مدل انتشار trace کنیم)، اما گرادیان کمتر دقیقی میدهد. -
در نوع دوم، ابتدا
requires_gradرا روی x قرار میدهیم، سپس آن را از طریق UNet عبور داده و x0 پیشبینیشده را محاسبه میکنیم.
# Variant 1: shortcut method
# The guidance scale determines the strength of the effect
guidance_loss_scale = 40 # Explore changing this to 5, or 100
x = torch.randn(8, 3, 256, 256).to(device)
for i, t in tqdm(enumerate(scheduler.timesteps)):
# Prepare the model input
model_input = scheduler.scale_model_input(x, t)
# predict the noise residual
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
# Set x.requires_grad to True
x = x.detach().requires_grad_()
# Get the predicted x0
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
# Calculate loss
loss = color_loss(x0) * guidance_loss_scale
if i % 10 == 0:
print(i, "loss:", loss.item())
# Get gradient
cond_grad = -torch.autograd.grad(loss, x)[0]
# Modify x based on this gradient
x = x.detach() + cond_grad
# Now step with scheduler
x = scheduler.step(noise_pred, t, x).prev_sample
# View the output
grid = torchvision.utils.make_grid(x, nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
Image.fromarray(np.array(im * 255).astype(np.uint8))
0 loss: 27.279136657714844 10 loss: 11.286816596984863 20 loss: 10.683112144470215 30 loss: 10.942476272583008
این گزینه دوم تقریباً دو برابر حافظه GPU نیاز دارد، حتی اگر ما فقط یک batch چهار تایی تولید کنیم و نه هشت تایی.
تلاش کنید تفاوت را پیدا کنید و فکر کنید چرا این روش دقیقتر است:
# Variant 2: setting x.requires_grad before calculating the model predictions
guidance_loss_scale = 40
x = torch.randn(4, 3, 256, 256).to(device)
for i, t in tqdm(enumerate(scheduler.timesteps)):
# Set requires_grad before the model forward pass
x = x.detach().requires_grad_()
model_input = scheduler.scale_model_input(x, t)
# predict (with grad this time)
noise_pred = image_pipe.unet(model_input, t)["sample"]
# Get the predicted x0:
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
# Calculate loss
loss = color_loss(x0) * guidance_loss_scale
if i % 10 == 0:
print(i, "loss:", loss.item())
# Get gradient
cond_grad = -torch.autograd.grad(loss, x)[0]
# Modify x based on this gradient
x = x.detach() + cond_grad
# Now step with scheduler
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x, nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
Image.fromarray(np.array(im * 255).astype(np.uint8))
0 loss: 30.750328063964844 10 loss: 18.550724029541016 20 loss: 17.515094757080078 30 loss: 17.55681037902832
در نوع دوم، نیاز به حافظه بالاتر است و اثر کمتر محسوس است، بنابراین ممکن است فکر کنید این روش ضعیفتر است. با این حال، خروجیها نزدیکتر به نوع تصاویری هستند که مدل روی آنها آموزش دیده است و همیشه میتوانید guidance scale را افزایش دهید تا اثر قویتری داشته باشید. در نهایت، انتخاب روش به این بستگی دارد که کدام یک در عمل بهتر عمل میکند.
# Exercise: pick your favourite colour and look up it's values in RGB space. # Edit the `color_loss()` line in the cell above to receive these new RGB values and examine the outputs - do they match what you expect?
CLIP Guidance
هدایت کردن مدل به سمت یک رنگ، کمی کنترل به ما میدهد، اما اگر بتوانیم متنی که توصیف میکند چه چیزی میخواهیم را وارد کنیم چه؟
CLIP مدلی است که توسط OpenAI ساخته شده و اجازه میدهد تصاویر را با کپشنهای متنی مقایسه کنیم. این فوقالعاده قدرتمند است، زیرا امکان سنجش میزان تطابق یک تصویر با یک prompt را فراهم میکند. و از آنجا که این فرآیند قابل مشتقگیری (differentiable) است، میتوانیم آن را به عنوان تابع loss برای هدایت مدل انتشار خود استفاده کنیم!
جزئیات زیادی ارائه نمیکنیم، اما روش پایه به شرح زیر است:
-
متن prompt را embed میکنیم تا یک embedding ۵۱۲ بعدی CLIP از متن بدست آید.
-
برای هر مرحله در فرآیند مدل انتشار:
-
چندین نسخه متغیر از تصویر پیشبینیشده بدون نویز میسازیم (داشتن چندین نسخه، سیگنال loss تمیزتری میدهد).
-
برای هر نسخه، تصویر را با CLIP embed میکنیم و این embedding را با embedding متنی prompt مقایسه میکنیم (با استفاده از معیاری به نام Great Circle Distance Squared).
-
-
گرادیان این loss نسبت به x نویزی فعلی را محاسبه میکنیم و از آن برای اصلاح x قبل از بهروزرسانی با scheduler استفاده میکنیم.
سلول بعدی را اجرا کنید تا یک مدل CLIP بارگذاری شود:
# @markdown load a CLIP model and define the loss function
import open_clip
clip_model, _, preprocess = open_clip.create_model_and_transforms("ViT-B-32", pretrained="openai")
clip_model.to(device)
# Transforms to resize and augment an image + normalize to match CLIP's training data
tfms = torchvision.transforms.Compose(
[
torchvision.transforms.RandomResizedCrop(224), # Random CROP each time
torchvision.transforms.RandomAffine(5), # One possible random augmentation: skews the image
torchvision.transforms.RandomHorizontalFlip(), # You can add additional augmentations if you like
torchvision.transforms.Normalize(
mean=(0.48145466, 0.4578275, 0.40821073),
std=(0.26862954, 0.26130258, 0.27577711),
),
]
)
# And define a loss function that takes an image, embeds it and compares with
# the text features of the prompt
def clip_loss(image, text_features):
image_features = clip_model.encode_image(tfms(image)) # Note: applies the above transforms
input_normed = torch.nn.functional.normalize(image_features.unsqueeze(1), dim=2)
embed_normed = torch.nn.functional.normalize(text_features.unsqueeze(0), dim=2)
dists = input_normed.sub(embed_normed).norm(dim=2).div(2).arcsin().pow(2).mul(2) # Squared Great Circle Distance
return dists.mean()
پس از تعریف یک تابع loss، حلقه نمونهگیری هدایتشده ما شبیه مثالهای قبلی خواهد بود، با این تفاوت که color_loss() با تابع loss مبتنی بر CLIP جایگزین میشود:
# @markdown applying guidance using CLIP
prompt = "Red Rose (still life), red flower painting" # @param
# Explore changing this
guidance_scale = 8 # @param
n_cuts = 4 # @param
# More steps -> more time for the guidance to have an effect
scheduler.set_timesteps(50)
# We embed a prompt with CLIP as our target
text = open_clip.tokenize([prompt]).to(device)
with torch.no_grad(), torch.cuda.amp.autocast():
text_features = clip_model.encode_text(text)
x = torch.randn(4, 3, 256, 256).to(device) # RAM usage is high, you may want only 1 image at a time
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
# predict the noise residual
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
cond_grad = 0
for cut in range(n_cuts):
# Set requires grad on x
x = x.detach().requires_grad_()
# Get the predicted x0:
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
# Calculate loss
loss = clip_loss(x0, text_features) * guidance_scale
# Get gradient (scale by n_cuts since we want the average)
cond_grad -= torch.autograd.grad(loss, x)[0] / n_cuts
if i % 25 == 0:
print("Step:", i, ", Guidance loss:", loss.item())
# Modify x based on this gradient
alpha_bar = scheduler.alphas_cumprod[i]
x = x.detach() + cond_grad * alpha_bar.sqrt() # Note the additional scaling factor here!
# Now step with scheduler
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x.detach(), nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
Image.fromarray(np.array(im * 255).astype(np.uint8))
Step: 0 , Guidance loss: 7.437869548797607 Step: 25 , Guidance loss: 7.174620628356934
اینها کمی شبیه گل رز به نظر میرسند! کامل نیست، اما اگر با تنظیمات بازی کنید میتوانید تصاویر خوشایندی تولید کنید.
اگر کد بالا را بررسی کنید، میبینید که من گرادیان conditioning را با alpha_bar.sqrt() مقیاسبندی کردهام. نظریههایی وجود دارد که نشان میدهد روش درست برای مقیاسدهی این گرادیانها چیست، اما در عمل این هم چیزی است که میتوانید با آن آزمایش کنید.
برای برخی انواع guidance، ممکن است بخواهید بیشترین اثر در مراحل اولیه متمرکز باشد، و برای دیگر موارد (مثلاً loss سبک که روی بافتها تمرکز دارد)، ترجیح دهید که اثر آنها تنها در پایان فرآیند تولید فعال شود.
چند برنامه زمانبندی ممکن در ادامه نشان داده شدهاند:
# @markdown Plotting some possible schedules:
plt.plot([1 for a in scheduler.alphas_cumprod], label="no scaling")
plt.plot([a for a in scheduler.alphas_cumprod], label="alpha_bar")
plt.plot([a.sqrt() for a in scheduler.alphas_cumprod], label="alpha_bar.sqrt()")
plt.plot([(1 - a).sqrt() for a in scheduler.alphas_cumprod], label="(1-alpha_bar).sqrt()")
plt.legend()
plt.title("Possible guidance scaling schedules")
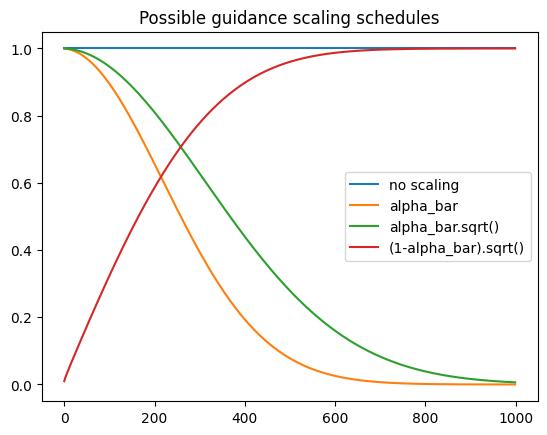
با آزمایش برنامههای زمانبندی مختلف، مقیاسهای guidance و هر ترفندی که به ذهنتان میرسد (مثلاً محدود کردن گرادیانها در یک بازه مشخص که تغییر متداولی است)، ببینید تا چه حد میتوانید تصاویر خوبی تولید کنید! همچنین حتماً مدلهای دیگر را هم جایگزین کنید. شاید مدل چهرهای که در ابتدا بارگذاری کردیم — آیا میتوانید آن را به طور قابل اعتماد هدایت کنید تا یک چهره مردانه تولید کند؟ اگر guidance مبتنی بر CLIP را با color loss قبلی ترکیب کنید چه میشود؟ و غیره.
اگر کد CLIP-guided diffusion را بررسی کنید، خواهید دید که رویکرد پیچیدهتری وجود دارد: با یک کلاس بهتر برای انتخاب برشهای تصادفی از تصاویر و تعدیلات زیادی در تابع loss برای عملکرد بهتر. قبل از ظهور مدلهای انتشار متن-به-تصویر، این بهترین سیستم تبدیل متن به تصویر بود! نسخه کوچک و آموزشی ما جای زیادی برای بهبود دارد، اما ایده اصلی را نشان میدهد: با ترکیب guidance و قابلیتهای شگفتانگیز CLIP، میتوانیم کنترل متنی به یک مدل انتشار بدون شرط اضافه کنیم .
اشتراکگذاری یک حلقه نمونهگیری سفارشی به عنوان دمو با Gradio
شاید شما یک تابع loss جالب برای هدایت تولید پیدا کرده باشید و حالا میخواهید هم مدل fine-tuned خود و هم این استراتژی نمونهگیری سفارشی را با دیگران به اشتراک بگذارید…
اینجاست که Gradio وارد میشود. Gradio یک ابزار رایگان و متنباز است که به کاربران اجازه میدهد به راحتی مدلهای یادگیری ماشین تعاملی را از طریق یک رابط وب ساده ایجاد و به اشتراک بگذارند. با Gradio، کاربران میتوانند رابطهای سفارشی برای مدلهای خود بسازند و سپس این رابطها را از طریق یک URL منحصر به فرد با دیگران به اشتراک بگذارند. همچنین Gradio در Spaces ادغام شده که میزبانی دموها و اشتراک آنها را آسان میکند.
ما منطق اصلی را در یک تابع قرار میدهیم که چند ورودی میگیرد و یک تصویر به عنوان خروجی تولید میکند. سپس این تابع را میتوان در یک رابط ساده قرار داد که به کاربر اجازه میدهد برخی پارامترها را مشخص کند (که به عنوان ورودی به تابع اصلی generate منتقل میشوند). برای این مثال، ما از slider برای guidance scale و یک color picker برای تعیین رنگ هدف استفاده خواهیم کرد.
%pip install -q gradio # Install the library
import gradio as gr
from PIL import Image, ImageColor
# The function that does the hard work
def generate(color, guidance_loss_scale):
target_color = ImageColor.getcolor(color, "RGB") # Target color as RGB
target_color = [a / 255 for a in target_color] # Rescale from (0, 255) to (0, 1)
x = torch.randn(1, 3, 256, 256).to(device)
for i, t in tqdm(enumerate(scheduler.timesteps)):
model_input = scheduler.scale_model_input(x, t)
with torch.no_grad():
noise_pred = image_pipe.unet(model_input, t)["sample"]
x = x.detach().requires_grad_()
x0 = scheduler.step(noise_pred, t, x).pred_original_sample
loss = color_loss(x0, target_color) * guidance_loss_scale
cond_grad = -torch.autograd.grad(loss, x)[0]
x = x.detach() + cond_grad
x = scheduler.step(noise_pred, t, x).prev_sample
grid = torchvision.utils.make_grid(x, nrow=4)
im = grid.permute(1, 2, 0).cpu().clip(-1, 1) * 0.5 + 0.5
im = Image.fromarray(np.array(im * 255).astype(np.uint8))
im.save("test.jpeg")
return im
# See the gradio docs for the types of inputs and outputs available
inputs = [
gr.ColorPicker(label="color", value="55FFAA"), # Add any inputs you need here
gr.Slider(label="guidance_scale", minimum=0, maximum=30, value=3),
]
outputs = gr.Image(label="result")
# And the minimal interface
demo = gr.Interface(
fn=generate,
inputs=inputs,
outputs=outputs,
examples=[
["#BB2266", 3],
["#44CCAA", 5], # You can provide some example inputs to get people started
],
)
demo.launch(debug=True) # debug=True allows you to see errors and output in Colab
امکان ساخت رابطهای بسیار پیچیدهتر با استایل جذاب و انواع ورودیهای مختلف وجود دارد، اما برای این دمو ما آن را تا حد امکان ساده نگه میداریم.
دموها در Spaces به طور پیشفرض روی CPU اجرا میشوند، بنابراین خوب است که ابتدا رابط خود را در Colab نمونهسازی کنید (همانطور که بالاتر نشان داده شد) قبل از اینکه به Spaces منتقل کنید.
وقتی آماده اشتراکگذاری دمو هستید:
-
یک Space ایجاد میکنید
-
یک فایل requirements.txt شامل کتابخانههای مورد نیاز خود میسازید
-
سپس تمام کدها را در یک فایل app.py قرار میدهید که توابع و رابطهای مرتبط را تعریف میکند.
خوشبختانه، یک گزینهی دیگر هم وجود دارد: میتوانید یک Space را Duplicate کنید. میتوانید به این دمو اسپیس که بالاتر نشان داده شد مراجعه کنید و روی ‘Duplicate this Space’ کلیک کنید تا یک قالب دریافت کنید که بعداً میتوانید آن را ویرایش کرده و از مدل و تابع guidance خود استفاده کنید.
در تنظیمات، میتوانید اسپیس خود را برای اجرا روی سختافزار قویتر پیکربندی کنید (که بهصورت ساعتی هزینه دارد)
خلاصه و گامهای بعدی
در این آموزش مطالب زیادی پوشش داده شد. بیایید ایدههای اصلی را مرور کنیم:
-
بارگذاری مدلهای موجود و نمونهگیری با schedulerهای مختلف نسبتاً آسان است
-
Fine-tuning تقریباً شبیه آموزش از صفر است، با این تفاوت که با شروع از یک مدل موجود، انتظار داریم نتایج بهتر و سریعتر حاصل شود
-
برای fine-tune کردن مدلهای بزرگ روی تصاویر بزرگ، میتوان از تکنیکهایی مثل gradient accumulation برای عبور از محدودیتهای اندازه batch استفاده کرد
-
ثبت تصاویر نمونه برای fine-tuning مهم است، زیرا منحنی loss ممکن است اطلاعات مفیدی نشان ندهد
-
Guidance به ما اجازه میدهد که مدلهای بدون شرط را بر اساس یک تابع guidance/loss هدایت کنیم؛ در هر مرحله گرادیان loss نسبت به تصویر نویزی x محاسبه شده و قبل از رفتن به timestep بعدی، بر اساس آن بهروزرسانی میشود
-
CLIP Guidance به ما امکان میدهد مدلهای بدون شرط را با متن کنترل کنیم!
گامهای عملی بعدی:
-
مدل خود را fine-tune کنید و به Hub ارسال کنید. این شامل انتخاب نقطه شروع (مثلاً مدلی که روی چهرهها، اتاقها، گربهها یا مثال WikiArt آموزش دیده است) و یک dataset (مثل تصاویر حیوانات یا تصاویر خودتان) و سپس اجرای کد این نوتبوک یا اسکریپت نمونه است.
-
با مدل fine-tuned خود، guidance را امتحان کنید، چه با یکی از توابع نمونه (color_loss یا CLIP) و چه با ساخت تابع guidance خودتان.
-
یک دمو با Gradio بسازید، یا با تغییر دادن Space نمونه برای استفاده از مدل خودتان، یا ایجاد نسخه سفارشی با امکانات بیشتر.
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

دیدگاهتان را بنویسید