بهینهسازی بدون هایپرپارامتر!
در یادگیری عمیق، در زمان آموزش یک شبکه عصبی یا Neural Network، این شبکهها معمولاً وزنهای خود را بر اساس یک بهینهساز که با استفاده از هایپرپارامترهای دستچین شده تنظیم میشود، بهروزرسانی میکنند. روشی که به تازگی معرفی شده است، نیاز به انتخاب هایپرپارامتر برای بهینهسازی را از بین میرود.
روش پیشنهادی: Luke Metz و James Harrison و همکارانشان در گوگل، VeLO را ابداع کردند، یک سیستم که طراحیشده است تا به عنوان یک بهینهساز کاملا تنظیمشده عمل کند. در واقع VeLO از یک شبکهی عصبی برای محاسبه بهروزرسانیهای شبکه هدف استفاده میکند.

نکات کلیدی: توسعهدهندگان روشهای یادگیری ماشین، معمولاً بهترین مقادیر برای هایپرپارامترهای بهینهساز، مانند نرخ یادگیری یا learning rate، تنظیمکنندهی نرخ یادگیری یا scheduler و ضریب کاستن وزن یا weight decay را با آزمون و خطا پیدا میکنند. این روش میتواند بسیار زمانبر باشد، چرا که نیاز به آموزش مکرر شبکهی هدف با استفاده از مقادیر متفاوتی برای هایپرپارامترها دارد. در روش پیشنهادی جدید، یک شبکهی عصبی متفاوت از شبکهی هدف، گرادیانها، وزنها و مرحلهی فعلی آموزش شبکهی هدف را دریافت میکند و در خروجی مقادیر مربوط به بهروزرسانیهای وزن آن شبکه را تولید میکند؛ این فرایند، بدون نیاز به تنظیم کردن مقادیر هایپرپارامترها صورت میگیرد.
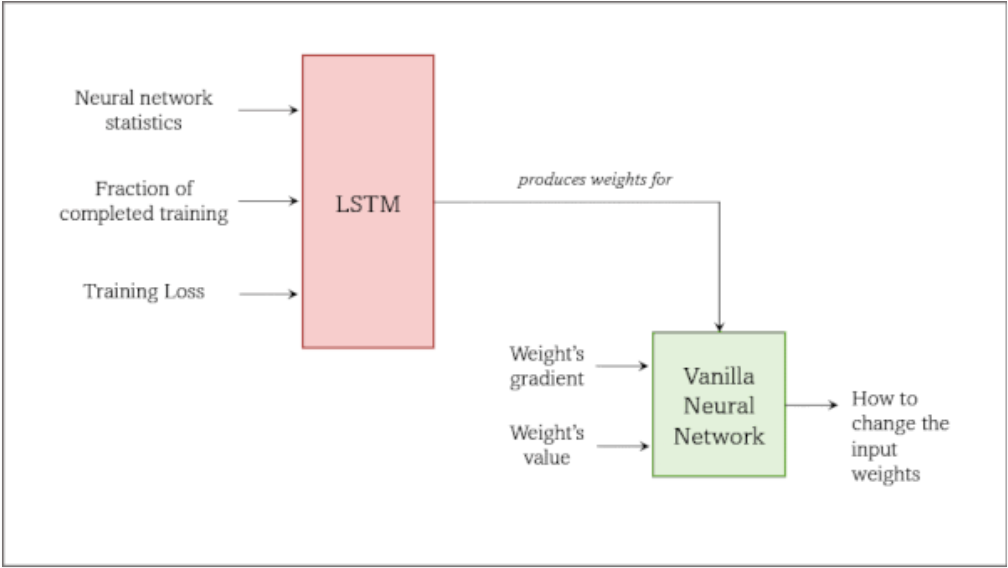
روش کار بهینهساز: در هر مرحله از آموزش شبکه هدف، یک شبکهی LSTM، وزنهای یک شبکهی عصبی ساده یا Vanilla Neural Network را تولید میکند که ما آن را شبکهی بهینهساز مینامیم. سپس شبکهی بهینهساز در مقابل وزنهای شبکهی هدف را بهروزرسانی میکند. شبکهی LSTM آموزش دیده است که وزنهای شبکهی بهینهساز را از طریق فرایند تکامل تولید کند؛ بهجای استفاده از روش back-propagation، تعداد زیادی شبکهی LSTM مشابه با تفاوتهای جزئی تصادفی تولید میشوند، سپس پارامترهای این مدلها بر اساس بهترین عملکردها میانگین گرفته میشوند و در ادامه شبکههای عصبی جدید، نزدیکتر به میانگین و برای تکرار این فرآیند ایجاد میشوند.
- توسعهدهندگان در این روش، به طور تصادفی تعداد زیادی (در حدود 100،000) شبکهی عصبی هدف را با معماریهای مختلف، مانند شبکههای عصبی ساده (Vanilla)، شبکههای عصبی پیچشی (Convolutional)، شبکههای عصبی بازگشتی (Recurrent)، ترنسفورمرها (Transformer) و غیره ایجاد کردند تا برای اهداف گستردهای مانند طبقهبندی تصاویر یا تولید متن آموزش ببینند.
- آنها وزنهای یک شبکهی LSTM (که در ابتدا با وزنهای تصادفی ایجاد شده است) را کپی کردند و وزنهای آن را به صورت تصادفی برای هر تسک هدف تغییر دادند. هر شبکهی LSTM وزنهای یک شبکهی عصبی ساده (Vanilla) را بر اساس آمار و ارقام شبکهی هدف تولید میکند. این آمار شامل میانگین و واریانس وزنهای آن شبکه، میانگین متحرک نمایی (exponential moving average) گرادیانها در طول آموزش، مرحلهی فعلی آموزش و مقدار تابع هزینه در آن مرحله است.
- سپس آنها هر شبکهی هدف را برای تعداد بار ثابتی با استفاده از شبکهی بهینهساز آن آموزش دادند. شبکهی بهینهساز، گرادیانها، وزنها و مرحلهی فعلی آموزش شبکهی هدف را دریافت میکند و سپس هر وزن را یک به یک بهروزرسانی میکند. هدف آن به حداقل رساندن تابع ضرر برای تسک هدف است. خروجی آموزش در هر مرحله، یک شبکهی LSTM و مقدار تابع هزینه است.
- توسعهدهندگان یک شبکهی LSTM جدید با استفاده از میانگین وزندار (مقدار تابع هزینهی کمتر، وزن بیشتر) برای هر وزن در تمام LSTMها و بین تمامی تسکها ایجاد میکنند؛ سپس روند را با استفاده از شبکهی LSTM جدید تکرار میکنند: آنها LSTM جدید را کپی میکنند و سپس تغییرات تصادفی بر روی آن اعمال میکنند تا شبکههای بهینهساز جدید تولید شوند و دوباره از آنها برای آموزش شبکههای هدف جدید استفاده میکنند و الی آخر.
نتایج: نویسندگان VeLO را با استفاده از مجموعه دادههایی ارزیابی کردند تا برای هر یک از ۸۳ تسک مختلف، تنها به یک ساعت آموزش بر روی یک GPU نیاز داشته باشند. آنها این روش را برای مجموعه جدیدی از معماریهای شبکه عصبی که به طور تصادفی تولید می شوند، اعمال کردند. در تمام تسکها، VeLO شبکهها را سریعتر از پیدا کردن بهترین نرخ یادگیری با استفاده از بهینهساز Adam آموزش داد (در نیمی از وظائف، تا ۴ برابر سریعتر). همچنین در پنج مورد از شش تسک معمول یادگیریماشین که شامل طبقهبندی تصاویر، تشخیص گفتار، ترجمه متن و طبقهبندی گراف است، به تابع هزینهی کمتری نسبت به استفاده از بهینهسازی Adam رسید.
اما: رویکرد نویسندگان دقیقاً در جایی که بهینهسازها برای تنظیم دستی در پرهزینهترین حالت خود هستند، مانند مدلهای دارای بیش از ۵۰۰ میلیون پارامتر و مدلهایی که به بیش از ۲۰۰،۰۰۰ مرحله آموزشی نیاز دارند، عملکرد ضعیفی داشت. توجیه نویسندگان برای این اتفاق آموزش ندیدن VeLO در شبکههایی نظیر شبکههای اشارهشده بود.
اهمیت این روش: VeLO توسعه مدلها را به دو طریق تسریع میکند: نیاز به آزمایش مقادير مختلف برای هایپرپارامترها را از بین میبرد و سرعت خود بهینهساز را هم بهبود میبخشد. این روش، در مقایسه با سایر بهینهسازها، از مشخصههای آماری بیشتری از شبکهی هدف به صورت لحظه به لحظه بهره میبرد. همچنین، به این بهینهساز این امکان را میدهد تا مدلها را به راه حل مناسب تسک مورد نظر نزدیکتر کند.
نتیجهگیری ما: به نظر میرسد که VeLO به روی تسکهایی با اندازههای انتخاب شده توسط توسعهدهندگان آن، overfit شده است و در مقایسه به نظر می رسد الگوریتم های نسبتاً سادهای مانند Adam برای انواع گستردهتری از شبکههای عصبی مناسب هستند. ما مشتاقانه منتظر الگوریتمهایی مشابه الگوریتم VeLO هستیم که در معماریهای بزرگتر و نیازمند مراحل آموزشی بیشتر، عملکرد بهتری داشته باشند. بهرحال، به نظر نمیرسد که در حال حاضر شبکههای عصبی بتوانند جایگزین سایر روشهای بهینهسازی شوند.
منبع:
https://www.deeplearning.ai/the-batch/velo-the-system-that-eliminates-the-need-for-optimizer-hyperparameters/?utm_campaign=The%20Batch&utm_content=258012456&utm_medium=social&utm_source=linkedin&hss_channel=lcp-18246783
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 1

راهنمای قدم به قدم کرایه کارت گرافیک (GPU) با Vast.ai برای پروژههای هوش مصنوعی

دیدگاهتان را بنویسید