شبکه عصبی
این متن نیاز به ویرایش دارد
مقدمه:
شبکه عصبی مصنوعی سیستمهایی هستند که از فرآیند یادگیری کشف شده در شبکهی عصبی موجود در مغز انسان الهام گرفته است. مغز انسان شامل تعداد زیادی از سلول های عصبی است که توانایی پردازش اطلاعات را دارند. همانگونه که در شکل 1 مشاهده میشود هر سلول متشکل از یک جسم سلولی (سوما[1]) است که شامل هسته سلول است.
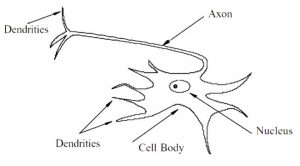
شکل 1 بخش هایی از نورون
اطلاعات بین نورونها در طول دندریت[2]ها در قالب پتانسیل الکتریکی منتقل میشود. اگر پتانسیل به یک آستانه خاص برسد، نورون دستور فعال شدن را صادر میکند(آتش[3]) و اطلاعات در امتداد آکسون به دندریتها ارسال میشود، جایی که اطلاعات به نورون دیگر فرستاده میشوند.
مانند مغز انسان، یک شبکه عصبی مصنوعی قادر به پردازش اطلاعات با استفاده از اتصال چند واحد نسبتا سادهی پردازش اطلاعات است؛ که هر واحد برای برقراری ارتباط با یکدیگر از طریق سیگنالها عمل میکنند. هر لینک دارای وزنی است که به لینکها نسبت داده شدهاند. این لینکها ابزار پایهای برای ذخیرهسازی طولانی مدت اطلاعات در شبکههای عصبی محسوب میشود. این وزنها در طول فرآیند یادگیری به روز میشوند.
شبکه های عصبی مصنوعی
رابطهی زیر نوعی ساختار از یک واحد پرسپترون را نشان میدهد.
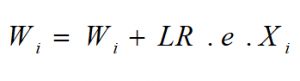
در این رابطه xi بردار ورودی و f یک تابع فعالساز است، W بردار وزنها است که با استفاده از آن خروجی محاسبه میشود.
تابع فعال ساز یا فعالیت
تابع فعالساز f میتواند بسته به نوع مساله به صورت دلخواه انتخاب شود، از رایجترین توابع فعالساز میتوان به توابع سیگموید، Tanh و Relu میتوان اشاره نمود. هدف اصلی تابع فعالیت غیر خطی سازی است.
آموزش شبکه پرسپترون
برای آموزش، وزن های شبکه بهصورت تصادفی مقداردهی شده و با رابطهی زیر وزنها به روز میشوند.
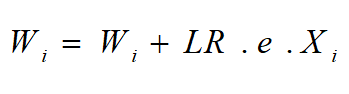
در رابطهی مذکور LR نرخ یادگیری بوده و عددی در بازه (0,1] است، همچنین e میزان خطای شبکه با ورودی جاری X است.
شبکه عصبی پرسپترون چندلایه(MLP)
پرسپترون چندلایه همانطور که از اسمش بر میآید مجموعهای از نورونها است که در لایههای مختلفی پشت سر هم قرار گرفته اند. مقادیر ورودی پس از ضرب در وزنهای موجود در گذرگاههای بین لایهها به نورون بعدی رسیده و درآنجا با هم جمع شده و پس از عبور از تابع شبکه مربوطه خروجی نرون را تشکیل میدهند. در پایان خروجی بدست آمده با خروجی موردنظر مقایسه شده و خطای بدست آمده جهت اصلاح وزنهای شبکه به کار میرود، که این امر اصطلاحا آموزش شبکه عصبی نامیده میشود، که در ادامه میآید.
قاعده فراگیری پرسپترون چند لایه را «قاعده کلی دلتا[1] » یا «قاعده پس انتشار[2] » میگویند. این عناوین در سال 1986 توسط رومل هارت، مک کلند و ویلیامز پیشنهاد شد.
این افتخار به آنها تعلق میگیرد که اولین گروهی بودند که نه تنها قاعده فراگیری پرسپترون را به طور مستقل کشف کردند بلکه با ترکیب آنها پرسپترون چند لایهای را ایجاد کرده و مورد مطالعه قرار دادند. کتاب آنها به نام «پردازش توزیع شده موازی[3] » هنوز یکی از مهم ترین کتابهای این حوزهی علمی است.
نحوه عمل پرسپترون چند لایهای مشابه پرسپترون تک لایهای است. بدین صورت که الگویی به شبکه عرضه میشود و خروجی آن محاسبه میگردد، مقایسه خروجی واقعی و خروجی مطلوب باعث میگردد که ضرایب وزنی شبکه تغییر یابد به طوری که در دفعات بعد خروجی درستتری حاصل شود. قاعده فراگیری روش میزان کردن ضرایب وزنی شبکه را بیان میکند.
وقتی به شبکه آموزش ندیدهای الگویی را عرضه میکنیم، خروجیهای تصادفی تولید میکند. ابتدا باید تابع خطایی را تعریف کنیم که تفاوت خروجی واقعی و خروجی مطلوب را نشان دهد. چون خروجی مطلوب را میدانیم این نوع فراگیری را «فراگیری با سرپرست[4] » مینامیم. برای موفق شدن در آموزش شبکه باید خروجی آن را به تدریج به خروجی مطلوب نزدیک کنیم. به عبارت دیگر باید میزان تابع خطا را به طور دائم کاهش دهیم. برای این منظور ضرایب وزنی خطوط ارتباطی واحدها با استفاده از قاعده کلی دلتا میزان میشود. قاعده دلتا مقدار تابع خطا را محاسبه کرده و آن را به عقب از یک لایه به لایه پیشین انتشار میدهد. عبارت پس انتشار به این علت است. ضرایب وزنی هر واحد جداگانه میزان میشود و بدین صورت میزان خطا کاهش مییابد. این عمل در مورد واحدهای لایه خارجی ساده است زیرا خروجی واقعی و مطلوب آنها را میدانیم، ولی در مورد لایه میانی چندان روشن نیست. این گمان میرود که ضرایب وزنی واحدهای پنهان که به واحدهای خروجی با میزان خطایی بزرگ مرتبط هستند باید بیشتر از واحدهای پنهان که به واحدهای مرتبط آنها خروجی تقریباً صحیحی دارند تغییر یابد. در واقع ریاضیات نشان میدهد که ضرایب واحدها باید به تناسب میزان خطای واحدی که به آن متصل اند تغییر کند. بنابراین میتوان با انتشار خطا به عقب ضرایب وزنی خطوط ارتباطی تمام لایهها را به درستی میزان کرد. به این طریق تابع کاهش خطا ، شبکه آموزش مییابد.
[1] Delta rule
[2] Back propagation
[3] Parallel Distributed Processing
[4] Supervised Learning
[1] Soma
[2] dendrite
[3] fire
[4] fire
مطالب زیر را حتما مطالعه کنید

مدل هوش مصنوعی چیست؟
مدلهای خودهمبسته یا Autoregressive
خودرمزگذار متغیر یا VAE چیست و چگونه کار میکند؟

دیدگاهتان را بنویسید