مدل CLIP در یادگیری عمیق
پیشزمینه
مدل Contrasive زبان-تصویر (Contrasive Language-Image Pre-Training) یا CLIP یک مدل چند وجهی است که مطابقت بین زبان طبیعی و تصاویر را یاد میگیرد و بر روی 400 میلیون جفت متن-تصویر جمعآوریشده از اینترنت آموزش داده شده است. همانطور که بعداً در این مقاله خواهیم دید، CLIP عملکرد zero-shot یا یادگیری بدون نمونهی بسیار قوی دارد، به این معنی که بدون انجام هیچ گونه تنظیم دقیق، در تسکهای متفاوت از کارهایی که در آن آموزش دیده است، عملکرد قابل توجهی دارد.
CLIP ادعا میکند که:
- تکنیکهای پیشآموزش موفق در مقیاس بزرگ که در پردازش زبان طبیعی (مانند خانواده GPT، T5 و BERT) شناختهشده است را در بینایی ماشین بهکار میبرد.
- با استفاده از زبان طبیعی به جای برچسبهای ثابت، قابلیت zero-shot انعطافپذیری را فعال میکند.
ممکن است از خود بپرسید چرا این یک اتفاق بزرگ است؟ اول از همه، بسیاری از مدلهای بینایی ماشین بر روی مجموعه دادههای برچسبگذاریشده حجیم آموزش داده میشوند. این مجموعه دادهها اغلب شامل صدها هزار نمونه هستند؛ برخی استثناها دارای چند میلیون نمونه هستند. همانطور که میتوانید تصور کنید این یک فرآیند بسیار وقت گیر و پرهزینه است. از سوی دیگر، مجموعه دادههای مدلهای زبان طبیعی معمولاً چندین مرتبه بزرگتر هستند و از اینترنت جمعآوری میشوند. ثانیاً، اگر یک مدل تشخیص شی در کلاسهای خاصی آموزش داده شده است و میخواهید یک کلاس اضافی اضافه کنید، باید این کلاس جدید را در دادههای خود برچسب بزنید و مدل را دوباره آموزش دهید.
توانایی CLIP برای ترکیب زبان طبیعی و ویژگیهای تصویر در ترکیب با عملکرد zero-shot، منجر به استفادهی گسترده در بسیاری از مدلهای پایه محبوب دیگر مانند UnCLIP، EVA، SAM، Stable Diffusion، GLIDE یا VQGAN-CLIP شده است.
روش
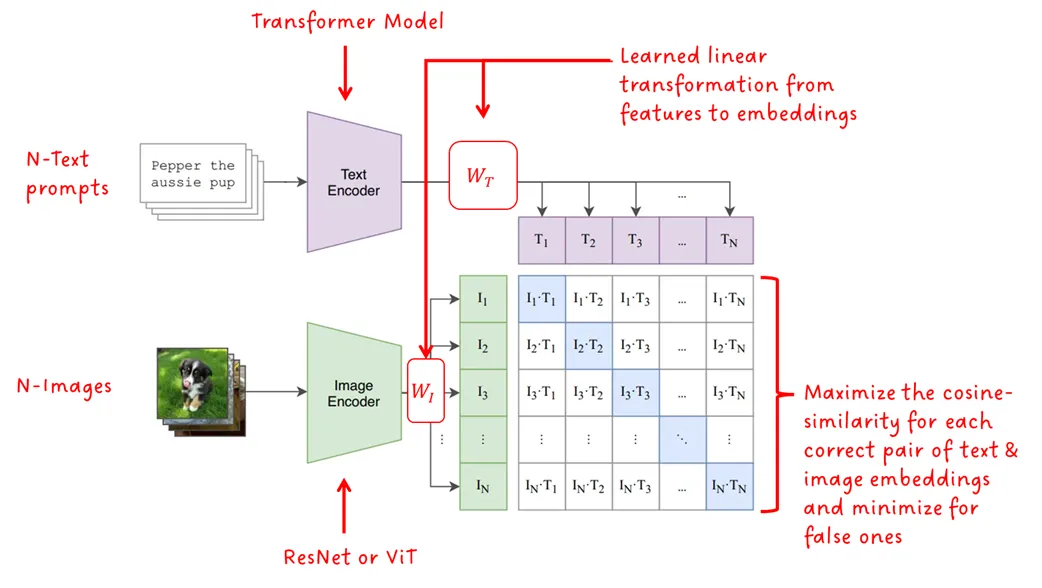
حالا بیایید به روش استفادهشده در CLIP بپردازیم. تصویری که در شکل زیر نشان داده شده است، معماری CLIP و روند نحوه آموزش آن را نشان میدهد.
معماری مدل از دو مدل رمزگذار تشکیل شده است، یکی برای متن و دیگری برای تصویر. برای رمزگذار متن از یک مدل مبدل (Transformer) استفاده شد در حالی که رمزگذار تصویر از نسخهای از ResNet یا ViT (همان Vision Transformer) استفاده میکند. یک تبدیل خطی آموختهشده، برای هر کدام از مدالیتیها، ویژگیها را در بردارهایی با اندازهی تعیین شده بازنمایی میکند. در نهایت، شباهت کسینوسی بین هر یک از بازنماییهای هر مدالیته محاسبه میشود و توسط یک ضریب temperature یاد گرفته شده تنظیم میشود. در طول آموزش، شباهت کسینوسی بین جفتهای منطبق به حداکثر میرسد در حالی که برای جفتهای نادرست کمینه میشود، از این رو اصطلاح «متضاد» یا Contrasive در نام این فریمورک به کار رفته است.
البته در کنار مجموعه داده بزرگ، نکات ظریف دیگری هم برای موفقیت بسیار مهم هستند. اول، رویکرد یادگیری Contrasive به شدت به اندازه دسته یا batch size بستگی دارد. هر چه نمونههای منفی بیشتری در امتداد نمونههای صحیح ارائه شوند، سیگنال یادگیری قویتر است. CLIP با batch sizeی برابر ۳۲۷۶۸ آموزش داده شد که بسیار بزرگ است. ثانیاً، CLIP یک تطابق با جملهبندی دقیق را نمیآموزد، بلکه از یک پراکسی سادهتر برای یادگیری متن به عنوان یک کل استفاده میکند که به آن کیسه کلمات یا Bag of Words (BoW) نیز میگویند.
حقیقت جالب: نسخه CLIP با استفاده از ResNet50x64 به عنوان رمزگذار تصویر به مدت ۱۸ روز در ۵۹۲ V100 GPUS و نسخه با مدل ViT به مدت ۱۲ روز روی ۲۵۶ V100 GPUS آموزش داده شد. به عبارت دیگر، به ترتیب بیش از ۲۹ سال و بیش از ۸ سال در یک GPU واحد (با نادیده گرفتن این واقعیت که batch size متفاوتی استفاده شده باشد).
هنگامی که مدل آموزش داده شد، میتوان از آن برای انجام طبقه ندی اشیاء بر روی تصاویر استفاده کرد. سوال این است که: چگونه میتوان با استفاده از مدلی که برای طبقهبندی تصاویر آموزش ندیده است، برچسبهای تصویر را در ورودی دریافت نکرده و تنها promptهای متنی را دیده است، طبقهبندی را انجام داد؟ شکل زیر نشان میدهد که چگونه:
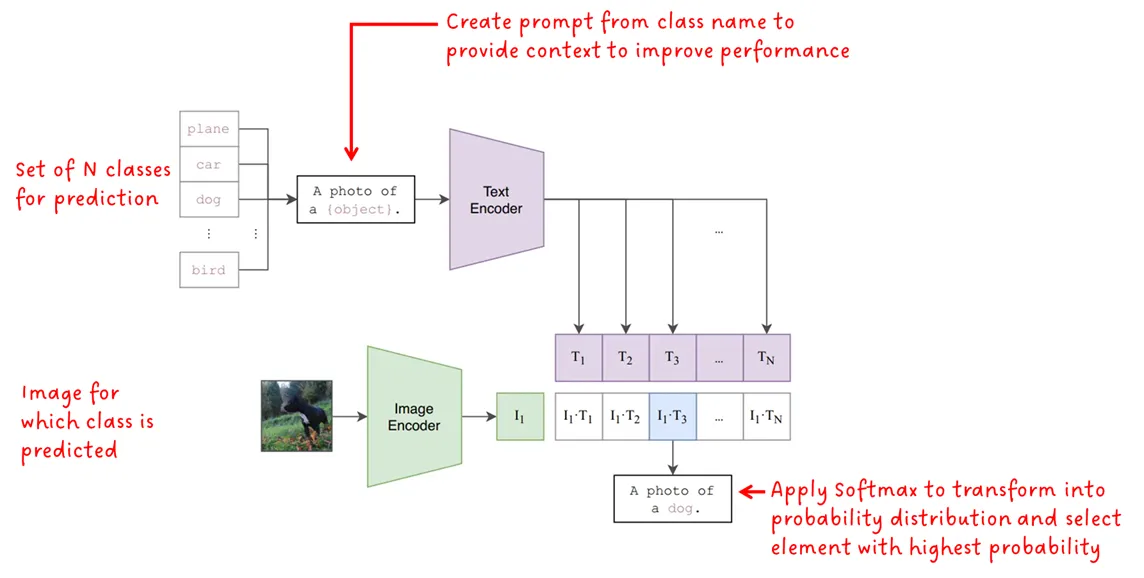
برچسب کلاس را میتوان به عنوان یک prompt متنی که توسط یک کلمه تشکیل شده است در نظر گرفت. برای اینکه به مدل بگوییم کدام کلاسها برای کار طبقهبندی در دسترس هستند، مجموعهای از N کلاس به عنوان ورودی به مدل داده میشود. این یک مزیت بزرگ در مقایسه با مدلهای طبقهبندی آموزشدیده بر روی مجموعه ثابتی از برچسبها است. اکنون می توانیم ۳ کلاس طبقهبندی یا ۱۰۰ کلاس را داشته باشیم و این انتخاب ماست. همانطور که بعدا خواهیم دید، برای بهبود عملکرد CLIP، برچسب کلاس به یک prompt تبدیل میشود تا زمینه بیشتری را برای مدل فراهم کند. سپس هر prompt به رمزگذار متن داده میشود و سپس به یک بردار جاسازی تبدیل میشود.
تصویر ورودی هم به رمزگذار تصویر داده میشود تا بردار تعبیه بدست آید.
سپس شباهت کسینوسی برای هر جفت جاسازی متن و تصویر محاسبه میشود. یک Softmax روی مقادیر تشابه بهدستآمده اعمال میشود تا توزیع احتمال را تشکیل دهد و در نهایت مقدار با بیشترین احتمال به عنوان پیشبینی نهایی انتخاب میشود.
آزمایشها
مقاله CLIP تعداد زیادی آزمایش را ارائه میدهد. در اینجا ما پنج مورد را پوشش خواهیم داد که به نظر ما برای درک موفقیت CLIP مهم است. ابتدا دستآوردها (همانطور که توسط نویسندگان CLIP بیان شده است) و سپس جزئیات را بررسی خواهیم کرد:
- کارایی آموزش: CLIP در انتقال zero-shot بسیار کارآمدتر از مدل پایهی شرح تصویر ما است.
- ساختار متن ورودی: مهندسی prompt و یکپارچهسازی، عملکرد zero-shot را بهبود میبخشد.
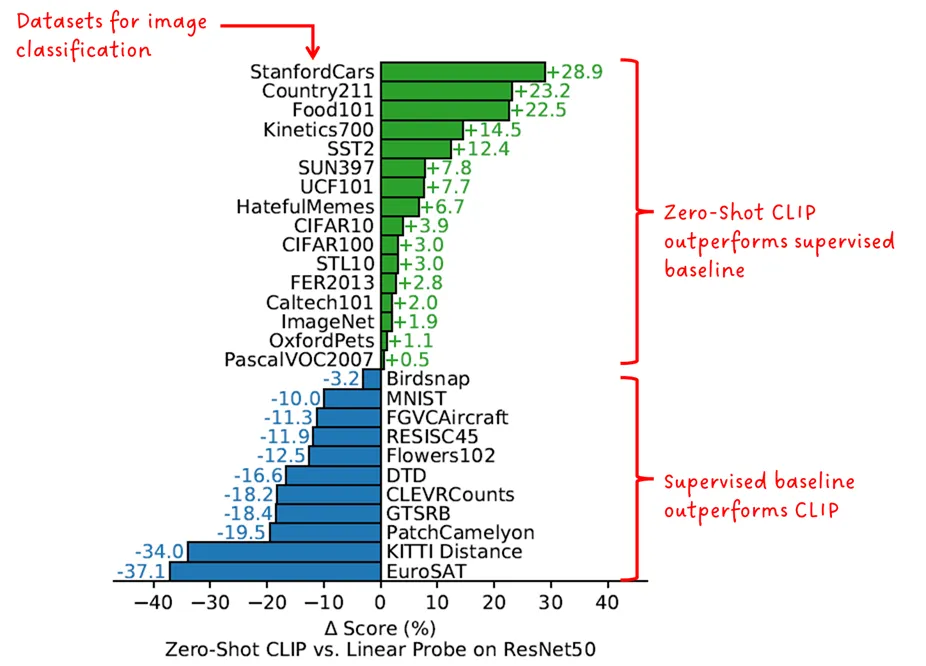
- عملکرد zero-shot یا یادگیری بدون نمونه: کارایی zero-shot در CLIP با مدلهای پایهی کاملاً نظارتشده رقابت میکند.
- عملکرد few-shot یا با نمونهی کم: CLIP صفر شات بهتر از پروب های خطی چند شات است
- تغییر توزیع: عملکرد zero-shot در CLIP بسیار مقاومتر مدلهای ImageNet استاندارد در مواجهه با تغییر توزیع ظاهر میشود.
کارایی آموزش
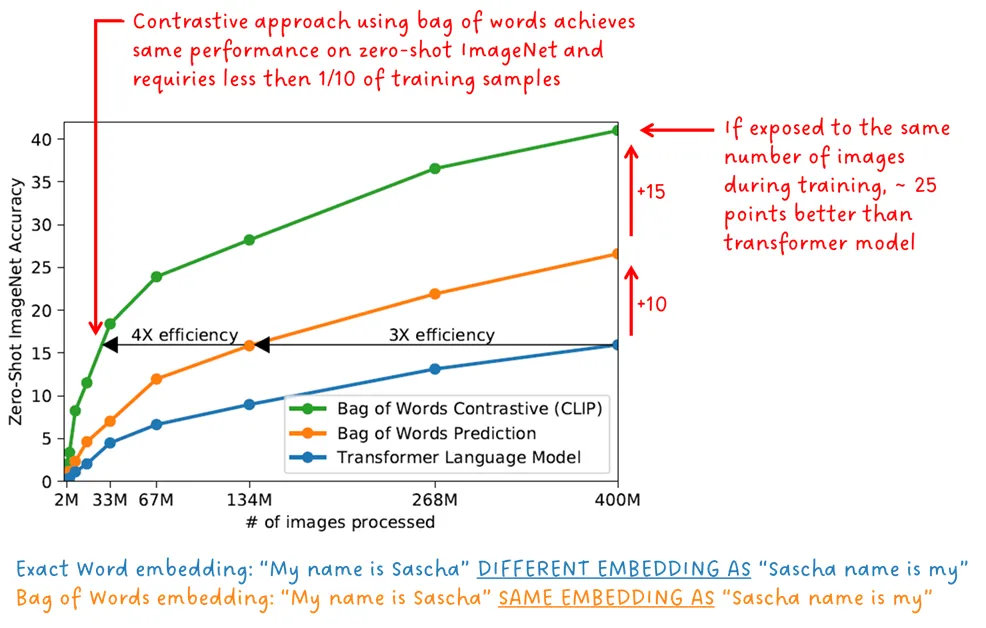
در طول آموزش، رمزگذار تصویر و رمزگذار متن به طور مشترک آموزش داده میشوند، به این معنی که با یک تابع هدف آموزشی و همزمان آموزش میبینند. CLIP نه تنها یک طرح یادگیری متضاد یا Contrasive را انجام میدهد، بلکه prompt های متنی به صورت کلی با یک تصویر مقایسه میشوند، بنابراین ترتیب کلمات مهم نیست. این روش در واقع یک “کیف کلمات” است. عبارت “نام من ساشا است” به همان شکلی پردازش میشود که “نام ساشا من است”.
پیشبینی مجموعهای از کلمات به جای جای صحیح کلمات و موقعیت آن در یک عبارت، پروکسی هدف بسیار آسانتری است. شکل زیر دقت zero-shot را در ImageNet بر اساس تعداد نمونههای آموزشی مدل مبدل اولیهی آموزشدیده برای پیشبینی دقیق کلمات، مدل مبدل اولیهی آموزشدیده برای پیشبینی مجموعهای از کلمات و مدل CLIP که یادگیری متضاد را با استفاده از مجموعهی کلمات انجام میدهد نشان میدهد.
CLIP در انتقال zero-shot بسیار کارآمدتر از مدلهای پایهی شرح تصویر ما عمل میکند – نویسندگان CLIP.
ساختار متن ورودی
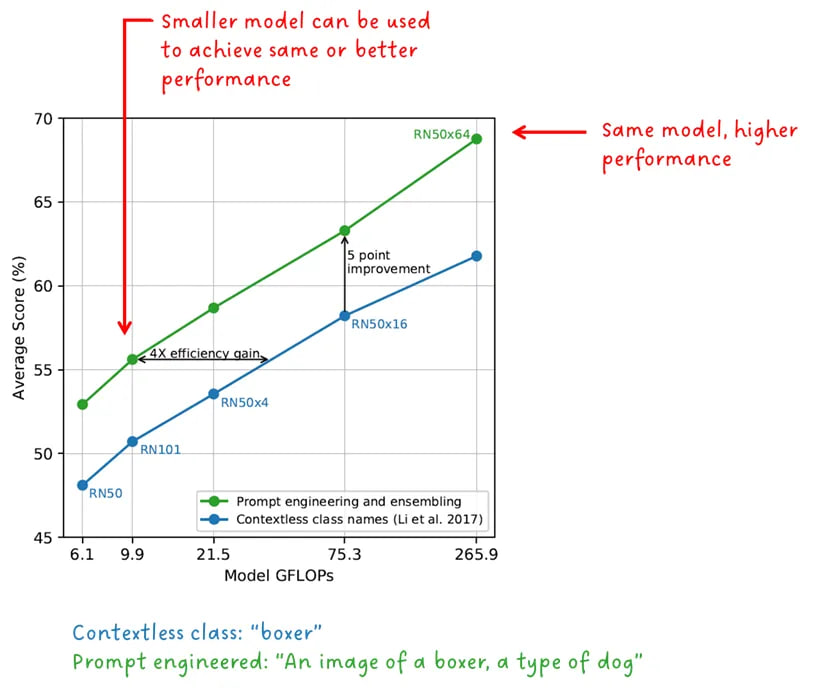
همانطور که در شکل 2 دیدیم، برای انجام طبقه بندی اشیا، برچسب کلاس به یک اعلان متنی تبدیل شده است. البته این اتفاقی نبود، زیرا CLIP با یک کلمه کاملاً خوب می شود. این کار به منظور استفاده از توصیفی بودن زبان و ارائه زمینه ای برای رفع ابهامات احتمالی انجام شد. بیایید به عنوان مثال کلمه “بوکسور” را در نظر بگیریم. این می تواند یک نوع سگ یا یک نوع ورزشکار باشد. نویسندگان CLIP نشان دادهاند که فرمت اعلان متن اهمیت زیادی دارد و میتواند عملکرد را افزایش داده و کارایی را نیز افزایش دهد.
“مهندسی و ترکیب بندی سریع عملکرد صفر شات را بهبود می بخشد” – نویسندگان CLIP
عملکرد zero-shot یا یادگیری بدون نمونه
در آزمایشی دیگر، نویسندگان عملکرد طبقهبندی تصویر در حالت zero-shot با CLIP را با مدلی که به طور خاص بر روی مجموعهدادهی تحت مقایسه آموزش داده شده بود، مقایسه کردند.
«عملکرد CLIP در حالت zero-shot با مدلهای پایهی تحت آموزش نظارتشده، قابل رقابت است» — نویسندگان CLIP
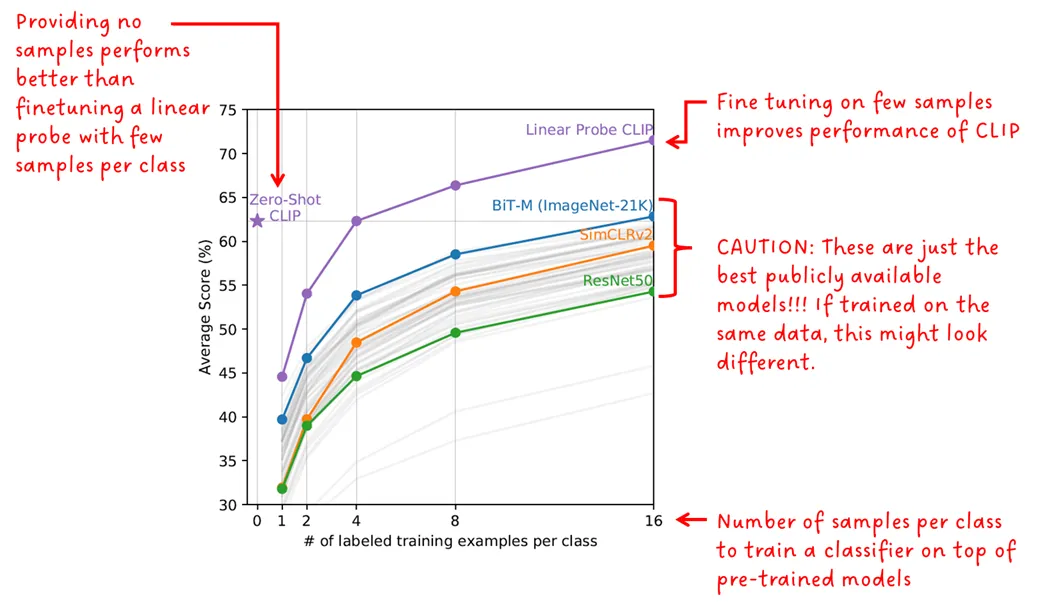
عملکرد few-shot یا یادگیری با نمونهی کم
در حالی که پیشبینیکنندههای zero-shot برای تسکهای هدف تنظیم نشدهاند، پیشبینیکنندههای few-shot باز-تنظیم شدهاند. نویسندگان چندین مدل ازپیش آموزشدیدهی در دسترس عموم را آزمایش کردند و عملکرد few-shot آنها را روی ۲۰ مجموعهدادهی مختلف در مقابل CLIP در حالت zero-shot و few-shot مقایسه کردند. مدلهای few-shot بر روی ۱، ۲، ۴، ۸ و ۱۶ نمونه از هر کلاس، تنظیم شدهاند.
جالب اینجاست که CLIP در حالت zero-shot تقریباً به خوبی CLIP با ۴ شات عمل میکند.
اگر CLIP را با مدلهای دیگر مقایسه کنید، باید در نظر داشت که مدلهای در دسترس عمومی تحت مقایسه (یعنی BiT، SimCLR و ResNet) روی مجموعههای داده متفاوت و کوچکتری نسبت به مدل CLIP آموزش داده شدهاند.
“CLIP در حالت zero-shot بهتر از پروبهای خطی در حالت few-shot عمل میکند” – نویسندگان CLIP
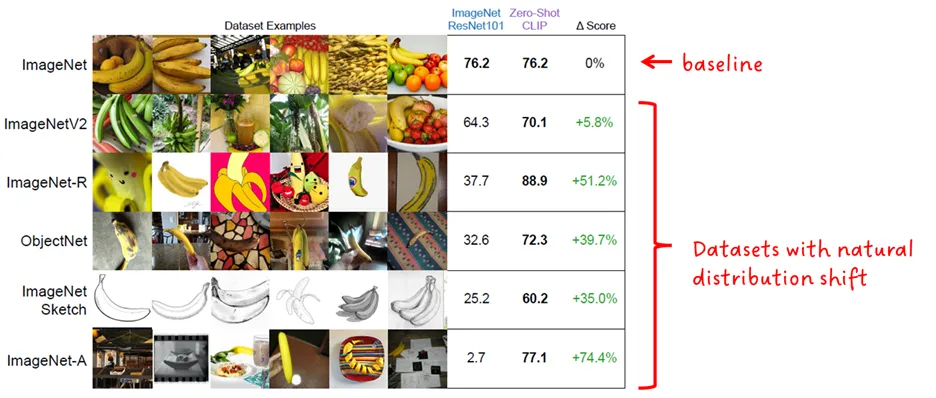
تغییر توزیع
به طور کلی، استحکام یک مدل نسبت به تغییرات توزیع به توانایی آن در داشتن عملکرد به همان اندازه خوب بر روی دادههایی با توزیعهای مختلف، نسبت به دادههایی که روی آن آموزش داده شده است، اشاره دارد. در حالت ایده آل، به همان اندازه عملکرد خوبی خواهد داشت؛ اما در واقع، عملکرد آن کاهش مییابد.
استحکام CLIP در حالت zero-shot با مدل ResNet101 ImageNet مقایسه شده است. هر دو مدل بر اساس تغییرات توزیع طبیعی ImageNet، همانطور که در شکل زیر نشان داده شده است، ارزیابی میشوند.
“CLIP در حالت zero-shot در مقایسه با مدلهای استاندارد ImageNet استحکام بیشتری نسبت به تغییر توزیع دارد” – نویسندگان CLIP
منبع:
https://towardsdatascience.com/the-clip-foundation-model-7770858
b487d
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 1

راهنمای قدم به قدم کرایه کارت گرافیک (GPU) با Vast.ai برای پروژههای هوش مصنوعی

دیدگاهتان را بنویسید