۱۹ نکته ضروری برای آموزش شبکههای عصبی عمیق

این پست، نکات ضروری برای آموزش شبکههای عصبی عمیق را به تفصیل شرح میدهد و به شما کمک میکند تا مدلهای قدرتمند و کارآمدی بسازید.
- دادههای خود را مانند جعبه سیاه در نظر نگیرید
- با یک Pipeline ساده ولی End-to-End شروع کنید
- روی یک Batch کوچک Overfit کنید
- یک Baseline منطقی ایجاد کنید
- پیچیدگی مدل را به تدریج افزایش دهید
- ابتدا Overfit کنید و سپس Regularize کنید
- از انتقال یادگیری بهره ببرید
- مدیریت نرخ یادگیری
- Early Stopping را به کار ببرید
- انتخاب مناسب توابع فعالسازی و مقداردهی اولیه
- استفاده از بهینهسازهای مناسب
- اندازه Mini-batch را به درستی تنظیم کنید
- پایش دقیق و Log کردن عملکرد
- استفاده از تکنیکهای Data Augmentation
- تنظیم مناسب Hyperparameterها
- بهبود عملکرد با Regularizationهای پیشرفته
- مدیریت منابع محاسباتی و زمان آموزش
- آزمایش و ارزیابی مدل با دادههای واقعی
- بهروز بودن با تحقیقات جدید
- دادههای خود را مانند جعبه سیاه در نظر نگیرید:قبل از شروع آموزش، بسیار مهم است که دادههای خود را به خوبی بشناسید. این شامل بررسی دقیق دادههای خام، برچسبها، توزیع دادهها (مثلاً نرمال، یکنواخت، یا چوله)، شناسایی الگوها، مقادیر پرت (Outliers)، و دادههای از دست رفته (Missing Values) میشود. ابزارهای مصورسازی مانند هیستوگرام، نمودار پراکندگی، و جعبهای میتوانند در این مرحله بسیار مفید باشند. این تحلیل اولیه به شما کمک میکند تا پیشپردازش مناسب را انتخاب کنید و از مشکلات بعدی جلوگیری کنید.
- با یک Pipeline ساده ولی End-to-End شروع کنید:یک Pipeline کامل از خواندن دادههای خام تا تولید خروجی نهایی ایجاد کنید، حتی اگر در ابتدا ساده باشد. این Pipeline باید شامل مراحل پیشپردازش دادهها، آموزش مدل، اعتبارسنجی، و ارزیابی باشد. از اضافه کردن پیچیدگیهای غیرضروری در مراحل اولیه خودداری کنید. این رویکرد به شما کمک میکند تا فرآیند کلی را درک کنید و به تدریج بخشهای مختلف آن را بهبود دهید.
مثلا pipeline زیر در tensorflow بدون پیچیدگی خاصی 99 درصد دقت میدهد:
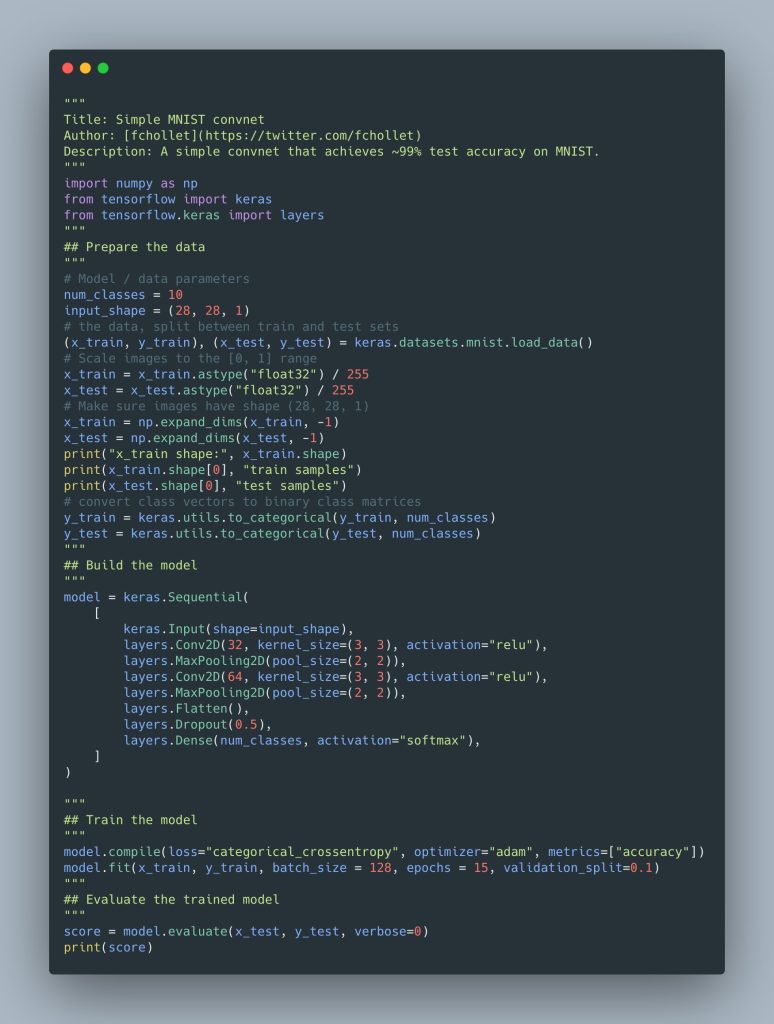
- روی یک Batch کوچک Overfit کنید:قبل از آموزش کامل مدل، آن را روی یک Batch بسیار کوچک (مثلاً فقط چند نمونه) آموزش دهید. هدف این است که مطمئن شوید مدل میتواند به سرعت روی این دادههای محدود Overfit شود. این نشان میدهد که معماری مدل و تنظیمات اولیه آن (مانند نرخ یادگیری) درست کار میکنند و مدل پتانسیل یادگیری را دارد. اگر مدل روی این Batch کوچک Overfit نشود، ممکن است مشکلی در کد، معماری مدل، یا تنظیمات Hyperparameter وجود داشته باشد.
- یک Baseline منطقی ایجاد کنید:یک مدل ساده (مانند رگرسیون خطی یا یک شبکه عصبی کوچک) را به عنوان Baseline آموزش دهید. عملکرد این مدل ساده به عنوان معیاری برای سنجش عملکرد مدلهای پیچیدهتر شما عمل میکند. این به شما کمک میکند تا بفهمید آیا تلاشهای شما برای بهبود مدل مؤثر بودهاند یا خیر. فرض کنید میخواهید دمای بیرون را برای ۲۴ ساعت آینده با استفاده از دادههای تاریخی دما پیشبینی کنید. یک baseline ساده میتواند دمای فعلی را به عنوان دمای ۲۴ ساعت بعد پیشبینی کند. مدل شما از این baseline ساده باید بهتر عمل کند.
- پیچیدگی مدل را به تدریج افزایش دهید:بعد از ایجاد Baseline، به تدریج پیچیدگی مدل را افزایش دهید. به عنوان مثال، لایههای بیشتری به شبکه عصبی اضافه کنید، تکنیکهای Data Augmentation را به کار ببرید، یا Optimizerهای پیشرفتهتری را امتحان کنید. این رویکرد تدریجی به شما کمک میکند تا تأثیر هر تغییر را ارزیابی کنید و از پیچیدگی بیش از حد مدل جلوگیری کنید.
- ابتدا Overfit کنید و سپس Regularize کنید:ابتدا مطمئن شوید که مدل شما میتواند روی یک مجموعه داده کوچک Overfit شود. این نشان میدهد که مدل ظرفیت یادگیری کافی دارد. سپس، با استفاده از تکنیکهای Regularization مانند Dropout، L1/L2 Regularization، Data Augmentation، و Early Stopping از Overfitting روی کل مجموعه داده جلوگیری کنید. همچنین، افزایش دادههای آموزشی میتواند به بهبود عملکرد مدل کمک کند.
- از انتقال یادگیری بهره ببرید:به جای آموزش مدل از صفر، از مدلهای Pre-trained مانند ResNet, VGG, Inception, یا EfficientNet استفاده کنید. این مدلها قبلاً روی مجموعه دادههای بزرگ آموزش دیدهاند و میتوانند ویژگیهای مفیدی را استخراج کنند. شما میتوانید این مدلها را برای وظیفه خاص خود Fine-tune کنید. انتقال یادگیری میتواند به طور قابل توجهی سرعت آموزش را افزایش دهد و عملکرد مدل را بهبود بخشد، به خصوص وقتی که دادههای آموزشی محدودی دارید.
- مدیریت نرخ یادگیری:نرخ یادگیری یکی از مهمترین Hyperparameterها در آموزش شبکههای عصبی است. از تکنیکهایی مانند Learning Rate Schedules (مانند Cyclical Learning Rates, Cosine Annealing, و Step Decay) و Learning Rate Finder (برای پیدا کردن نرخ یادگیری اولیه مناسب) استفاده کنید. این تکنیکها به شما کمک میکنند تا نرخ یادگیری بهینه را در طول فرآیند آموزش تنظیم کنید.
- Early Stopping را به کار ببرید:برای جلوگیری از Overfitting، از Early Stopping استفاده کنید. مدل را روی دادههای آموزشی آموزش دهید و عملکرد آن را روی دادههای اعتبارسنجی (Validation Set) پایش کنید. اگر عملکرد مدل روی دادههای اعتبارسنجی برای چند دوره متوالی بهبود نیافت، آموزش را متوقف کنید.
- انتخاب مناسب توابع فعالسازی و مقداردهی اولیه:از توابع فعالسازی مناسب مانند ReLU، Leaky ReLU، یا Swish استفاده کنید. از مقداردهی اولیه مناسب وزنها (مانند He یا Glorot) بهره ببرید تا از مشکلات Vanishing/Exploding Gradients جلوگیری شود. انتخاب تابع فعالسازی و مقداردهی اولیه مناسب به معماری شبکه و نوع دادهها بستگی دارد.
- استفاده از بهینهسازهای مناسب:از بهینهسازهای پیشرفته مانند Adam، RMSprop، یا SGD with Momentum استفاده کنید. این بهینهسازها به طور کلی عملکرد بهتری نسبت به SGD ساده دارند. همچنین، بهروز بودن با الگوریتمهای بهینهسازی جدید میتواند مفید باشد.
برای شروع آموزش شبکههای عصبی، Adam یک گزینه کارآمد، پایدار و آسان برای پیادهسازی است.
- اندازه Mini-batch را به درستی تنظیم کنید:اندازه Mini-batch تأثیر زیادی بر سرعت و پایداری آموزش دارد. اندازههای کوچکتر معمولاً برای GPUهای با حافظه کمتر مناسب هستند و میتوانند به Regularization کمک کنند، در حالی که اندازههای بزرگتر میتوانند آموزش را سریعتر کنند اما به حافظه بیشتری نیاز دارند.
طبق توصیهی معروف یان لکان که میگوید “Friends don’t let friends use mini-batches larger than 32.”، استفاده از مینیبچهای بزرگتر از ۳۲ میتواند باعث کاهش نویز در بهروزرسانیهای گرادیان و در نتیجه افزایش خطر اورفیت شود. اگرچه مینیبچهای کوچکتر ممکن است سرعت همگرایی را کاهش دهند، اما با ایجاد تغییرات تصادفی و نویز مفید، به عنوان یک Regularizer طبیعی عمل میکنند و به بهبود تعمیمپذیری مدل کمک میکنند. بنابراین، به طور کلی توصیه میشود توجه کنید که مینی بچ بزرگ سرعت همگرایی را بالا میبرد اما خطر اورفیت دارد.باید در انتخاب سایز batch تعادل مناسبی بین سرعت همگرایی و جلوگیری از اورفیت برقرار شود.
- پایش دقیق و Log کردن عملکرد:از ابزارهایی مانند TensorBoard یا Weights & Biases برای Log کردن معیارهای مختلف (مانند Loss, Accuracy, و Learning Rate) و مصور سازی آنها استفاده کنید. این به شما کمک میکند تا روند آموزش را به دقت پایش کنید، مشکلات را شناسایی کنید، و تصمیمات آگاهانهای در مورد تنظیم Hyperparameterها بگیرید.
- استفاده از تکنیکهای Data Augmentation:Data Augmentation با ایجاد تغییرات تصادفی در دادههای آموزشی (مانند چرخش، تغییر اندازه، برش، و تغییر رنگ) میتواند به طور قابل توجهی عملکرد مدل را بهبود بخشد و از Overfitting جلوگیری کند. انتخاب تکنیکهای مناسب Data Augmentation به نوع داده و وظیفه مورد نظر بستگی دارد.

- تنظیم مناسب Hyperparameterها:Hyperparameterها پارامترهایی هستند که قبل از شروع آموزش تنظیم میشوند و بر روند آموزش تأثیر میگذارند. به جای استفاده صرف از Grid Search، از روشهای کارآمدتری مانند Random Search یا Bayesian Optimization استفاده کنید تا Hyperparameterهای بهینه را پیدا کنید.
- بهبود عملکرد با Regularizationهای پیشرفته:علاوه بر Dropout، از تکنیکهای Regularization دیگری مانند Batch Normalization، Layer Normalization، Instance Normalization، و L1/L2 Regularization استفاده کنید تا عملکرد مدل را بهبود بخشید و از Overfitting جلوگیری کنید.
- مدیریت منابع محاسباتی و زمان آموزش:برای مدلهای بزرگ و مجموعه دادههای حجیم، از تکنیکهایی مانند Distributed Training (آموزش موازی روی چندین GPU) و Mixed Precision Training (استفاده از نوع داده FP16 برای کاهش زمان آموزش و مصرف حافظه) استفاده کنید.
- آزمایش و ارزیابی مدل با دادههای واقعی:عملکرد مدل را نه تنها روی دادههای آموزشی و اعتبارسنجی، بلکه روی دادههای آزمایش (Test Set) که مدل قبلاً آنها را ندیده است، ارزیابی کنید. این ارزیابی به شما تصویر واقعبینانهتری از عملکرد مدل در دنیای واقعی میدهد.
- بهروز بودن با تحقیقات جدید:حوزه یادگیری عمیق به سرعت در حال تکامل است. برای دسترسی به آخرین تکنیکها، روشها، و مدلها، مقالات جدید، کتابهای بهروز، و دورههای آموزشی را دنبال کنید و در کنفرانسها و کارگاههای آموزشی شرکت کنید. همچنین، پیوستن به انجمنهای آنلاین و گروههای بحث و گفتگو میتواند به شما در یادگیری و بهاشتراکگذاری دانش کمک کند.
آیا آمادهاید تا به دنیای هوش مصنوعی و یادگیری عمیق وارد شوید؟ با شرکت در دوره جامع یادگیری عمیق: تسلط بر هوش مصنوعی با ۴۰ ساعت آموزش (TensorFlow/Keras)، میتوانید مهارتهای لازم برای پیشرفت در این حوزه را کسب کنید.
ویژگیهای برجسته این دوره:
-
آموزش جامع از مقدماتی تا پیشرفته: این دوره ۴۰ ساعته شما را با مفاهیم پایهای تا پیشرفته یادگیری عمیق آشنا میکند.
-
پروژههای عملی: با انجام پروژههای واقعی، مهارتهای خود را تقویت کرده و تجربه عملی کسب خواهید کرد.
-
مدرس مجرب: با بهرهگیری از تخصص اساتید با تجربه، مفاهیم پیچیده را به سادگی فرا خواهید گرفت.
-
دسترسی به منابع تکمیلی: تمامی کدها و منابع مورد نیاز در گیتهاب دوره در دسترس شما قرار دارد.
با ثبتنام در این دوره، گامی مؤثر در مسیر حرفهای خود بردارید و به جمع دانشجویان موفق ما بپیوندید.
دوره جامع یادگیری عمیق: تسلط بر هوش مصنوعی با 40 ساعت آموزش (Tensorflow/keras)
همین حالا ثبتنام کنید و آینده شغلی خود را متحول سازید!
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

دیدگاهتان را بنویسید