الگوریتمهای بهینه سازی شبکه عصبی
مطالب زیر را حتما مطالعه کنید

کاهش مصرف حافظه در LLM با bitsandbytes: آموزش و استنتاج سریع با کوانتیزاسیون 4 و 8 بیتی
کتابخانه bitsandbytes امکان استفاده از مدلهای زبانی بزرگ (Large Language...
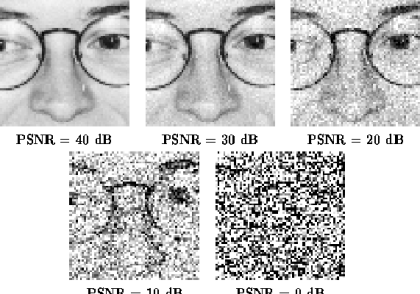
PSNR چیست؟
اصطلاح نسبت اوج سیگنال به نویز (Peak Signal-to-Noise Ratio یا...

آشنایی با شرکت OpenAI
آشنایی با شرکت OpenAI: پیشرو در هوش مصنوعی در دنیای...
دیدگاهتان را بنویسید