آموزش Agent-بخش 2:LLM چیست؟

در بخش قبلی آموختیم که هر Agent نیاز به یک مدل هوش مصنوعی در هسته خود دارد، و LLM ها رایجترین نوع مدلهای هوش مصنوعی برای این منظور هستند.
اکنون خواهیم آموخت که LLM ها چیستند و چگونه به Agent ها قدرت میبخشند.
این بخش توضیحی فنی و مختصر درباره استفاده از LLM ها ارائه میدهد. اگر میخواهید عمیقتر به این موضوع بپردازید، میتوانید دوره LLM کلاس ویژن را بررسی کنید.
مدل زبانی بزرگ (Large Language Model) چیست؟
LLM نوعی از مدل هوش مصنوعی است که در درک و تولید زبان انسانی برتری دارد. این مدلها روی حجم عظیمی از دادههای متنی آموزش میبینند که به آنها امکان میدهد الگوها، ساختار و حتی ظرافتهای زبان را یاد بگیرند. این مدلها معمولاً از میلیونها پارامتر تشکیل شدهاند.
اکثر LLM ها در حال حاضر بر پایه معماری Transformer ساخته شدهاند—یک معماری یادگیری عمیق مبتنی بر الگوریتم “Attention”، که از زمان انتشار BERT توسط Google در سال ۲۰۱۸ مورد توجه قابل توجهی قرار گرفته است.
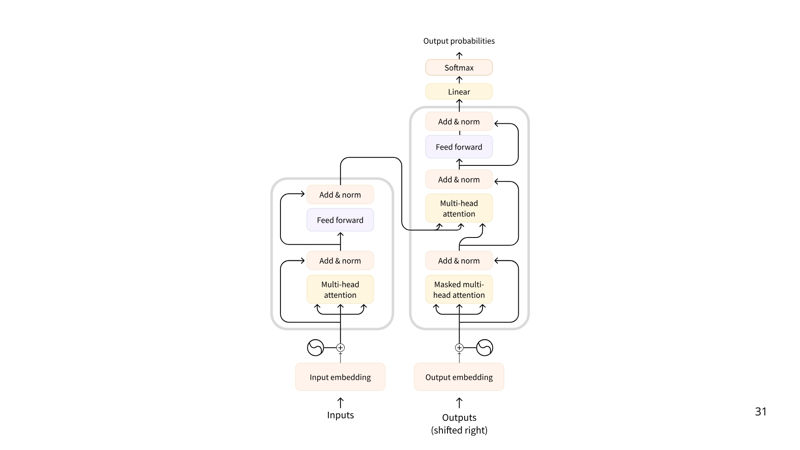
سه نوع ترنسفورمر وجود دارد:
- Encoders
یک ترنسفورمر مبتنی بر encoder، متن (یا سایر دادهها) را به عنوان ورودی میگیرد و یک نمایش متراکم (یا embedding) از آن متن را خروجی میدهد.
مثال: BERT از Google
موارد استفاده: طبقهبندی متن، جستجوی معنایی، تشخیص موجودیتهای نامدار (Named Entity Recognition)
اندازه معمول: میلیونها پارامتر - Decoders
یک ترنسفورمر مبتنی بر decoder بر تولید توکنهای جدید برای تکمیل یک توالی، یک توکن در هر زمان، تمرکز دارد.
مثال: Llama از Meta
موارد استفاده: تولید متن، چتباتها، تولید کد
اندازه معمول: میلیاردها (به معنای آمریکایی، یعنی ۱۰ به توان 10) پارامتر - Seq2Seq (Encoder–Decoder)
یک ترنسفورمر توالی-به-توالی، یک encoder و یک decoder را ترکیب میکند. ابتدا encoder توالی ورودی را به یک نمایش زمینهای پردازش میکند، سپس decoder یک توالی خروجی تولید میکند.
مثال: T5, BART
موارد استفاده: ترجمه، خلاصهسازی، بازنویسی
اندازه معمول: میلیونها پارامتر
اگرچه مدلهای زبانی بزرگ در اشکال مختلفی وجود دارند، LLM ها معمولاً مدلهای مبتنی بر decoder با میلیاردها پارامتر هستند. در اینجا برخی از شناختهشدهترین LLM ها آمده است:
| مدل | ارائهدهنده |
|---|---|
| Deepseek-R1 | DeepSeek |
| GPT4 | OpenAI |
| Llama 3 | Meta (Facebook AI Research) |
| SmolLM2 | Hugging Face |
| Gemma | |
| Mistral | Mistral |
اصل اساسی یک LLM ساده اما بسیار مؤثر است: هدف آن پیشبینی توکن بعدی، با توجه به توالی توکنهای قبلی است. یک “توکن” واحد اطلاعاتی است که LLM با آن کار میکند. میتوانید “توکن” را مانند یک “کلمه” تصور کنید، اما به دلایل کارایی، LLM ها از کلمات کامل استفاده نمیکنند.
برای مثال، در حالی که زبان انگلیسی حدود ۶۰۰,۰۰۰ کلمه دارد، یک LLM ممکن است واژگانی حدود ۳۲,۰۰۰ توکن داشته باشد (مانند Llama 2). توکنایزیشن (Tokenization) اغلب روی واحدهای زیرکلمهای کار میکند که میتوانند ترکیب شوند.
برای مثال، در نظر بگیرید که چگونه توکنهای “interest” و “ing” میتوانند برای تشکیل “interesting” ترکیب شوند، یا “ed” میتواند برای تشکیل “interested” اضافه شود.
میتوانید با توکنایزرهای مختلف در زمین بازی تعاملی زیر آزمایش کنید:
هر LLM دارای برخی توکنهای خاص مخصوص به آن مدل است. LLM از این توکنها برای باز کردن و بستن اجزای ساختاری تولید خود استفاده میکند. به عنوان مثال، برای نشان دادن شروع یا پایان یک توالی، پیام یا پاسخ. علاوه بر این، پرامپتهای ورودی که ما به مدل میدهیم نیز با توکنهای خاص ساختاربندی شدهاند. مهمترین آنها توکن پایان توالی EOS که مخفف End of sequence token میباشد، است.
اشکال توکنهای خاص در میان ارائهدهندگان مدل بسیار متنوع هستند.
جدول زیر تنوع توکنهای خاص را نشان میدهد.
| مدل | ارائهدهنده | توکن EOS | عملکرد |
|---|---|---|---|
| GPT4 | OpenAI | <|endoftext|> | پایان متن پیام |
| Llama 3 | Meta (Facebook AI Research) | <|eot_id|> | پایان توالی |
| Deepseek-R1 | DeepSeek | <|end_of_sentence|> | پایان متن پیام |
| SmolLM2 | Hugging Face | <|im_end|> | پایان دستورالعمل یا پیام |
| Gemma | <end_of_turn> | پایان نوبت مکالمه |
ما انتظار نداریم که شما این توکنهای خاص را به خاطر بسپارید، اما درک تنوع آنها و نقشی که در تولید متن LLM ها ایفا میکنند، مهم است. اگر میخواهید اطلاعات بیشتری در مورد توکنهای خاص کسب کنید، میتوانید پیکربندی مدل را در مخزن Hub آن بررسی کنید. به عنوان مثال، میتوانید توکنهای خاص مدل SmolLM2 را در فایل tokenizer_config.json آن پیدا کنید.
درک پیشبینی توکن بعدی
LLM ها به عنوان خودهمبسته (autoregressive) شناخته میشوند، به این معنی که خروجی از یک گذر، ورودی برای گذر بعدی میشود. این چرخه ادامه مییابد تا زمانی که مدل پیشبینی کند توکن بعدی همان توکن EOS است، که در این نقطه مدل میتواند متوقف شود.

به عبارت دیگر، یک LLM متن را رمزگشایی میکند تا زمانی که به EOS برسد. اما در طول یک چرخه رمزگشایی واحد چه اتفاقی میافتد؟
در حالی که فرآیند کامل میتواند برای هدف یادگیری عاملها (learning agents) بسیار فنی باشد، در اینجا یک مرور مختصر ارائه میشود:
- پس از توکنسازی متن ورودی، مدل بازنمایی ای از توالی را محاسبه میکند که اطلاعاتی درباره معنا و موقعیت هر توکن در توالی ورودی را ثبت میکند.
- این بازنمایی وارد مدل میشود، که امتیازاتی را خروجی میدهد که احتمال هر توکن در واژگان آن را به عنوان توکن بعدی در توالی رتبهبندی میکند.

بر اساس این امتیازات، ما استراتژیهای متعددی برای انتخاب توکنها جهت تکمیل جمله داریم.
- سادهترین استراتژی رمزگشایی این است که همیشه توکن با بالاترین امتیاز را انتخاب کنیم.
شما میتوانید خودتان با فرآیند رمزگشایی SmolLM2 در این فضا تعامل داشته باشید (به یاد داشته باشید، رمزگشایی تا رسیدن به یک توکن EOS که برای این مدل <|im_end|> است، ادامه مییابد):
اما استراتژیهای رمزگشایی پیشرفتهتری نیز وجود دارد. به عنوان مثال، جستجوی پرتویی (beam search) چندین توالی کاندیدا را بررسی میکند تا توالی با بالاترین امتیاز کل را پیدا کند – حتی اگر برخی از توکنهای منفرد امتیاز پایینتری داشته باشند.
توجه تمام چیزی است که نیاز دارید (Attention is all you need)
یک جنبه کلیدی معماری Transformer، مکانیزم توجه (Attention) است. هنگام پیشبینی کلمه بعدی، همه کلمات در یک جمله به یک اندازه مهم نیستند؛ کلماتی مانند “فرانسه” و “پایتخت” در جمله “پایتخت فرانسه … است” حاوی بیشترین معنا هستند.

این فرآیند شناسایی مرتبطترین کلمات برای پیشبینی توکن بعدی، بسیار موثر است.
اگرچه اصل اساسی LLMها که پیشبینی توکن بعدی است از زمان GPT-2 ثابت مانده، پیشرفتهای قابل توجهی در مقیاسپذیری شبکههای عصبی و بهبود مکانیزم توجه برای توالیهای طولانیتر و طولانیتر صورت گرفته است.
اگر با LLMها تعامل داشتهاید، احتمالاً با اصطلاح طول زمینه (context length) آشنا هستید، که به حداکثر تعداد توکنهایی که LLM میتواند پردازش کند و حداکثر دامنه توجه آن اشاره دارد.
پرامپت نویسی LLM ها مهم است
با توجه به اینکه تنها وظیفه یک LLM پیشبینی توکن بعدی با نگاه کردن به هر توکن ورودی و انتخاب توکنهای “مهم” است، نحوه نگارش توالی ورودی شما بسیار مهم است.
توالی ورودی که به یک LLM ارائه میدهید، پرامپت (prompt) نامیده میشود. طراحی دقیق پرامپت، هدایت تولید LLM به سمت خروجی مطلوب را آسانتر میکند.
چگونه LLMها آموزش داده میشوند؟
LLMها روی مجموعه دادههای بزرگ متنی (corpus) آموزش داده میشوند، جایی که آنها یاد میگیرند کلمه بعدی در یک توالی را از طریق یک هدف یادگیری خودنظارتی یا مدلسازی زبان ماسک شده پیشبینی کنند.
از این یادگیری بدون نظارت، مدل ساختار زبان و الگوهای زیربنایی در متن را میآموزد، که به مدل اجازه میدهد تا به دادههای دیده نشده تعمیم دهد.
پس از این پیشآموزش اولیه، LLMها میتوانند روی یک هدف یادگیری نظارتشده برای انجام وظایف خاص فاینتیون (fine-tune) شوند. به عنوان مثال، برخی مدلها برای ساختارهای مکالمهای یا استفاده از ابزار آموزش داده میشوند، در حالی که دیگران بر طبقهبندی یا تولید کد تمرکز دارند.
چگونه میتوانیم از LLMها استفاده کنیم؟
شما دو گزینه اصلی دارید:
- اجرا به صورت local روی کامپیوتر خودتان(اگر سختافزار کافی دارید)
- استفاده از کلود/API
در این سلسله پست، ما عمدتاً از مدلها از طریق APIها در Hugging Face Hub استفاده خواهیم کرد. اما، نحوه اجرای این مدلها به صورت local در کورس LLM کلاس ویژن بحث شده است.
حالا که درکی از LLMها پیدا کردیم، وقت آن است که ببینیم چگونه LLMها خروجیهای خود را در یک بافت مکالمهای ساختاربندی میکنند.
برای اجرای این نوتبوک، به یک توکن Hugging Face نیاز دارید که میتوانید از https://hf.co/settings/tokens دریافت کنید.
برای اطلاعات بیشتر در مورد نحوه اجرای Jupyter Notebooks، به دوره رایگان آموزش پایتون برای هوش مصنوعی مراجعه کنید.
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 1

راهنمای قدم به قدم کرایه کارت گرافیک (GPU) با Vast.ai برای پروژههای هوش مصنوعی

دیدگاهتان را بنویسید