خود رمزگذار (اتو انکودر) چیست؟
خودرمزگذار چیست؟
خودرمزگذار (به انگلیسیautoencoder که اتو انکودر خوانده میشود) یک شبکه عصبی مصنوعی است که به طور کلی برای کد کردن اطلاعات (کدینگ) از آن استفاده میشود.
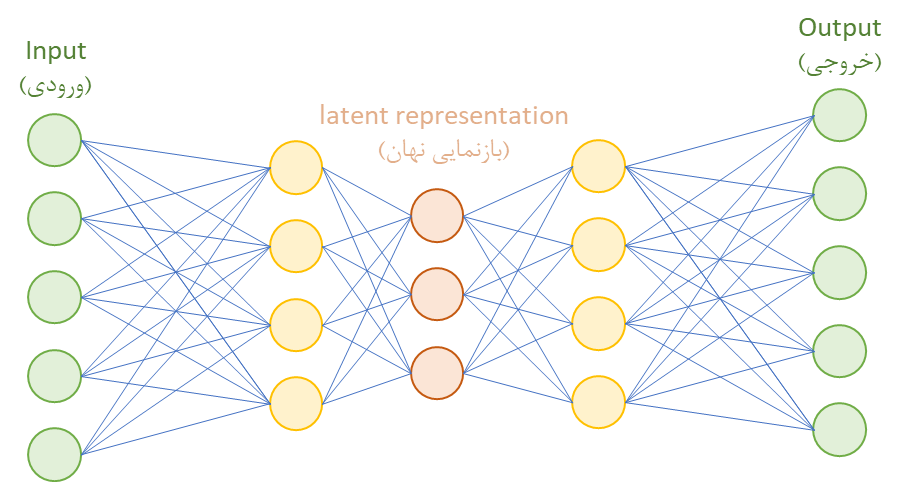
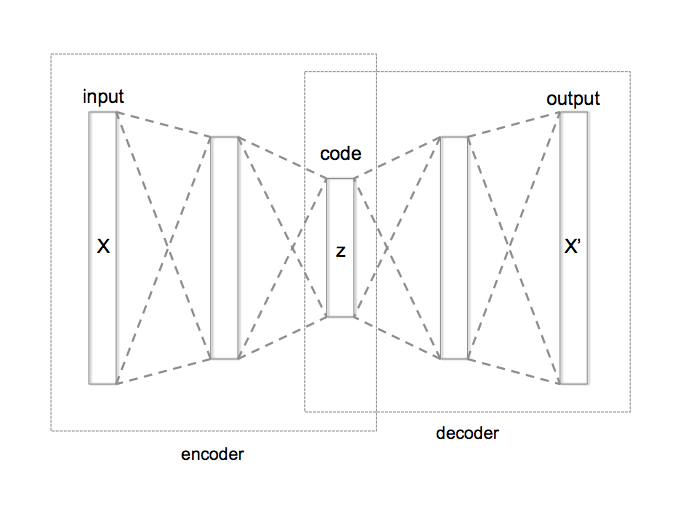
معماری یک خودرمزگذار در سادهترین حالت 3 لایه دارد: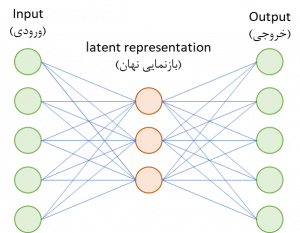
- لایه ورودی
- لایه کد یا بازنمایی نهان (Latent)
- لایه خروجی
این سه لایه دو قسمت اصلی این شبکه ها یعنی رمزگذار(Encoder) و رمزگشا(Decoder) را میسازند.
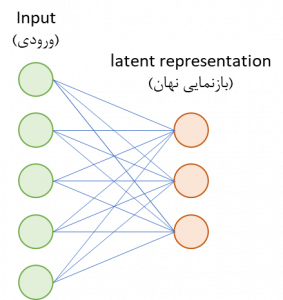
رمزگذار بخشی از شبکه است که نورونهای ورودی را به تعداد کمتری از نورونها فشرده می کند که این تعداد کم نورون های خروجی را “فضای نهان” یا “بازنمایی نهان” مینامیم.
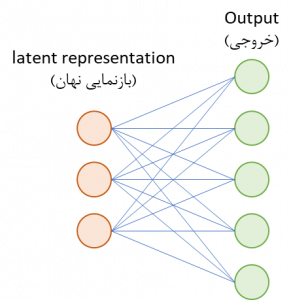
رمزگشا بخشی از شبکه است که از روی بازنمایی نهان در خروجی ورودی را از نو میسازد.
پس در ساده ترین حالت یک خودرمزگذار شامل یک encoder (رمزگذار) و decoder (رمزگشا) به همراه تنها یک لایه نهان میباشد. ورودی به encoder داده شده و خروجی از decoder استخراج میشود. در این نوع شبکه در ازای ورودی X ، خودرمزگذار آموزش میبیند که ورودی خود را بازسازی کند، بنابراین بردار خروجی همان ابعاد بردار ورودی X را خواهد داشت و تعداد نورونهای موجود در لایه ورودی و خروجی با یکدیگر برابر است.
در این شبکه خروجی بازسازی ورودی بوده و از الگوریتم پس انتشارخطا برای یادگیری استفاده میشود. خودرمزگذارها با حداقل کردن خطای بازسازی شبکه را آموزش میدهند.
لایه های بیشتر در خود رمزگذار
در این نوع شبکه ها برای عمیقتر کردن شبکه، میتوان بین ورودی و فضای نهان و همچنین بین فضای نهان و خروجی لایه های بیشتری قرار داد. معمولا تعداد نورون های لایه های میانی از ورودی و خروجی کمتر است، همچنین فضای نهان نیز معمولا کمترین تعداد نورون را دارد و در میانیترین لایه است.
برای سادگی رسم معمولا مختصرا این شبکه ها این گونه ترسیم میگردند.
لایه های کانولوشنالی در خود رمزگذار
اگر بخواهیم خودرمزگذارها را در کاربردهایی که مانند تصویر اطلاعات همسایگی نورون ها یا پیکسل ها اهمیت دارد استفاده کنیم میتوان به جای لایه های تمام-متصل از لایه های کانولوشنالی در رمزگذار(Encoder) استفاده کرد. اما با توجه به این که در رمزگشا(decoder) بعد کوچک شده و قرار است بعد را بزرگ کنیم معمولا از Transposed Convolution استفاده میگردد.
کاربردهای خود رمزگذار ها
کاهش حجم و فشرده سازی:
همان طور که مشاهده کردیم، با توجه به ابعاد کمتر لایه بازنمایی نهان نسبت به ورودی، و همچنین امکان بازسازی اطلاعات از روی بازنمایی نهان، از این شبکه ها برای فشرده سازی اطلاعات میتوان استفاده کرد. برای مثال فرض کنید میخواهید تصاویر را فشرده کنید و در شبکه ارسال کنید. فرستنده از رمزگذار(encoder) باید قبل ارسال اطلاعات استفاده کند و دریافت کننده باید از رمزگشا(decoder) استفاده کند تا از روی اطلاعات کد شده تصویر اصلی را بازیابی کند. قاعدتا فشرده سازی مطلوب و منطقی زمانی حاصل می شود که مشابه این تصویر در مجموعه آموزشی قبلا دیده شده باشد.
استخراج ویژگی:
از آنجایی که لایه کد یا بازنمایی نهان در حقیقت بازنمایی یا نمایش داده در فضای بعد کاهش یافته آن است، عملا متناظر با ویژگی های استخراج شده از داده ورودی است. میتوان بعد از آموزش کل شبکه خودرمزگذار، بخش رمزگشا را حذف کرد و خروجی لایه کد یا بزاینمایی نهان را به عنوان ویژگی های استخراج شده در نظر گرفت. (کاربردی مشابه PCA)
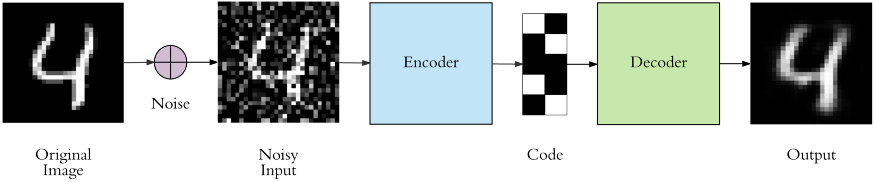
حذف نویز:
به جای اینکه ورودی و خروجی عینا یکسان باشند، میتوان در هنگام آموزش به وروی نویزی اضافه کرد و در خروجی بدون نویز را از شبکه طلب کرد! در این صورت بعد از آموزش خودرمزگذار را میتوان برای کاربرد حذف نویز استفاده کرد.
ایجاد ماسک یا سگمنت کردن
همانطور که برای کاربرد حذف نویز مشاهده شد، لزوما ورودی و خروجی این شبکه ها میتوانند یکسان نباشند، در این صورت میتوان یک تصویر را به عنوان ورودی داد و ماسک نواحی مورد توجه را به عنوان خروجی از شبکه طلب کرد. البته با توجه به این که این نوع کابرد طبقه بندی هر پیکسل محسوب میشود، علاوه بر تغییر تابع هزینه، عمق بیشتری برای این نوع خودرمزگذارها نیاز است. عمیق تر کردن این شبکه ها علاوه بر افزایش امکان محو شدگی گردیان، باعث از دست رفتن اطلاعات مکانی دقیق میشود. به همین منظور غالبا ایده هایی نظیر اتصلات U-Net در این کابرد استفاده میشود.
تشخیص ناهنجاری
خودرمزگذارها داده هایی که قبلا خود آنها یا مشابه آن ها را در فاز آموزش دیده باشند خیلی بهتر از داده هایی که تا کنون ندیده باشند بازسازی میکنند. با توجه به میزان خطای بازسازی (اختلاف خروجی و ورودی) میتوان فهمید که مشابه آیا این داده قبلا در حین آموزش مشاهده شده یا خیر. در کاربردهای تشخیص ناهنجاری هدف پیدا کردن داده ای است که مشابه داده های قبلی سالم نباشد و در نتیجه میتوان این کابرد را از این شبکه ها انتظار داشت.
کاربرد خودرمزگذار در Deep Fake
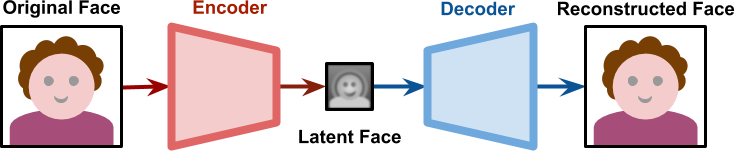
میتوان از یک شبکه خودرمزگذار برای تغییر چهره ی فرد الف با ب استفاده کرد، چیزی که به عنوان Deep-Fake معروف است. نمودار زیر یک چهره را نشان می دهد که به یک رمزگذار به عنوان ورودی داده شده و نتیجه آن یک بردار نهان از چهره با ابعادی معمولا پاین تر است که گاهی اوقات به عنوان بردار پایه یا چهره نهفته شناخته می شود. این بردار نهان هنگامی که از یک رمزگشا عبور می کند، چهره از روی بردار نهان بازسازی می شود. قاعدتا خودرمزگذارها بی خطا نیستند و دارای تلفات هستند، از این رو بعید است که چهره بازسازی شده همان سطحی از جزئیات را داشته باشد که در ابتدا وجود داشته.
حال برای کاربرد دیپفیک ما به دو خودرمزگذار نیاز خواهیم داشت. اگر دو خود رمزگذار را جداگانه آموزش دهیم، آنها با یکدیگر ناسازگار خواهند بود . چهرههای نهفته بر اساس ویژگیهای خاصی است که هر شبکه در طول فرآیند آموزشی خود معنادار تلقی کرده است ولی اگر دو خودرمزگذار به طور جداگانه برای چهرههای مختلف آموزش داده شوند، فضاهای پنهان آنها ویژگیهای کاملا متفاوت و مستقل از هم را نشان خواهند داد.
آنچه فناوری تعویض چهره یا Deep-Fake را ممکن میسازد، یافتن راهی است که هر دو چهره پنهان را مجبور به کدگذاری روی ویژگیهای یکسان کند. بدین منظور با داشتن رمزگذار مشترک بین هر دو شبکه در کنار استفاده از دو رمزگشای متفاوت مشابه شکل زیر است.
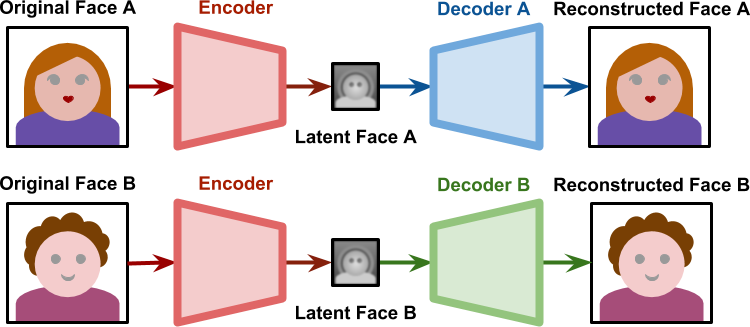
در مرحله آموزش، این دو شبکه به طور جداگانه آموزش می بینند. شبکه اول فقط با چهره های یک فرد(شخص A) آموزش داده می شود و شبکه دوم فقط با چهره های فرد دیگر(شخص B) آموزش داده می شود. با این حال، تمام چهره های نهفته توسط یک رمزگذار تولید می شوند. این بدان معنی است که رمزگذار خود باید ویژگی های مشترک در هر دو صورت را شناسایی کند. از آنجایی که همه چهرهها ساختار مشابهی دارند، غیرمنطقی نیست که انتظار داشته باشیم رمزگذار مفهوم «چهره» را خودش یاد بگیرد.
هنگامی که فرآیند آموزش کامل شد، میتوانیم یک چهره پنهان تولید شده از فرد A را به رمزگشای آموزش دیده شده روی فرد B منتقل کنیم. همانطور که در نمودار زیر مشاهده میشود، رمزگشای B سعی میکند شخص B را از اطلاعات مربوط به شخص A بازسازی کند.
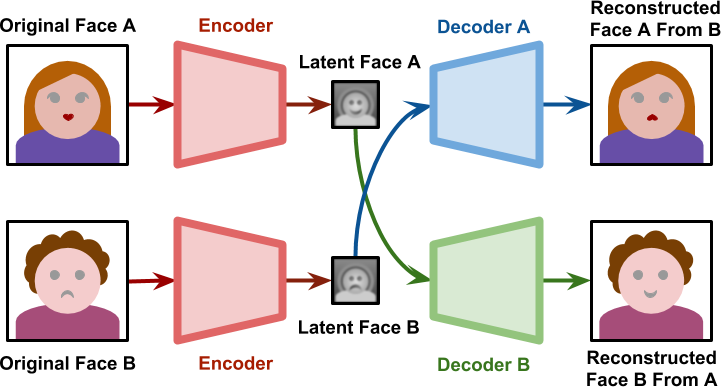
اگر شبکه به اندازه کافی چیزی را که یک چهره را می سازد تعمیم داده باشد، فضای پنهان بیانگر حالات و جهت گیری های صورت خواهد بود. این به معنای ایجاد یک چهره برای شخص B با همان بیان و جهت گیری شخص A خواهد بود.
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

عالی بود استاد گرامی
سلام بسیار استفاده کردم و خدا قوت
خیلی عالی
فقط آخراش یکم سخت شد و نیاز به توضیحات بیشتری داشت به نظرم
سپاس
بله. طبیعیه. واقعا آخرش سخت تر محسوب میشد
لطفاً ازین دست مطالب پایهای بیشتر محتوی قرار بدید. عالی بود. مرسی!
به روی چشم. ممنون از فیدبک