مقدمهای بر Reinforcement Learning و نقش آن در LLMها

در این پست قراره به Reinforcement Learning (RL) و تاثیر آن روی آموزش مدلهای زبانی بزرگ بپردازیم. تمرکز ما روی Reinforcement Learning برای مدلهای زبانی خواهد بود. البته Reinforcement Learning یا به اختصار RL که در فارسی یادگیری تقویتی نامیده میشود، حوزهی گستردهایست و کاربردهای زیاد و فراتر از مدلهای زبانی دارد.
حتی اگر تا به حال با این موضوغ آشنا نبوده باشید، این پست قصد دارد مفاهیم اصلی رو به سادهترین شکل توضیح داده و دلیل اهمیت RL در حوزهی Large Language Models را بررسی کند.
- Reinforcement Learning چیست؟
- اجزای اصلی RL
- فرایند یادگیری: آزمون و خطا
- نقش RL در مدلهای زبانی بزرگ (LLMs)
- Reinforcement Learning from Human Feedback (RLHF)
- چرا GRPO؟
Reinforcement Learning چیست؟
فرض کنید میخواید به یه سگ آموزش بدید بشینه. میگید “بشین!”، اگه نشست یه تشویقی و تحسین میگیره. اگه ننشست، شاید کمی راهنماییش کنید یا دوباره تلاش کنید. کمکم سگ یاد میگیره که نشستن با تشویقی همراهه و دفعهی بعدی که “بشین!” بشنوه، احتمال اینکه بشینه بیشتر میشه. توی RL، به این بازخورد میگیم reward.
خلاصهی قضیه همینه! به جای سگ، یه language model داریم (که توی RL بهش agent میگیم)، و به جای شما، یه environment که بازخورد میده.
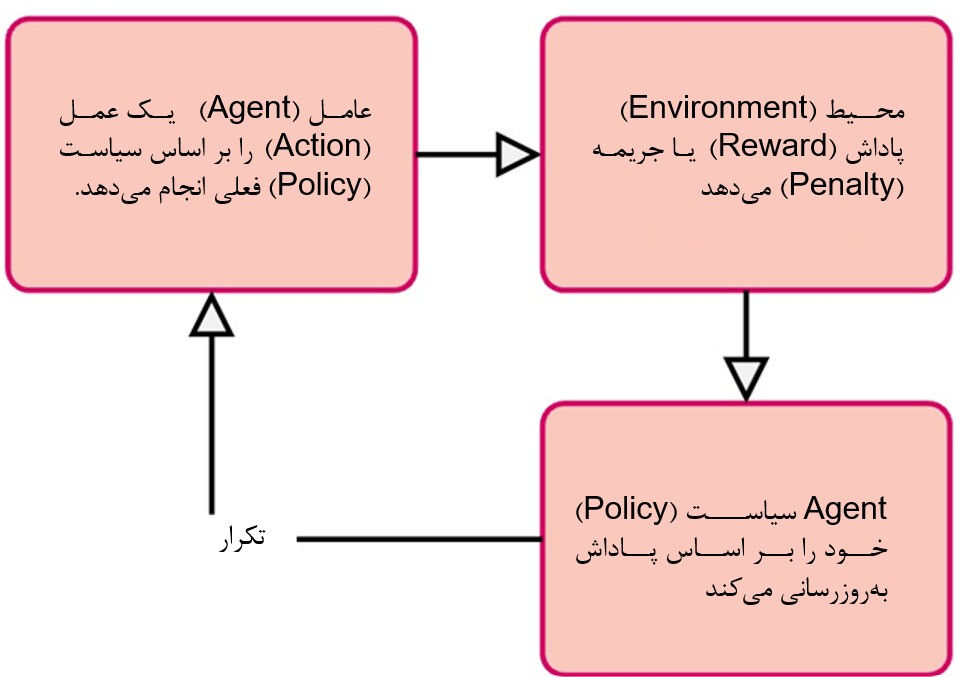
اجزای اصلی RL
- Agent
یادگیرندهی ماست. توی مثال سگ، خود سگ agent است. برای LLM، خود مدل زبانی agent محسوب شده که آموزش میبیند. - Environment
دنیایی که agent توش زندگی میکنه و باهاش تعامل داره. برای سگ، محیط خونه و شما هستید. برای LLM، محیط میتونه کاربران یا سناریوی شبیهسازیشدهای باشه که براش درست میکنیم. محیط همواره بازخورد (reward) میده. - Action
انتخابهایی که agent میتونه بکنه. برای سگ، “بشین”، “پاشو”، “پارس کن” و غیره. برای LLM ما، actionها میتوانند تولید کلمات در جمله، انتخاب پاسخ به سؤال یا چگونگی واکنش در مکالمه باشه. - Reward
بازخوردی که محیط بعد از هر action میده. معمولاً عددی است.- Positive rewards مثل تشویقی و تحسین: “آفرین، کارت درسته!”
- Negative rewards (penalties): یه “نه” ملایم که میگه “این درست نبود، چیز دیگهای امتحان کن”.
- Policy
استراتژی agent برای انتخاب action. مثل فهم سگ از اینکه وقتی “بشین!” میشنوه باید بشینه. در RL، هدف اصلی همینه که policy رو یاد بگیریم و بهبود بدیم.
فرایند یادگیری: آزمون و خطا
یادگیری تقویتی (Reinforcement Learning) از طریق فرایند آزمون و خطا انجام میشود.
| مرحله | فرآیند | توضیح |
|---|---|---|
| 1.مشاهده(Observation) | عامل (Agent) محیط را مشاهده میکند | اطلاعاتی دربارهی وضعیت فعلی و اطراف خود دریافت میکند. |
| 2.عمل (Action) | عامل بر اساس سیاست فعلی خود یک عمل انجام میدهد | با استفاده از سیاست (Policy) یادگرفتهشده، تصمیم میگیرد که چه کاری انجام دهد. |
| 3.بازخورد(Feedback) | محیط به عامل پاداش میدهد | عامل بازخوردی دریافت میکند که نشان میدهد عملش چقدر خوب یا بد بوده است. |
| 4.یادگیری(Learning) | عامل سیاست خود را بر اساس پاداش بهروزرسانی میکند | استراتژی خود را اصلاح میکند: اعمال مؤثر منجر به پاداش را تقویت کرده و از اعمال با پاداش کم اجتناب میکند. |
| 5.تکرار(Iteration) | فرآیند تکرار میشود | این چرخه ادامه مییابد و به عامل کمک میکند تا تصمیمگیری خود را بهطور مداوم بهبود بخشد. |
مثل یادگیری دوچرخهسواری: اول ممکنه بیثبات باشی و بیفتی (negative reward!)، اما وقتی متعادل میشی و خوب پدال میزنی، حس خوبی داری (positive reward!) و بر اساس همین بازخوردها حرکاتت اصلاح میشه. یادگیری تقویتی هم مشابه همین است! یادگیری از طریق تعامل و بازخورد.
نقش RL در مدلهای زبانی بزرگ (LLMs)
آموزش مدلهای زبانی قدرتمند، کار سختیه. با pre-training روی حجم عظیمی از متنها، مدل یاد میگیره کلمهی بعدی رو پیشبینی کنه و متن روان و درست بسازه. اما فقط روان بودن کافی نیست؛ میخوایم مدلها:
- Helpful: اطلاعات مفید و مرتبط بدن.
- Harmless: از تولید محتوای سمی یا جانبدارانه پرهیز کنن.
- Aligned with Human Preferences: طوری واکنش بدن که برای انسانها طبیعی، مفید و جذاب باشه.
Pre-training و supervised training گاهی در این موارد ضعف دارن. مدلهای fine-tuned ممکنه متن ساختاری و روان بسازن ولی برحق نباشن یا سؤال کاربر رو واقعاً جواب ندن. اینجاست که Reinforcement Learning وارد عمل میشه!
Reinforcement Learning from Human Feedback (RLHF)
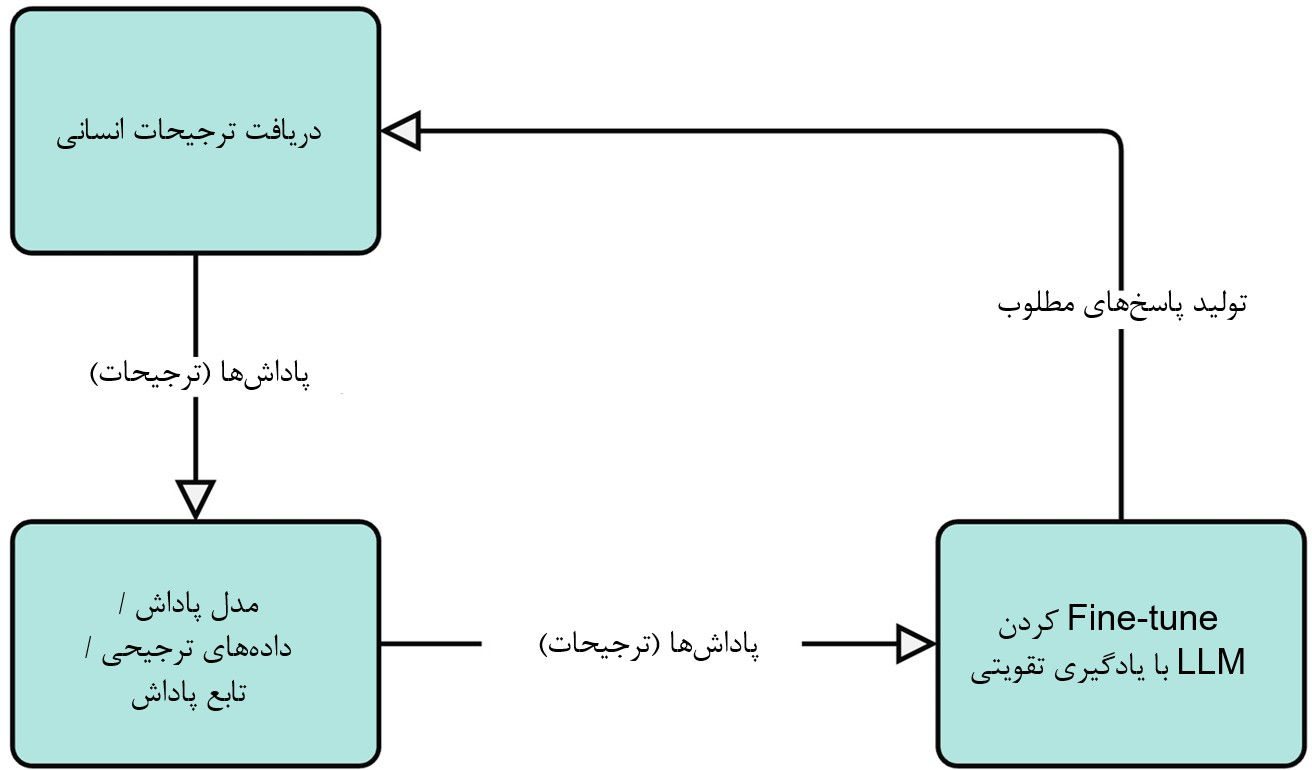
یک تکنیک بسیار رایج برای همراستا کردن مدلهای زبانی، یادگیری تقویتی با بازخورد انسانی (RLHF) است. در RLHF، از بازخورد انسانی بهعنوان جایگزینی برای سیگنال «پاداش» در یادگیری تقویتی استفاده میکنیم. روند کار به این صورت است:
۱. دریافت ترجیحات انسانی:
ما ممکن است از انسانها بخواهیم پاسخهای مختلفی را که مدل زبانی بزرگ (LLM) برای یک ورودی تولید کرده مقایسه کنند و بگویند کدام پاسخ را ترجیح میدهند.
مثلاً به یک انسان دو پاسخ مختلف به سؤال «پایتخت ایران چیست؟» را نشان میدهیم و از او میپرسیم: «کدام پاسخ بهتر است؟»
۲. آموزش یک مدل پاداش:
از این دادههای ترجیح انسانی برای آموزش مدلی جداگانه به نام مدل پاداش (Reward Model) استفاده میکنیم.
این مدل یاد میگیرد که پیشبینی کند انسانها چه نوع پاسخهایی را ترجیح میدهند. همچنین پاسخها را بر اساس معیارهایی مانند مفید بودن، بیخطر بودن، و همراستایی با ترجیحات انسانی امتیازدهی میکند.
۳. Fine-tune کردن LLM با RL:
در این مرحله، از مدل پاداش بهعنوان محیط برای عامل LLM استفاده میکنیم.
LLM پاسخهایی تولید میکند (عمل)، و مدل پاداش این پاسخها را امتیازدهی میکند (پاداش میدهد).
در واقع، ما در حال آموزش LLM برای تولید متنی هستیم که مدل پاداش (که از ترجیحات انسانی آموخته) آن را خوب میداند.
از دیدگاهی کلی، بیایید به مزایای استفاده از یادگیری تقویتی (RL) در مدلهای زبانی بزرگ (LLMها) نگاهی بیندازیم:
| مزیت | توضیح |
|---|---|
| کنترل بهتر | یادگیری تقویتی به ما امکان میدهد تا کنترل بیشتری روی نوع متنی که مدلهای زبانی تولید میکنند داشته باشیم. ما میتوانیم آنها را راهنمایی کنیم تا متونی تولید کنند که با اهداف خاصی مانند مفید بودن، خلاقانه بودن یا مختصر بودن هماهنگ باشند. |
| هماهنگی بهتر با ارزشهای انسانی | بهطور خاص، RLHF به ما کمک میکند تا مدلهای زبانی را با ترجیحات انسانی پیچیده و اغلب ذهنی هماهنگ کنیم. نوشتن قوانین مشخص برای «چه چیزی یک پاسخ خوب را میسازد» دشوار است، اما انسانها میتوانند به راحتی پاسخها را قضاوت و مقایسه کنند. RLHF به مدل اجازه میدهد از این قضاوتهای انسانی یاد بگیرد. |
| کاهش رفتارهای نامطلوب | RL میتواند برای کاهش رفتارهای منفی در مدلهای زبانی استفاده شود، مانند تولید زبان سمی، گسترش اطلاعات نادرست یا نشان دادن سوگیریها. با طراحی پاداشهایی که این رفتارها را جریمه میکنند، میتوانیم مدل را بهسمت اجتناب از آنها سوق دهیم. |
یادگیری تقویتی از بازخورد انسانی (RLHF) برای آموزش بسیاری از مدلهای زبانی محبوب امروزی استفاده شده است، از جمله GPT-4 شرکت OpenAI و Gemini گوگل، و R1 از DeepSeek.
تکنیکهای متنوعی برای پیادهسازی RLHF وجود دارد که از نظر پیچیدگی و پیشرفت، سطوح متفاوتی دارند.
در این سلسله پستها، ما بر روی Group Relative Policy Optimization (GRPO) تمرکز خواهیم کرد، که روشی مؤثر برای آموزش مدلهای زبانی است تا خروجیهایی مفید، بیضرر و منطبق با ترجیحات انسانی تولید کنند.
چرا باید به GRPO (بهینهسازی سیاست نسبی گروهی) اهمیت بدهیم؟
تکنیکهای زیادی برای RLHF (یادگیری تقویتی از بازخورد انسانی) وجود دارد، اما این سلسله پستها بر GRPO تمرکز دارد، زیرا این روش پیشرفت قابلتوجهی در یادگیری تقویتی برای مدلهای زبانی بهشمار میرود.
بیایید بهطور خلاصه دو تکنیک محبوب دیگر در RLHF را مرور کنیم:
-
Direct Preference Optimization (DPO)
PPO یکی از نخستین و مؤثرترین تکنیکها برای RLHF بود. این روش از الگوریتم گرادیان سیاست برای بهروزرسانی سیاست بر اساس پاداش دریافتی از یک مدل پاداش جداگانه استفاده میکند.
PPO به زبان ساده: چگونه هوش مصنوعی یاد میگیرد مثل ما فکر کند؟
DPO بعدها به عنوان روشی سادهتر توسعه یافت که نیاز به مدل پاداش جداگانه را حذف میکند و مستقیماً از دادههای ترجیح استفاده میکند. اساساً این روش مسئله را بهصورت یک مسئله طبقهبندی بین پاسخ انتخابشده و پاسخ ردشده در نظر میگیرد.
PPO و DPO هر دو الگوریتمهای پیچیده یادگیری تقویتی هستند. اگر علاقهمند هستید بیشتر درباره آنها بدانید، میتوانید منابع زیر را بررسی کنید:
برخلاف DPO و PPO،روش GRPO نمونههای مشابه را گروهبندی کرده و آنها را بهصورت گروهی با یکدیگر مقایسه میکند. این رویکرد مبتنی بر گروه، گرادیانهای پایدارتر و ویژگیهای همگرایی بهتری نسبت به سایر روشها ارائه میدهد.
GRPO مانند DPO از دادههای ترجیح استفاده نمیکند، بلکه گروههایی از نمونههای مشابه را با استفاده از سیگنال پاداش دریافتی از یک مدل یا تابع با یکدیگر مقایسه میکند.
GRPO در نحوه دریافت سیگنال پاداش انعطافپذیر است – میتواند با یک مدل پاداش (مشابه PPO) کار کند، اما بهطور الزامآور به آن نیاز ندارد. دلیلش این است که GRPO میتواند سیگنال پاداش را از هر تابع یا مدلی که قادر به ارزیابی کیفیت پاسخها باشد، دریافت کند.
برای مثال، میتوانیم از یک تابع طول برای پاداش دادن به پاسخهای کوتاهتر، یک حلکننده ریاضی برای بررسی درستی راهحل، یا تابعی برای صحت اطلاعات استفاده کنیم تا پاسخهایی که دقیقتر هستند پاداش بگیرند. این انعطافپذیری، GRPO را به ابزاری بسیار کاربردی برای انواع مختلف وظایف همترازی تبدیل میکند.
تبریک! شما بخش اول را به پایان رساندید!
شما اکنون درک خوبی از یادگیری تقویتی و نقش کلیدی آن در شکلدادن به آینده مدلهای زبانی بزرگ (LLMها) دارید. مفاهیم پایه RL را آموختید، دلایل استفاده از آن برای LLMها را فهمیدید و با الگوریتم کلیدی GRPO آشنا شدید.
در بخش بعدی، وارد جزئیات مقاله DeepSeek R1 خواهیم شد تا ببینیم این مفاهیم در عمل چگونه پیادهسازی میشوند!
منبع: https://huggingface.co/learn/llm-course/chapter12/2
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

دیدگاهتان را بنویسید