درک مقاله DeepSeek R1

فهرست مطالب
در بخش قبلی، مقدمهای بر Reinforcement Learning و نقش آن در LLMها را مشاهده کردیم. در این پست ما مقاله را با زبانی ساده بررسی کرده و سپس مفاهیم کلیدی و نکات اصلی آن را تشریح میکنیم.
DeepSeek R1 پیشرفت قابل توجهی در آموزش مدلهای زبانی، به ویژه در توسعه قابلیتهای استدلال از طریق یادگیری تقویتی (Reinforcement Learning)، نشان میدهد. این مقاله یک الگوریتم جدید یادگیری تقویتی به نام «بهینهسازی خطمشی نسبی گروهی» (Group Relative Policy Optimization – GRPO) را معرفی میکند.
در بخش بعدی، بر اساس این دانش، GRPO را در عمل پیادهسازی خواهیم کرد.
هدف اولیه مقاله این بود که بررسی کند آیا یادگیری تقویتی خالص (pure reinforcement learning) میتواند قابلیتهای استدلال را بدون fine-tuning نظارتشده (supervised) توسعه دهد یا خیر.
تا آن زمان، تمام مدلهای زبانی بزرگ (LLM) محبوب نیاز به مقداری fine-tuning نظارتشده داشتند…
لحظه دستیابی به بینش ناگهانی (Aha Moment)

یکی از قابلتوجهترین اکتشافات در آموزش R1-Zero، ظهور پدیدهای بود که به عنوان «لحظه آها» (Aha Moment) یا «لحظه مکاشفه» شناخته میشود. این پدیده تا حدودی شبیه به نحوه تجربه انسانها از درک ناگهانی هنگام حل مسئله است. نحوه کار آن به این صورت است:
- تلاش اولیه (Initial Attempt): مدل یک تلاش اولیه برای حل مسئله انجام میدهد.
- تشخیص (Recognition): مدل خطاها یا ناسازگاریهای بالقوه را تشخیص میدهد.
- خود-اصلاحی (Self-Correction): مدل رویکرد خود را بر اساس این تشخیص تنظیم میکند.
- توضیح (Explanation): مدل میتواند توضیح دهد که چرا رویکرد جدید بهتر است.
این پیشرفت شگرف با یادگیرندگان طنینانداز میشود و احساسی شبیه به لحظه «یافتم!» (Eureka) ایجاد میکند. این نشاندهنده یادگیری است تا صرفاً حفظ کردن، پس بیایید لحظهای تصور کنیم که داشتن یک «لحظه آها» چه حسی دارد.
برای مثال، تصور کنید در حال حل یک پازل هستید:
- تلاش اول: «این قطعه باید بر اساس رنگ اینجا قرار بگیرد.»
- تشخیص: «اما صبر کن، شکل آن کاملاً مناسب نیست.»
- اصلاح: «آها، در واقع به آنجا تعلق دارد.»
- توضیح: «زیرا هم رنگ و هم الگوی شکل در این موقعیت مطابقت دارند.»
این قابلیت به طور طبیعی از آموزش یادگیری تقویتی (RL training) پدیدار شد، بدون اینکه به صراحت برنامهریزی شده باشد، که نشاندهنده یادگیری است تا صرفاً حفظ کردن یک فرآیند از دادههای آموزشی.
سادهترین راه برای درک «لحظه آها» دیدن آن در عمل است. بیایید به یک مثال نگاه کنیم. در چت زیر، از مدل میخواهیم مشکلی را حل کند و رابط کاربری (UI) فرآیند فکری مدل را در حین حل مسئله نشان میدهد.
اگر میخواهید R1 شرکت Deepseek را امتحان کنید، میتوانید Hugging Chat را نیز بررسی کنید.
فرآیند آموزش
آموزش R1 یک فرآیند چند مرحلهای بود. بیایید مراحل و نوآوریهای کلیدی در هر مرحله را بررسی کنیم.
نسخههای نهایی مدل
فرآیند نهایی منجر به دو مدل میشود:
- DeepSeek-R1-Zero: مدلی که صرفاً با استفاده از یادگیری تقویتی آموزش دیده است.
- DeepSeek-R1: مدلی که بر پایه DeepSeek-R1-Zero ساخته شده و supervised fine-tuning به آن اضافه شده است.
| ویژگی | DeepSeek-R1-Zero | DeepSeek-R1 |
|---|---|---|
| رویکرد آموزش | یادگیری تقویتی خالص (Pure RL) | چند مرحلهای (SFT + RL) |
| Fine-tuning | ندارد | Supervised fine-tuning |
| قابلیت استدلال | پدیدار شده (Emergent) | تقویتشده (Enhanced) |
| عملکرد AIME | 71.0% | 79.8% |
| ویژگیهای کلیدی | استدلال قوی اما مشکلات خوانایی | سازگاری و خوانایی بهتر زبان |
در حالی که DeepSeek-R1-Zero پتانسیل یادگیری تقویتی خالص را برای توسعه قابلیتهای استدلال نشان میدهد، DeepSeek-R1 بر این اساس با رویکردی متعادلتر بنا شده است که هم عملکرد استدلال و هم قابلیت استفاده را در اولویت قرار میدهد.
فرآیند آموزش شامل چهار مرحله است:
- فاز شروع سرد (Cold Start Phase)
- فاز یادگیری تقویتی برای استدلال (Reasoning RL Phase)
- فاز نمونهبرداری با رد (Rejection Sampling Phase)
- فاز یادگیری تقویتی متنوع (Diverse RL Phase)
بیایید هر مرحله را بررسی کنیم:
فاز شروع سرد (Cold Start Phase – بنیان کیفیت)

این مرحله برای ایجاد یک بنیان قوی برای خوانایی و کیفیت پاسخ مدل طراحی شده است. از مجموعه داده کوچکی از نمونههای با کیفیت بالا از R1-Zero برای fine-tuning مدل V3-Base استفاده میکند. با شروع از مدل DeepSeek-V3-Base، تیم از هزاران نمونه معتبر و با کیفیت بالا از R1-Zero برای supervised fine-tuning استفاده کرد.
این رویکرد نوآورانه از یک مجموعه داده کوچک اما با کیفیت بالا برای ایجاد خوانایی پایه قوی و کیفیت پاسخ استفاده میکند.
فاز یادگیری تقویتی برای استدلال (Reasoning RL Phase – ساخت قابلیت)

فاز یادگیری تقویتی برای استدلال بر توسعه قابلیتهای اصلی استدلال در حوزههایی از جمله ریاضیات، کدنویسی، علوم و منطق تمرکز دارد. این مرحله از یادگیری تقویتی مبتنی بر قاعده (rule-based reinforcement learning) استفاده میکند، که در آن پاداشها (rewards) مستقیماً به صحت راهحل مرتبط هستند.
نکته بسیار مهم این است که تمام وظایف در این مرحله «قابل تأیید» (verifiable) هستند، بنابراین میتوانیم بررسی کنیم که آیا پاسخ مدل صحیح است یا خیر. به عنوان مثال، در مورد ریاضیات، میتوانیم با استفاده از یک حلکننده ریاضی (mathematical solver) صحت پاسخ مدل را بررسی کنیم.
آنچه این مرحله را بهویژه نوآورانه میکند، رویکرد بهینهسازی مستقیم آن است که نیاز به یک مدل پاداش (reward model) جداگانه را از بین میبرد و فرآیند آموزش را سادهتر میکند.
فاز نمونهبرداری با رد (Rejection Sampling Phase – کنترل کیفیت)

در طول فاز نمونهبرداری با رد، مدل نمونههایی تولید میکند که سپس از طریق یک فرآیند کنترل کیفیت فیلتر میشوند. DeepSeek-V3 به عنوان داور کیفیت عمل میکند و خروجیها را در گستره وسیعی که فراتر از وظایف استدلال خالص است، ارزیابی میکند. دادههای فیلتر شده سپس برای supervised fine-tuning استفاده میشوند. نوآوری این مرحله در توانایی آن برای ترکیب چندین سیگنال کیفیت برای اطمینان از خروجیهای با استاندارد بالا نهفته است.
فاز یادگیری تقویتی متنوع (Diverse RL Phase – همترازی گسترده)

فاز نهایی یادگیری تقویتی متنوع با استفاده از یک رویکرد ترکیبی پیچیده به انواع مختلف وظایف میپردازد. برای وظایف قطعی (deterministic tasks)، از پاداشهای مبتنی بر قاعده استفاده میکند، در حالی که وظایف ذهنی (subjective tasks) از طریق بازخورد مدل زبانی بزرگ (LLM feedback) ارزیابی میشوند. این مرحله با رویکرد پاداش ترکیبی نوآورانه خود، با ترکیب دقت سیستمهای مبتنی بر قاعده با انعطافپذیری ارزیابی مدل زبانی، به دنبال دستیابی به همترازی با ترجیحات انسانی (human preference alignment) است.
الگوریتم: بهینهسازی خطمشی نسبی گروهی (GRPO – Group Relative Policy Optimization)
اکنون که درک خوبی از فرآیند آموزش داریم، بیایید به الگوریتمی که برای آموزش مدل استفاده شده است نگاه کنیم.
نویسندگان GRPO را به عنوان یک پیشرفت شگرف در fine-tuning مدل توصیف میکنند:

نوآوری GRPO در ظرفیت آن برای «بهینهسازی مستقیم برای اصلاح ترجیحات» (directly optimize for preference rectification) نهفته است.بر خلاف الگوریتمهای سنتی یادگیری تقویتی مانند PPO این نشاندهنده مسیری مستقیمتر و کارآمدتر برای همتراز کردن مدل با خروجیهای مطلوب است.
بیایید نحوه عملکرد GRPO را از طریق سه جزء اصلی آن بررسی کنیم:
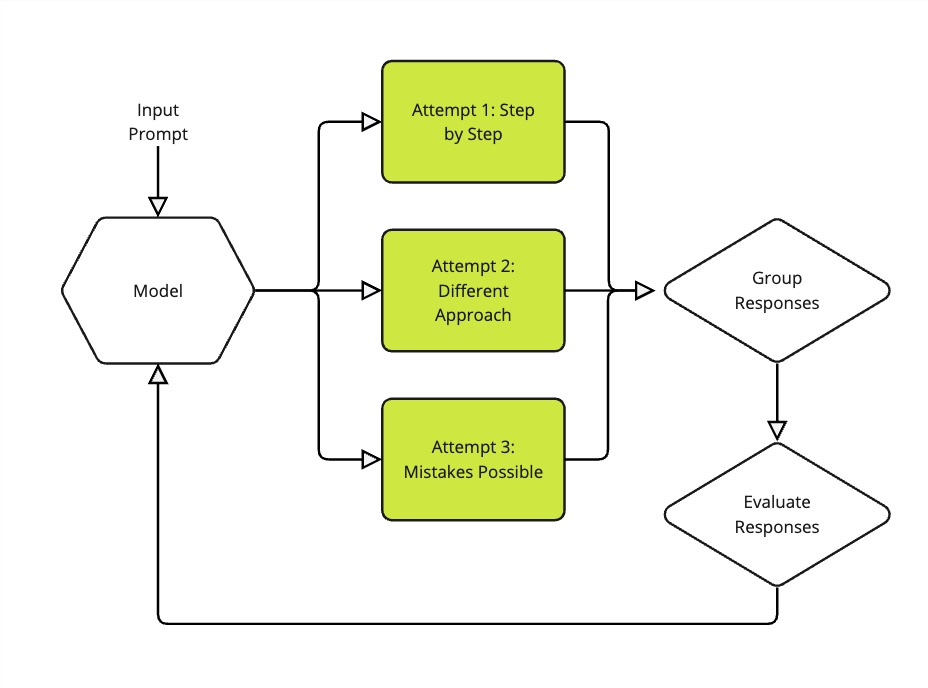
تشکیل گروه: ایجاد چندین راهحل
اولین گام در GRPO به طرز قابل توجهی شهودی است – شبیه به نحوه حل یک مسئله دشوار توسط یک دانشآموز با امتحان کردن چندین رویکرد است. هنگامی که یک پرامپت (prompt) داده میشود، مدل فقط یک پاسخ تولید نمیکند؛ در عوض، چندین تلاش برای حل همان مسئله ایجاد میکند (معمولاً ۴، ۸ یا ۱۶ تلاش مختلف).
تصور کنید در حال آموزش مدلی برای حل مسائل ریاضی هستید. برای سؤالی در مورد شمردن جوجهها در یک مزرعه، مدل ممکن است چندین راهحل مختلف تولید کند:
- یک راهحل ممکن است مسئله را گام به گام تجزیه کند: ابتدا شمارش کل جوجهها، سپس کم کردن خروسها و در نهایت در نظر گرفتن مرغهای غیر تخمگذار.
- راهحل دیگر ممکن است از رویکردی متفاوت اما به همان اندازه معتبر استفاده کند.
- برخی تلاشها ممکن است حاوی اشتباهات یا راهحلهای کمبازده باشند.
همه این تلاشها به عنوان یک گروه با هم نگهداری میشوند، بسیار شبیه به داشتن راهحلهای چندین دانشآموز برای مقایسه و یادگیری از آنها.
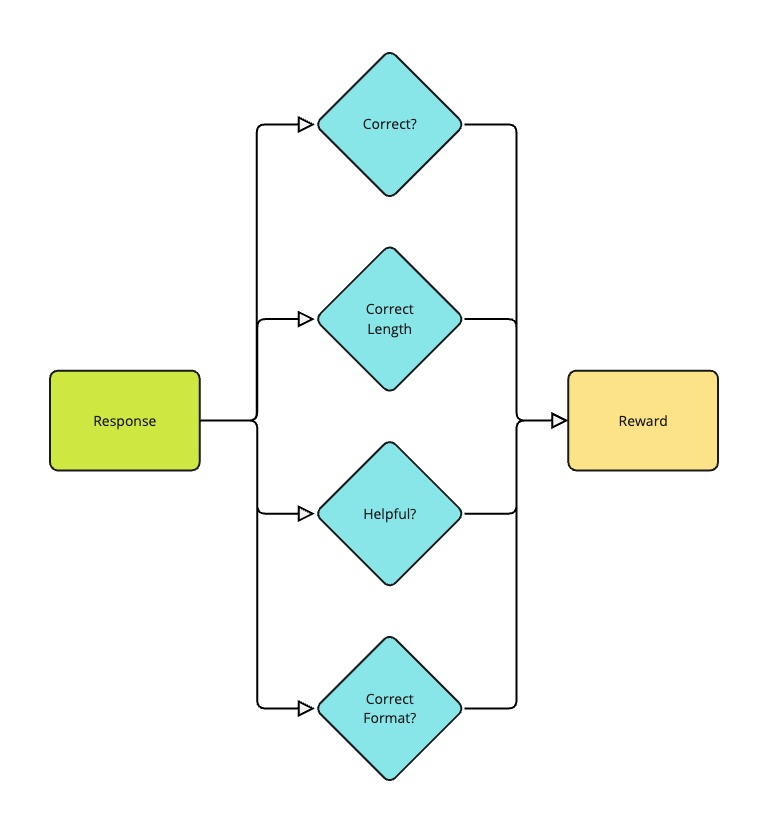
یادگیری ترجیحات (Preference Learning): درک اینکه چه چیزی یک راهحل خوب را میسازد
اینجاست که واقعاً سادگی GRPO نمایان میشود. برخلاف سایر روشهای یادگیری تقویتی از بازخورد انسانی (RLHF) که همیشه به یک مدل پاداش جداگانه برای پیشبینی میزان خوب بودن یک راهحل نیاز دارند، GRPO میتواند از هر تابع یا مدلی برای ارزیابی کیفیت یک راهحل استفاده کند. به عنوان مثال، میتوانیم از یک تابع طول برای پاداش دادن به پاسخهای کوتاهتر یا از یک حلکننده ریاضی برای پاداش دادن به راهحلهای ریاضی دقیق استفاده کنیم.
فرآیند ارزیابی به جنبههای مختلف هر راهحل نگاه میکند:
- آیا پاسخ نهایی صحیح است؟
- آیا راهحل از قالببندی مناسبی (مانند استفاده از تگهای XML صحیح) پیروی کرده است؟
- آیا استدلال با پاسخ ارائه شده مطابقت دارد؟
آنچه این رویکرد را بهویژه هوشمندانه میکند، نحوه مدیریت امتیازدهی است. GRPO به جای دادن امتیازات مطلق، پاداشها را در هر گروه نرمالسازی میکند. از یک فرمول ساده اما مؤثر برای تخمین مزیت نسبی گروهی (group relative advantage estimation) استفاده میکند:
Advantage = (reward – mean(group_rewards)) / std(group_rewards)
این نرمالسازی مانند نمرهدهی بر اساس منحنی (grading on a curve) است، اما برای هوش مصنوعی. این به مدل کمک میکند بفهمد کدام راهحلها در گروه نسبت به همتایان خود بهتر یا بدتر بودهاند، به جای اینکه فقط به امتیازات مطلق نگاه کند.
بهینهسازی: یادگیری از تجربه
گام نهایی جایی است که GRPO به مدل یاد میدهد تا بر اساس آنچه از ارزیابی گروه راهحلها آموخته است، بهبود یابد. این فرآیند هم قدرتمند و هم پایدار است و از دو اصل اصلی استفاده میکند:
- مدل را تشویق میکند تا راهحلهای بیشتری مانند راهحلهای موفق تولید کند، در حالی که از رویکردهای کماثرتر دور میشود.
- شامل یک مکانیزم ایمنی (به نام جریمه واگرایی KL یا KL divergence penalty) است که از تغییر بیش از حد شدید و ناگهانی مدل جلوگیری میکند.
این رویکرد پایدارتر از روشهای سنتی است زیرا:
- به جای مقایسه تنها دو راهحل در یک زمان، چندین راهحل را با هم بررسی میکند.
- نرمالسازی مبتنی بر گروه به جلوگیری از مشکلات مربوط به مقیاسبندی پاداش (reward scaling) کمک میکند.
- جریمه KL مانند یک شبکه ایمنی عمل میکند و تضمین میکند که مدل در حین یادگیری چیزهای جدید، آنچه را که قبلاً میداند فراموش نمیکند.
نوآوریهای کلیدی GRPO عبارتند از:
- یادگیری مستقیم از هر تابع یا مدلی، که وابستگی به یک مدل پاداش جداگانه را از بین میبرد.
- یادگیری مبتنی بر گروه، که پایدارتر و کارآمدتر از روشهای سنتی مانند مقایسههای زوجی (pairwise comparisons) است.
این تشریح پیچیده است، اما نکته کلیدی این است که GRPO روشی کارآمدتر و پایدارتر برای آموزش یک مدل به منظور استدلال کردن است.
الگوریتم GRPO در شبهکد
اکنون که اجزای کلیدی GRPO را درک کردیم، بیایید به الگوریتم در شبهکد نگاه کنیم. این یک نسخه سادهشده از الگوریتم است، اما ایدههای اصلی را در بر میگیرد.
ورودیها:
- initial_policy: مدل اولیهای که قرار است آموزش ببیند
- reward_function: تابعی که خروجیها را ارزیابی میکند
- training_prompts: مجموعهای از نمونههای آموزشی
- group_size: تعداد خروجیها به ازای هر پرامپت (معمولاً بین ۴ تا ۱۶)
الگوریتم GRPO:
- برای هر تکرار آموزشی:
- الف) reference_policy را برابر با initial_policy قرار بده (اسنپ شات از وضعیت فعلی مدل یا همون کپی کردن آن)
- ب) برای هر پرامپت (for) در دسته آموزشی:
-
-
- i. تعداد group_size خروجی مختلف با استفاده از initial_policy تولید کن
- ii. با استفاده از reward_function برای هر خروجی، پاداش را محاسبه کن
- iii. پاداشها را درون هر گروه نرمالسازی کن:
-
normalized_advantage = (reward - میانگین پاداشها) / انحراف معیار پاداشها
-
- iv. مدل را با بیشینهسازی نسبت بریده شده (clipped ratio) بهروزرسانی کن:
min(prob_ratio * normalized_advantage, clip(prob_ratio, 1 - epsilon, 1 + epsilon) * normalized_advantage)
kl_weight * KL(initial_policy || reference_policy)
که در آن:
prob_ratio = احتمال فعلی / احتمال مرجع
خروجی: مدل سیاست (policy) بهینهشده
این الگوریتم نشان میدهد که چگونه GRPO تخمین مزیت مبتنی بر گروه را با بهینهسازی خطمشی ترکیب میکند، در حالی که پایداری را از طریق محدودیتهای برش (clipping) و واگرایی KL (KL divergence) حفظ میکند.
نتایج و تأثیرات
اکنون که الگوریتم را بررسی کردیم، بیایید به نتایج نگاه کنیم. DeepSeek R1 در چندین حوزه به عملکرد پیشرفته (state-of-the-art) دست مییابد:
| حوزه | نتایج کلیدی |
|---|---|
| ریاضیات (Mathematics) | • 79.8% در AIME 2024 • 97.3% در MATH-500 |
| کدنویسی (Coding) | • رتبه Codeforces: 2029 • LiveCodeBench: 65.9% |
| دانش عمومی (General Knowledge) | • MMLU: 90.8% • GPQA Diamond: 71.5% |
| وظایف زبانی (Language Tasks) | • AlpacaEval 2.0: نرخ پیروزی 87.6% • FRAMES: 82.5% |
تأثیر عملی مدل فراتر از معیارها (benchmarks) از طریق قیمتگذاری مقرونبهصرفه API آن (۰.۱۴ دلار به ازای هر میلیون توکن ورودی) و تقطیر موفقیتآمیز مدل (model distillation) در اندازههای مختلف (پارامترهای 1.5B تا 70B) گسترش مییابد. قابل ذکر است که حتی مدل 7B به ۵۵.۵٪ در AIME 2024 دست مییابد، در حالی که نسخه تقطیر شده 70B به عملکرد o1-mini در MATH-500 (۹۴.۵٪) نزدیک میشود، که نشاندهنده حفظ مؤثر قابلیت در مقیاسهای مختلف است.
محدودیتها و چالشهای GRPO
در حالی که GRPO پیشرفت قابل توجهی در یادگیری تقویتی برای مدلهای زبانی نشان میدهد، درک محدودیتها و چالشهای آن مهم است:
- هزینه تولید (Generation Cost):
تولید چندین تکمیل (completion) (۴-۱۶) برای هر پرامپت، نیازمندیهای محاسباتی را در مقایسه با روشهایی که تنها یک یا دو تکمیل تولید میکنند، افزایش میدهد. - محدودیتهای اندازه بچ (Batch Size Constraints):
نیاز به پردازش گروههایی از تکمیلها با هم میتواند اندازههای مؤثر بچ را محدود کند، که به فرآیند آموزش پیچیدگی میافزاید و به طور بالقوه آموزش را کند میکند. - طراحی تابع پاداش (Reward Function Design):
کیفیت آموزش به شدت به توابع پاداش خوب طراحیشده بستگی دارد. پاداشهای ضعیف طراحیشده میتوانند منجر به رفتارهای ناخواسته یا بهینهسازی برای اهداف اشتباه شوند. - معاوضههای اندازه گروه (Group Size Tradeoffs):
انتخاب اندازه گروه بهینه شامل ایجاد تعادل بین تنوع راهحلها و هزینه محاسباتی است. نمونههای خیلی کم ممکن است تنوع کافی را فراهم نکنند، در حالی که تعداد زیاد نمونهها زمان آموزش و نیازمندیهای منابع را افزایش میدهد. - تنظیم واگرایی KL (KL Divergence Tuning):
یافتن تعادل مناسب برای جریمه واگرایی KL نیاز به تنظیم دقیق دارد – اگر خیلی زیاد باشد، مدل به طور مؤثر یاد نمیگیرد، و اگر خیلی کم باشد، ممکن است بیش از حد از قابلیتهای اولیه خود فاصله بگیرد.
نتیجهگیری
مقاله DeepSeek R1 نقطه عطف مهمی در توسعه مدلهای زبانی است. الگوریتم بهینهسازی خطمشی نسبی گروهی (GRPO) نشان داده است که یادگیری تقویتی خالص واقعاً میتواند قابلیتهای استدلال قوی را توسعه دهد و فرضیات قبلی در مورد ضرورت تنظیم دقیق نظارتشده را به چالش میکشد.
شاید مهمتر از همه، DeepSeek R1 نشان داده است که امکان ایجاد تعادل بین عملکرد بالا و ملاحظات عملی مانند مقرونبهصرفه بودن و دسترسیپذیری وجود دارد. تقطیر موفقیتآمیز قابلیتهای مدل در اندازههای مختلف، از پارامترهای 1.5B تا 70B، مسیری رو به جلو برای در دسترس قرار دادن گستردهتر قابلیتهای پیشرفته هوش مصنوعی را نشان میدهد.
در بخش بعدی، به بررسی پیادهسازیهای عملی این مفاهیم میپردازیم و تمرکز ما بر این خواهد بود که چگونه میتوان از GRPO و RFTrans در پروژههای توسعه مدل زبانی خود بهره گرفت.
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

دیدگاهتان را بنویسید