فصل 16: تولید متن با LLMها در Keras
این پست از فصل 16 کتاب DEEP LEARNING…
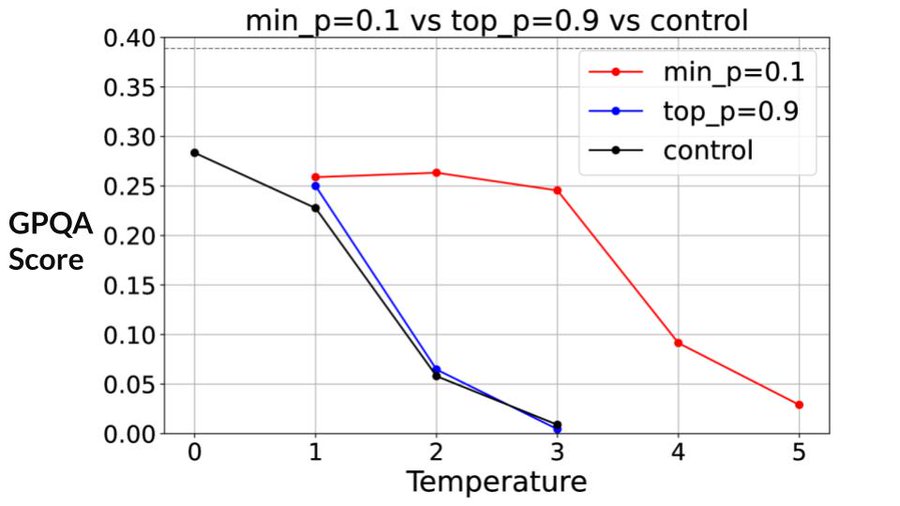
معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها
Min P، یک روش نمونهبرداری (sampling) جدید برای…

GGUF چیست؟ راهنمای کامل فرمت جدید مدلهای هوش مصنوعی و مقایسه با GGML
در دنیای مدلهای زبان بزرگ (LLM)، فرمت فایلها…

ایجاد مدلهای کوچک کارآمد با Llama 3.2 و هرس کردن (Pruning)
یکی از تکنیکهای اصلی در ایجاد مدلهای سبک…

انقلابی در فرآیند Fine-Tune مدلهای هوش مصنوعی با Unsloth
در دنیای همیشه در حال تحول هوش مصنوعی…
GSM8K چیست؟ دیتاست مسائل ریاضی برای آموزش LLMها
خلاصه دیتاست دیتاست GSM8K (مخفف Grade School Math…
چطور مدلها را سادهتر با انسان همراستا کنیم: از RLHF تا DPO
مدلهای زبان بزرگ (LLM) هر روز هوشمندتر میشوند،…
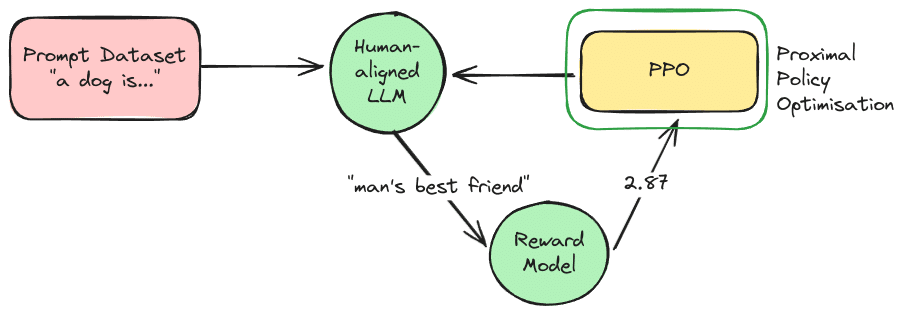
PPO به زبان ساده: چگونه هوش مصنوعی یاد میگیرد مثل ما فکر کند؟
دنیای هوش مصنوعی و بهخصوص مدلهای زبانی بزرگ…

۴۰ معیار برتر مدلهای زبان بزرگ (LLM) با پشتوانه تحقیقاتی و موارد استفاده آنها
با توسعه روزافزون هوش مصنوعی مولد (GenAI)، تمرکز…