چطور مدلها را سادهتر با انسان همراستا کنیم: از RLHF تا DPO
مدلهای زبان بزرگ (LLM) هر روز هوشمندتر میشوند،…
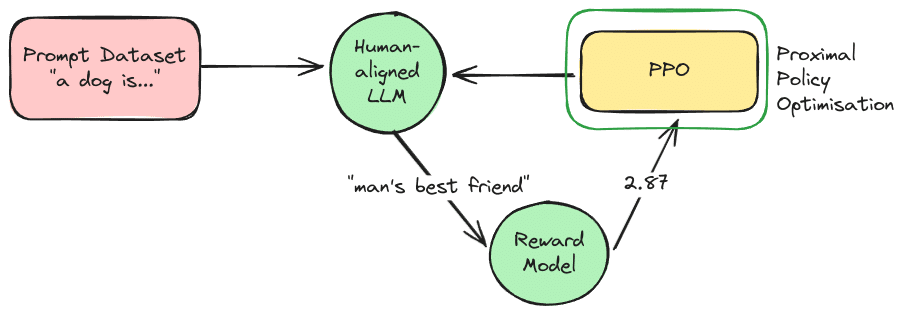
PPO به زبان ساده: چگونه هوش مصنوعی یاد میگیرد مثل ما فکر کند؟
دنیای هوش مصنوعی و بهخصوص مدلهای زبانی بزرگ…

مقدمهای بر Reinforcement Learning و نقش آن در LLMها
در این پست قراره به Reinforcement Learning (RL)…