ChatGPT چگونه ساخته شده است؟

ChatGPT چیست و چگونه ساخته شده؟!
ما همه درباره چتجیپیتی، برنامه هوش مصنوعی که توسط شرکت OpenAI توسعه داده شده است، شنیدهایم. این چت بات یک هوش مصنوعی قدرتمنداست که میتواند به شما پاسخ بهینه بر مبنای سوالتان را ارائه دهد.
در ویدیوی زیر روال آموزش chatGPT توضیح داده شده است:
این ویدیو بخشی از کورس آموزشی رایگان ChatGPT است. (بخش نحوه کارکرد و آموزش ChatGPT)
همچنین در این پست به نحوه کارکرد آن خواهیم پرداخت.
در مورد ChatGPT
چتجیپیتی یک چتبات توسعهیافته توسط OpenAI است که براساس مدل جیپیتی-۳.۵ (GPT-3.5) ساخته شده است. این مدل دارای توانایی قابل توجهی برای ارتباط در قالب گفتگوهای محاورهای است و پاسخهایی مثل انسان و با زبان انسانی ارائه میدهد. (اگر هنوز اکانت نساخته اید، آموزش ساخت اکانت chatgpt را ببینید)
هستهی اصلی این چت بات یک مدل زبانی بزرگ یا همان LLM (Large Language Model) است. مدلهای زبان بزرگ وظیفه پیشبینی کلمه بعدی در یک توالی از کلمات را دارد.
یک مثال از مدل زبانی، گوشی های هوشمند شما است که وقتی پیامک یا متنی مینوسید به صورت خودکار کلماتی را به شما پیشنهاد میدهد!
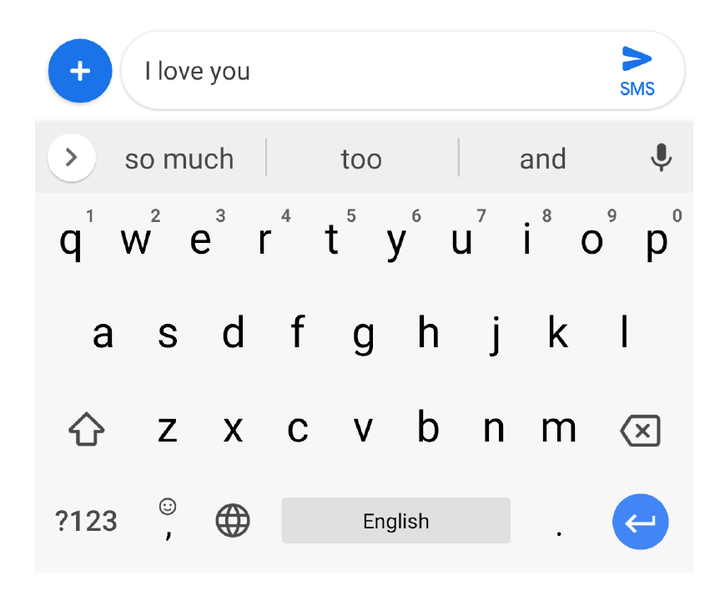
مثلا در تصویر بالا وقتی نوشته اید I Love you خود گوشی همراه شما واژه هایی مثل so much و too و and را پیشنهاد داده است. این در واقع یک مدل زبانی است که بر مبنای احتمالات وقوع یک کلمه بعد از تعدای کلمه پیشنهاد میدهد. حال chatgpt هم از یک مدل زبانی که روی تعداد خیلی زیادی متن آموزش دیده میتواند پیشنهاد بدهد.
البته مدل زبانی به تنهایی کافی نیست و فرقی بین پاسخ درست و غلط را نمیداند، مثلا اگر شما بگوییم جای خالی زیر را پر کن:
حکومت قاجار با به سلطنت رسیدن رضا شاه ….
دو احتمال هم اندازه بر اساس زبان شناسی وجود دارد، یک حکومت با سلطنت رسیدن یک فرد یا پایان میابد یا آغاز میگردد. مدل زبانی در حالت عادی فرقی بین این دو احتمال قائل نیست!
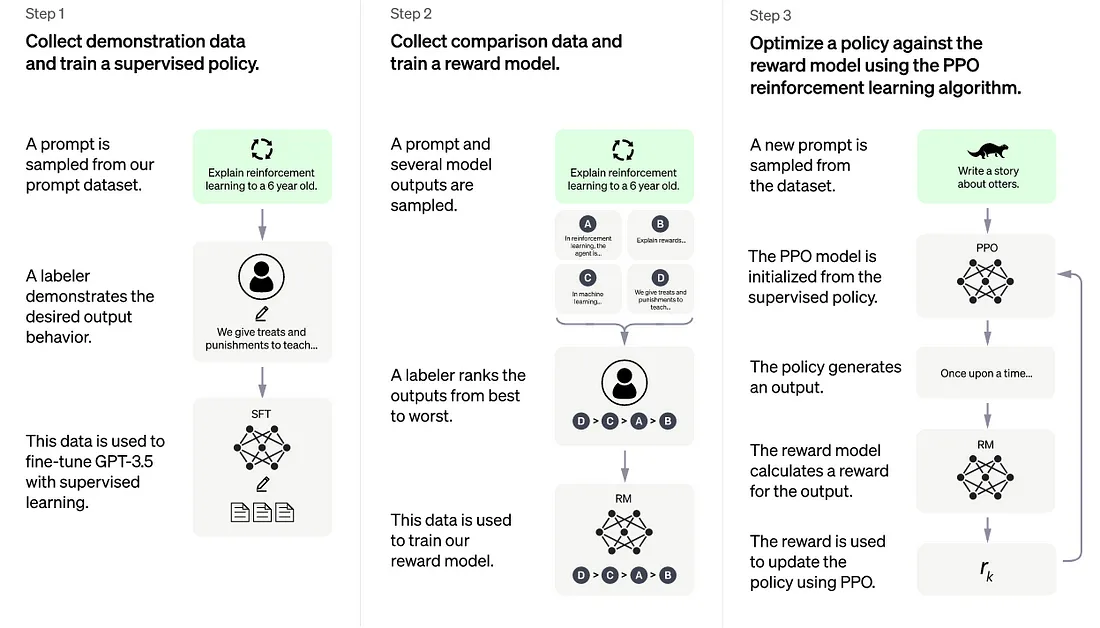
یادگیری تقویتی با بازخورد انسانی (RLHF) مرحلهی دیگری از آموزش است که از بازخورد انسانی برای کمک به چتجیپیتی در یادگیری توانایی پیروی از دستورالعملها و تولید پاسخهایی که برای انسانها مناسب هستند، استفاده میکند.
خالق ChatGPT
چتجیپیتی توسط شرکت هوش مصنوعی مستقر در سانفرانسیسکو به نام OpenAI ایجاد شد. شرکت OpenAI Inc. شرکت والد غیرانتفاعی شرکت OpenAI LP است.
یکی از دلایل معروفیت OpenAI بهخاطر انتشار DALL·E است، یک مدل یادگیری عمیق که میتواند تصاویری را از دستورالعملهای متنی کاربر یا همان promptها خلق میکند.
در حال حاضر مدیرعامل این شرکت Sam Altman است، که به عنوان موسس این شرکت (به همراه ایلان ماسک) بوده است.
مایکروسافت با 1 میلیارد دلار سهامدار و همکار OpenAI است و به همراه آن، پلتفرم هوش مصنوعی Azure را توسعه دادهاند.
آموزش مدل ChatGPT
GPT-3.5 با استفاده از حجم بزرگی از داده های کد و اطلاعات از اینترنت، از جمله منابعی مانند بحث های Reddit، آموزش دیده است. این کار به ChatGPT کمک میکند تا در گفتگوی خود به به سبک پاسخ دهی شبیه به انسان دست یابد.
ChatGPT نیز با بازخورد انسانی آموزش دید (روشی به نام Reinforcement Learning with Human Feedback) تا هوش مصنوعی یاد بگیرد که افراد چه چیزی را انتظار دارند وقتی سوالی می پرسند. آموزش LLM به این صورت، به عنوان یک نوآوری و از مرزهای زیادی فراتر می رود و تنها به آموزش LLM برای پیش بینی کلمه بعدی اکتفا نمی کند.
مقاله تحقیقاتی مارس 2022 با عنوان “مدلهای زبانی آموزشی با بازخورد انسانی” توضیح میدهد که چرا این رویکرد نوآورانه است:
This work is motivated by our goal to increase the positive impact of large language models by training them to do what a given group of people wants them to do.
By default, language models optimize for the goal of predicting the next word, which is just a proxy for what we want these models to do.
Our results suggest that our techniques promise to make language models more useful, true, and harmless.
Augmenting language models alone will not make them better at tracking user intent.
For example, large language models can generate output that is false, toxic, or simply not useful to the user.
In other words, these models are not aligned with their users.
ترجمه:
هدف ما در این پژوهش، افزایش اثر مثبت مدلهای زبانی بزرگ است که با آموزش آنها در راستای انجام کاری که یک گروه از افراد میخواهند، این هدف را دنبال میکنیم.
به طور پیشفرض، مدلهای زبانی برای پیشبینی کلمه بعدی بهینهسازی میشوند که فقط نمایندهای برای آن است که ما میخواهیم این مدلها انجام دهند.
نتایج نشان میدهد که تکنیکهای ما سبب کاربردیتر، راستینتر و بیضررتر شدن مدلهای زبانی میشوند.
فقط بهبود دادن مدلهای زبانی به تنهایی کافی نیست تا آنها را درک و پاسخ نیت کاربران به کار ببریم.
به عنوان مثال، مدلهای زبانی بزرگ میتوانند خروجیهایی تولید کنند که نادرست، سمی و یا برای کاربران مفید نباشد.
به عبارت دیگر، این مدلها با کاربرانشان هماهنگ نیستند.
مهندسانی که ChatGPT را ساخته اند برای ارزیابی خروجی دو سیستم GPT-3 و InstructGPT جدید (یه جورایی همون ChatGPT یا برادرش) افرادی را برای برچسب یا لیبل زدن(labelers) استخدام کردند.
براساس ارزیابی، پژوهشگران به نتیجههای زیر رسیدند:
Labels strongly prefer InstructGPT outputs over GPT-3 outputs.
InstructGPT models show an improvement in veracity over GPT-3.
InstructGPT shows small improvements in toxicity over GPT-3, but not bias.
ترجمه:
طبق برچسبها (یا لیبل ها) به شدت خروجیهای InstructGPT در مقابل خروجیهای GPT-3 بهتر است.مدلهای مختلف InstructGPT دقت بالاتری نسبت به GPT-3 دارند.
InstructGPT بهبودهای کوچکی در سمیت (سمی بودن پاسخ) نسبت به GPT-3 نشان میدهد، امّا تبعیض را نشان نمیدهد.
مقاله تحقیقاتی نتیجه مثبتی را برای InstructGPT اعلام کرده است. با این حال، همچنین یادداشت شده است که هنوز فضایی برای بهبود وجود دارد.
Overall, our results suggest that fine-tuning large language models using human preferences significantly improves their behavior across a wide range of tasks, although much work remains to be done to improve their security and reliability.
ترجمه:
در کل، نتایج ما نشان میدهد که بهینهسازی دقیق مدلهای زبان بزرگ با استفاده از ترجیحات انسانی عملکرد آنها را در گستره وسیعی از وظایف بهبود میبخشد، با این حال هنوز بسیاری از کارها برای بهبود امنیت و قابلیت اطمینان آنها باقی مانده است.
چیزی که ChatGPT را از یک چتبات ساده متمایز میکند، آموزش آن به منظور درک نیت انسانی در یک پرسش و ارائه پاسخهای مفید، صادقانه و بیضرر است.
با توجه به این آموزش، ChatGPT ممکن است برخی از سوالات را چالش برانگیز دانسته و بخشهایی از سوال را که مفهومی ندارند حذف کند.
مقاله دیگری مرتبط با ChatGPT نشان میدهد که چگونه آنها یک هوش مصنوعی را به منظور پیشبینی ترجیحات مردم آموزش دادهاند.
پژوهشگران متوجه شدند که معیارهای استفاده شده برای ارزیابی خروجی هوش مصنوعی در پردازش زبان طبیعی، منجر به ساخت ماشینآلاتی شد که برای معیارها امتیاز بالایی کسب میکردند، اما در نظر انسانها کمبودهایی داشتند.
پژوهشگران موضوع را به شرح زیر توضیح دادند.
Many machine learning applications optimize for simple metrics that are only rough proxies for what the designer intended. This can lead to issues like YouTube referrals promoting clickbait.
ترجمه:
بسیاری از برنامههای یادگیری ماشین، به دنبال بهینهسازی معیارهای ساده هستند که تنها نمایندههای خام آنچه که طراح برنامه قصد دارد، هستند. این موضوع میتواند منجر به مسائلی مانند ترویج کلیکبیت در ارجاعات یوتیوب شود.
(اصطلاح کلیکبیت به محتوای عنوانی یا تصویری گفته میشود که برای جلب توجه و کلیک کاربران طراحی شده است، اما معمولاً با محتوای نامرتبط یا چیزی که قول داده شده در عنوان یا تصویر حاضر نیست، همراه است. به طور کلی، کلیکبیت معمولاً باعث افزایش ترافیک وبسایت شده ولی به کاربران نارضایتی و بیاعتمادی را در بر میگیرد.)
راه حلی که آنها پیشنهاد دادند، ایجاد یک هوش مصنوعی بود که بر مبنای ترجیح مردم پاسخ دهد.
برای این کار، آنها هوش مصنوعی را با استفاده از مجموعه دادههایی از مقایسه بین پاسخهای مختلف انسان، آموزش دادند، تا ماشین بهترین پیشبینی را در خصوص تشخیص پاسخهای قابل قبول افراد داشته باشد.
مقاله مربوط به این تحقیق، علاوه بر این، این نکته را نیز ذکر میکند که آموزش با خلاصهسازی پستهای Reddit انجام شده و همچنین بر روی خلاصه خبرها تست شده است.
این مقاله پژوهشی در فوریه 2022 با عنوان “یادگیری خلاصهسازی از بازخورد انسان” منتشر شده است.
محققان در این مقاله نوشتند:
In this work, we show that it is possible to significantly improve the quality of summaries by training a model to optimize for human preferences.
We collect a large, high-quality dataset of human-to-summary comparisons, train a model to predict the human-preferred summary, and use that model as a reward function to fine-tune the summarization policy using reinforcement learning.
ترجمه:
در این کار، نشان میدهیم که با آموزش یک مدل برای بهینه سازی بر اساس ترجیحات انسانی، میتوان کیفیت خلاصهها را به طور قابل توجهی بهبود داد.
ما یک مجموعه داده بزرگ و با کیفیت بالا از مقایسههای انسانی به خلاصه جمعآوری کرده، یک مدل برای پیشبینی خلاصه مد نظر انسانی آموزش داده و از آن مدل به عنوان تابع پاداش برای تنظیم دقیقتر سیاست خلاصهنویسی با استفاده از یادگیری تقویتی استفاده میکنیم.
اگر به این مطلب علاقه داشتید، برنامه ضبط شده شبکه 4 سیما هم ببینید.
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 1

راهنمای قدم به قدم کرایه کارت گرافیک (GPU) با Vast.ai برای پروژههای هوش مصنوعی

دیدگاهتان را بنویسید