ماتریس درهمریختگی (confusion matrix) چیست؟

در وظایف طبقهبندی در یادگیری ماشین، یک ماتریس درهمریختگی (confusion matrix) به عنوان جدولی برای خلاصه کردن عملکرد مدل عمل میکند که شامل تعداد پیشبینیهای درست مثبت (true positive)، درست منفی (true negative)، مثبت کاذب (false positive) و منفی کاذب (false negative) است. برای طبقهبندی چندکلاسه، این ماتریس به شکل مربعی با ابعادی برابر با تعداد کلاسها میشود که هر سلول نمایانگر تعداد نمونهها برای ترکیب برچسبها و کلاسهای پیشبینیشده است. ردیفها نشاندهنده کلاسهای واقعی (Ground Truth) هستند، در حالی که ستونها نشاندهنده کلاسهای پیشبینیشده میباشند. تحلیل این ماتریس دیدگاهی نسبت به نقاط قوت و ضعف مدل در تمایز بین کلاسهای خاص ارائه میدهد.
مفاهیم مرتبط:
- True Negative (منفی درست): زمانی که مدل یک نمونه را به درستی به عنوان یک کلاس منفی پیشبینی میکند. در مثال ایمیلهای اسپم، یک “منفی درست” زمانی است که مدل به درستی یک ایمیل غیر اسپم را به عنوان غیر اسپم تشخیص میدهد.
- False Positive (مثبت کاذب): زمانی که مدل به اشتباه یک نمونه منفی را به عنوان مثبت پیشبینی میکند. در مثال ایمیلهای اسپم، یک “مثبت کاذب” زمانی است که مدل به اشتباه یک ایمیل غیر اسپم را به عنوان اسپم تشخیص میدهد.
- False Negative (منفی کاذب): زمانی که مدل به اشتباه یک نمونه مثبت را به عنوان منفی پیشبینی میکند. در مثال ایمیلهای اسپم، یک “منفی کاذب” زمانی است که مدل به اشتباه یک ایمیل اسپم را به عنوان غیر اسپم تشخیص میدهد.
این مفاهیم برای تحلیل عملکرد مدلهای طبقهبندی بسیار مهم هستند و به فهم بهتر نقاط قوت و ضعف مدل کمک میکنند. مثلاً تعداد بالای مثبت کاذب نشان میدهد که مدل نمونههای منفی را به اشتباه به عنوان مثبت طبقهبندی میکند که ممکن است نیاز به تنظیم حساسیت مدل داشته باشد. به همین ترتیب، تعداد بالای منفی کاذب نشان میدهد که مدل در شناسایی نمونههای مثبت دچار مشکل است و نیاز به بهبود دارد.
مثال ماتریس درهمریختگی
مثالی از استفاده از ماتریس درهمریختگی برای ارزیابی کیفیت خروجی یک دستهبند روی مجموعه دادههای Iris. عناصر روی قطر ماتریس نمایانگر تعداد نقاطی هستند که برچسب پیشبینیشده با برچسب واقعی برابر است، در حالی که عناصر خارج از قطر نقاطی هستند که به اشتباه توسط دستهبند برچسبگذاری شدهاند. هرچه مقادیر روی قطر ماتریس درهمریختگی بیشتر باشد، بهتر است، زیرا نشاندهنده تعداد زیاد پیشبینیهای درست است.
نمودارها ماتریس درهمریختگی را با و بدون نرمالسازی بر اساس اندازه حمایت کلاسی (تعداد عناصر در هر کلاس) نشان میدهند. این نوع نرمالسازی میتواند در صورت عدم تعادل کلاسها جالب باشد تا تفسیر بصری بهتری از کلاسی که به اشتباه دستهبندی شده، ارائه دهد.
در اینجا نتایج به اندازهای که میتوانستند خوب نیستند زیرا انتخاب ما برای پارامتر بهترین نبوده است. در کاربردهای واقعی، این پارامتر معمولاً با استفاده از تنظیم پارامترهای فرامدل (Tuning the hyper-parameters) انتخاب میشود.
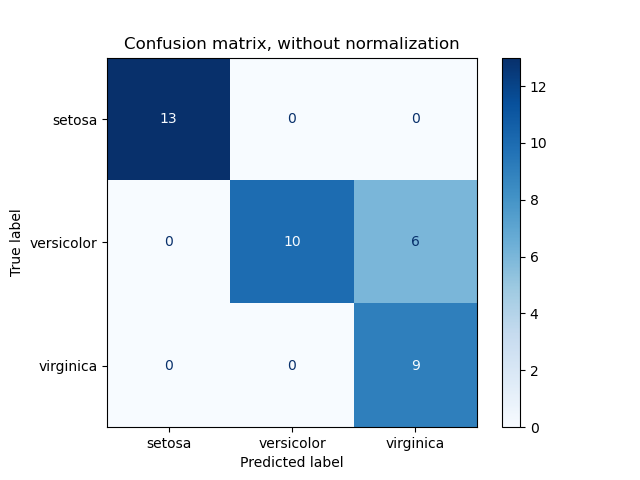
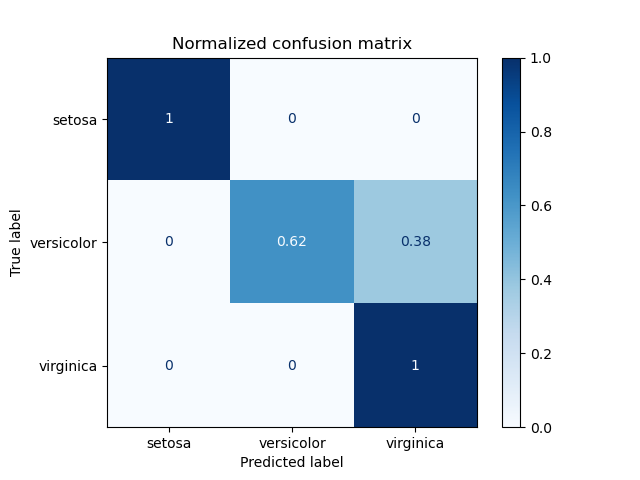
کد نمونه:
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, svm
from sklearn.metrics import ConfusionMatrixDisplay
from sklearn.model_selection import train_test_split
# import some data to play with
iris = datasets.load_iris()
X = iris.data
y = iris.target
class_names = iris.target_names
# Split the data into a training set and a test set
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# Run classifier, using a model that is too regularized (C too low) to see
# the impact on the results
classifier = svm.SVC(kernel="linear", C=0.01).fit(X_train, y_train)
np.set_printoptions(precision=2)
# Plot non-normalized confusion matrix
titles_options = [
("Confusion matrix, without normalization", None),
("Normalized confusion matrix", "true"),
]
for title, normalize in titles_options:
disp = ConfusionMatrixDisplay.from_estimator(
classifier,
X_test,
y_test,
display_labels=class_names,
cmap=plt.cm.Blues,
normalize=normalize,
)
disp.ax_.set_title(title)
print(title)
print(disp.confusion_matrix)
plt.show()
منبع:https://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
مطالب زیر را حتما مطالعه کنید

کاهش مصرف حافظه در LLM با bitsandbytes: آموزش و استنتاج سریع با کوانتیزاسیون 4 و 8 بیتی
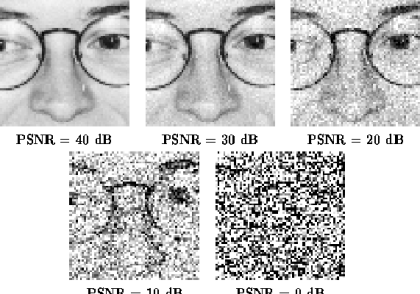
PSNR چیست؟

دیدگاهتان را بنویسید