مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 1

مدلهای انتشار (Diffusion Models) نسبتاً اخیراً به خانوادهای از الگوریتمها با نام مدلهای مولد (Generative Models) افزوده شدهاند. هدف مدلسازی مولد، یادگیری تولید داده (مانند تصویر یا صدا) بر اساس مجموعهای از نمونههای آموزشی است. یک مدل مولد خوب باید مجموعهای متنوع از خروجیها ایجاد کند که به دادههای آموزشی شباهت داشته باشند، بدون آنکه کپی دقیق آنها باشند.
اما مدلهای انتشار چگونه به این هدف دست پیدا میکنند؟
برای توضیح بهتر، بیایید روی تولید تصویر تمرکز کنیم.

راز موفقیت مدلهای انتشار (Diffusion Models) در ماهیت تکراری فرآیند انتشار نهفته است. تولید تصویر با نویز تصادفی آغاز میشود، اما این نویز طی چندین مرحله بهتدریج پالایش میگردد تا در نهایت تصویر خروجی شکل بگیرد. در هر مرحله، مدل تخمین میزند که چگونه میتوان از ورودی فعلی به نسخهای کاملاً بدون نویز رسید. با این حال، از آنجا که در هر گام تنها تغییر کوچکی اعمال میشود، خطاهای احتمالی در مراحل اولیه (جایی که پیشبینی خروجی نهایی بسیار دشوار است) میتوانند در بهروزرسانیهای بعدی اصلاح شوند.
آموزش مدل نسبتاً ساده است، بهویژه در مقایسه با برخی دیگر از انواع مدلهای مولد (Generative Models). مراحل به صورت تکراری انجام میشوند:
-
بارگذاری تصاویر آموزشی: تعدادی تصویر از دادههای آموزشی را وارد میکنیم.
-
افزودن نویز: نویز با مقادیر مختلف به تصاویر اضافه میکنیم. به خاطر داشته باشید که هدف ما این است که مدل بتواند هم تصاویر بسیار پرنویز و هم تصاویر نزدیک به کامل را به خوبی «اصلاح» (Denoise) کند.
-
ورود تصاویر نویزی به مدل: نسخههای نویزی تصاویر را به مدل میدهیم.
-
ارزیابی عملکرد مدل: بررسی میکنیم مدل در حذف نویز از این تصاویر چقدر موفق است.
-
بهروزرسانی وزنهای مدل: اطلاعات بهدست آمده برای بهروزرسانی وزنهای مدل استفاده میشود.
برای تولید تصاویر جدید با مدل آموزشدیده، با یک ورودی کاملاً تصادفی شروع میکنیم و آن را بهطور مکرر از مدل عبور میدهیم، هر بار با مقدار کمی بر اساس پیشبینی مدل بهروزرسانی میکنیم. همانطور که خواهیم دید، چندین روش نمونهگیری (Sampling Methods) وجود دارد که تلاش میکنند این فرآیند را بهینه کنند تا تصاویر خوب با کمترین تعداد مرحله تولید شوند.
پیاده سازی در diffusersهاگینگ فیس
در ادامه یک Pipeline قدرتمند مدل انتشار سفارشی شده را با کتابخانه diffusers هاگینگ فیس خواهیم دید.
-
ایجاد mini pipeline خودتان با انجام موارد زیر:
-
مرور مجدد core ideas پشت diffusion models
-
بارگذاری دادهها از Hub برای آموزش
-
بررسی نحوه افزودن نویز به دادهها با استفاده از scheduler
-
ایجاد و آموزش مدل UNet
-
ترکیب اجزا در یک working pipeline
-
-
ویرایش و اجرای یک اسکریپت برای initializing longer training runs که شامل موارد زیر است:
-
آموزش multi-GPU با استفاده از Accelerate
-
experiment logging برای مانیتور کردن آمارهای مهم
-
بارگذاری مدل نهایی در Hugging Face Hub
-
ابتدا با دستور زیر کتابخانه های مورد تیاز بیاد نصب گردد:
%pip install -qq -U pyarrow==19.0.0 %pip install -qq -U diffusers datasets transformers accelerate ftfy
سپس با ساخت یک اکانت هاگینگ فیس و سپس مراجعه به آدرس https://huggingface.co/settings/tokens باید یک توکن با قابلیت write بسازید.
 شما میتوانید با استفاده از این توکن از طریق خط فرمان با دستور
شما میتوانید با استفاده از این توکن از طریق خط فرمان با دستور huggingface-cli login و یا با اجرای سلول زیر لاگین کنید:
from huggingface_hub import notebook_login notebook_login()
حال Git-LFS را نصب کنید تا model checkpoint را بتونید دانلود کنید.
%%capture !sudo apt -qq install git-lfs !git config --global credential.helper store
در نهایت، بیایید کتابخانههایی که استفاده میکنیم را import کرده و چند تابع کمکی (convenience function) تعریف کنیم که بعداً در نوتبوک به آنها نیاز خواهیم داشت:
import numpy as np
import torch
import torch.nn.functional as F
from matplotlib import pyplot as plt
from PIL import Image
def show_images(x):
"""Given a batch of images x, make a grid and convert to PIL"""
x = x * 0.5 + 0.5 # Map from (-1, 1) back to (0, 1)
grid = torchvision.utils.make_grid(x)
grid_im = grid.detach().cpu().permute(1, 2, 0).clip(0, 1) * 255
grid_im = Image.fromarray(np.array(grid_im).astype(np.uint8))
return grid_im
def make_grid(images, size=64):
"""Given a list of PIL images, stack them together into a line for easy viewing"""
output_im = Image.new("RGB", (size * len(images), size))
for i, im in enumerate(images):
output_im.paste(im.resize((size, size)), (i * size, 0))
return output_im
# Mac users may need device = 'mps' (untested)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
در اینجا یک مثال آورده شده است که از مدلی آموزشدیده روی ۵ عکس از یک اسباببازی محبوب کودکان به نام “Mr Potato Head” استفاده میکند.
ابتدا pipeline را بارگذاری میکنیم. این کار وزنهای مدل و موارد دیگر را از Hub دانلود خواهد کرد. از آنجا که این دانلود چند گیگابایت داده برای یک دمو تکخطی است، میتوانید این سلول را نادیده بگیرید و صرفاً از خروجی نمونه لذت ببرید!
from diffusers import StableDiffusionPipeline # Check out https://huggingface.co/sd-dreambooth-library for loads of models from the community model_id = "sd-dreambooth-library/mr-potato-head" # Load the pipeline pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16).to(device)
حالا که pipeline را ایجاد کردید میتونید مثل زیر با دستورات مد نظر تصویر درست کنید:
prompt = "an abstract oil painting of sks mr potato head by picasso" image = pipe(prompt, num_inference_steps=50, guidance_scale=7.5).images[0] image

تمرین: خودتان با prompt های مختلف امتحان کنید. توکن sks در اینجا نمایانگر یک شناسه منحصر به فرد برای مفهوم جدید است – اگر آن را حذف کنید، چه اتفاقی میافتد؟
همچنین میتوانید با تغییر تعداد مراحل نمونهگیری (sampling steps) آزمایش کنید (تا چه حد میتوان آن را کاهش داد؟)
و guidance_scale را تغییر دهید، که مشخص میکند مدل تا چه حد تلاش میکند با prompt مطابقت داشته باشد.
در این pipeline جادویی چیزهای زیادی در حال رخ دادن است! تا پایان این پست، شما خواهید دانست همه اینها چگونه کار میکند. فعلاً بیایید نگاهی بیندازیم به اینکه چگونه میتوان یک diffusion model را از ابتدا (from scratch) آموزش داد.
MVP (Minimum Viable Pipeline)
Core API کتابخانه Diffusers به سه بخش اصلی تقسیم میشود:
-
Pipelines: کلاسهای سطح بالا که برای تولید سریع نمونهها از مدلهای انتشار محبوب آموزشدیده به روشی کاربرپسند طراحی شدهاند.
-
Models: معماریهای محبوب برای آموزش مدلهای انتشار جدید، مانند UNet.
-
Schedulers: تکنیکهای مختلف برای تولید تصاویر از نویز در هنگام استنتاج (inference) و همچنین برای ایجاد تصاویر نویزی برای آموزش.
Pipelines برای کاربران نهایی عالی هستند، اما اگر شما میخواهید بدانید واقعا در این فرایند چه میگذرد در ادامه این نوتبوک، ما pipeline خودمان را میسازیم که قادر به تولید تصاویر کوچک پروانه باشد. در اینجا نتیجه نهایی را در عمل مشاهده میکنید:
from diffusers import DDPMPipeline
# Load the butterfly pipeline
butterfly_pipeline = DDPMPipeline.from_pretrained("johnowhitaker/ddpm-butterflies-32px").to(device)
# Create 8 images
images = butterfly_pipeline(batch_size=8).images
# View the result
make_grid(images)

شاید چشمگیر نباشد، اما در اینجا ما از صفر آموزش میدهیم و تنها از حدود ۰.۰۰۰۱٪ دادهای که برای آموزش Stable Diffusion استفاده شده بهره میبریم.
صحبت از آموزش شد، بیایید به یاد بیاوریم که در مقدمه این واحد گفته شد آموزش یک diffusion model تقریباً به این شکل است:
-
بارگذاری تعدادی تصویر از دادههای آموزشی
-
افزودن نویز با مقادیر مختلف
-
وارد کردن نسخههای نویزی تصاویر به مدل
-
ارزیابی عملکرد مدل در denoising این تصاویر
-
استفاده از این اطلاعات برای بهروزرسانی وزنهای مدل و تکرار مراحل
در بخشهای بعدی، این مراحل را گام به گام بررسی میکنیم تا در نهایت یک training loop کامل داشته باشیم. سپس به نحوه نمونهگیری (sampling) از مدل آموزشدیده و بستهبندی همه چیز در یک pipeline برای به اشتراکگذاری آسان خواهیم پرداخت. حالا بیایید با دادهها شروع کنیم…
گام ۲: دانلود مجموعه داده برای آموزش
برای این مثال، از یک مجموعه تصاویر از Hugging Face Hub استفاده میکنیم. به طور مشخص، این مجموعه شامل ۱۰۰۰ تصویر پروانه است. این مجموعه داده بسیار کوچک است، بنابراین خطوطی برای گزینههای بزرگتر هم به صورت کامنت در کد قرار داده شدهاند. اگر ترجیح میدهید از مجموعه تصاویر خودتان استفاده کنید، میتوانید از کد نمونه کامنتشده برای بارگذاری تصاویر از یک پوشه نیز بهره ببرید.
import torchvision
from datasets import load_dataset
from torchvision import transforms
dataset = load_dataset("huggan/smithsonian_butterflies_subset", split="train")
# Or load images from a local folder
# dataset = load_dataset("imagefolder", data_dir="path/to/folder")
# We'll train on 32-pixel square images, but you can try larger sizes too
image_size = 32
# You can lower your batch size if you're running out of GPU memory
batch_size = 64
# Define data augmentations
preprocess = transforms.Compose(
[
transforms.Resize((image_size, image_size)), # Resize
transforms.RandomHorizontalFlip(), # Randomly flip (data augmentation)
transforms.ToTensor(), # Convert to tensor (0, 1)
transforms.Normalize([0.5], [0.5]), # Map to (-1, 1)
]
)
def transform(examples):
images = [preprocess(image.convert("RGB")) for image in examples["image"]]
return {"images": images}
dataset.set_transform(transform)
# Create a dataloader from the dataset to serve up the transformed images in batches
train_dataloader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True)
حالا میتونیم نگاهی به یه مینی بچ از این داده بندازیم
xb = next(iter(train_dataloader))["images"].to(device)[:8]
print("X shape:", xb.shape)
show_images(xb).resize((8 * 64, 64), resample=Image.NEAREST)
X shape: torch.Size([8, 3, 32, 32])
ما برای این نوتبوک همچنان از مجموعه داده کوچک با تصاویر ۳۲ پیکسلی استفاده میکنیم تا زمان آموزش قابل مدیریت باقی بماند.
گام ۳: تعریف Scheduler
طرح آموزش ما به این صورت است که تصاویر ورودی را گرفته، نویز به آنها اضافه کنیم و سپس نسخههای نویزی را به مدل بدهیم. در هنگام inference، از پیشبینیهای مدل برای حذف تدریجی نویز استفاده میکنیم. در کتابخانه diffusers، هر دو فرآیند توسط scheduler مدیریت میشوند.
Noise schedule مشخص میکند که در مراحل زمانی مختلف (timesteps) چه مقدار نویز اضافه شود.
در اینجا مثالی از نحوه ایجاد یک scheduler با تنظیمات پیشفرض برای آموزش و نمونهگیری DDPM آورده شده است (بر اساس مقاله “Denoising Diffusion Probabilistic Models”):
from diffusers import DDPMScheduler noise_scheduler = DDPMScheduler(num_train_timesteps=1000)
مقاله DDPM یک فرآیند corruption را توصیف میکند که در هر «timestep» مقدار کمی نویز اضافه میکند. با داشتن  در یک timestep خاص، میتوانیم نسخه بعدی (کمی نویزیتر)
در یک timestep خاص، میتوانیم نسخه بعدی (کمی نویزیتر)  را با فرمول زیر به دست آوریم:
را با فرمول زیر به دست آوریم:
![\[ q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) = \mathcal{N}(\mathbf{x}_t; \sqrt{1 - \beta_t} \mathbf{x}_{t-1}, \beta_t \mathbf{I}) \quad q(\mathbf{x}_{1:T} \vert \mathbf{x}_0) = \prod_{t=1}^{T} q(\mathbf{x}_t \vert \mathbf{x}_{t-1}) \]](https://class.vision/wp-content/ql-cache/quicklatex.com-8152634c3fcbdf96c0817ea8d2b62a6f_l3.png "Rendered by QuickLaTeX.com")
یعنی ما را گرفته، آن را در  ضرب میکنیم و نویزی به اندازه
ضرب میکنیم و نویزی به اندازه  اضافه میکنیم. این
اضافه میکنیم. این  برای هر t طبق یک schedule تعریف میشود و مشخص میکند در هر timestep چه مقدار نویز اضافه شود. حالا ما لزوماً نمیخواهیم این عملیات را ۵۰۰ بار انجام دهیم تا
برای هر t طبق یک schedule تعریف میشود و مشخص میکند در هر timestep چه مقدار نویز اضافه شود. حالا ما لزوماً نمیخواهیم این عملیات را ۵۰۰ بار انجام دهیم تا  را به دست آوریم، بنابراین فرمول دیگری داریم تا بتوانیم را برای هر t با داشتن
را به دست آوریم، بنابراین فرمول دیگری داریم تا بتوانیم را برای هر t با داشتن  محاسبه کنیم:
محاسبه کنیم:
![\[ q(\mathbf{x}_t \vert \mathbf{x}_0) = \mathcal{N}(\mathbf{x}_t; \sqrt{\bar{\alpha}_t} \mathbf{x}_0, (1 - \bar{\alpha}_t) \mathbf{I}) \]](https://class.vision/wp-content/ql-cache/quicklatex.com-c3897664120d9d992366cce6af11b2b6_l3.png "Rendered by QuickLaTeX.com")
![\[ \text{که در آن } \bar{\alpha}_t = \prod_{i=1}^{t} \alpha_i \text{ و } \alpha_i = 1 - \beta_i \]](https://class.vision/wp-content/ql-cache/quicklatex.com-4e806a65234cc7cc4878860e7693a13d_l3.png "Rendered by QuickLaTeX.com")
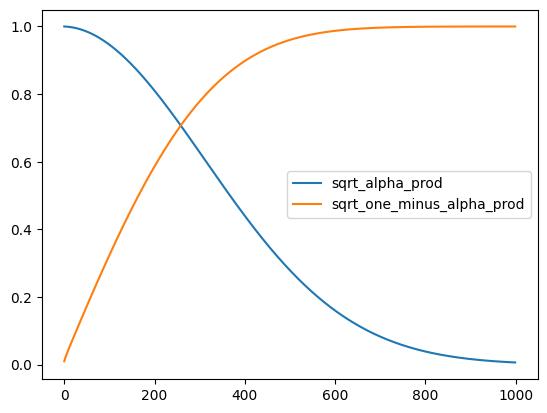
نمادهای ریاضی همیشه ترسناک به نظر میرسند! خوشبختانه scheduler همه این کارها را برای ما انجام میدهد. ما میتوانیم  (با برچسب sqrt_alpha_prod) و
(با برچسب sqrt_alpha_prod) و  (با برچسب sqrt_one_minus_alpha_prod) را رسم کنیم تا ببینیم چگونه ورودی (x) و نویز در طول timesteps مختلف مقیاسدهی و ترکیب میشوند.
(با برچسب sqrt_one_minus_alpha_prod) را رسم کنیم تا ببینیم چگونه ورودی (x) و نویز در طول timesteps مختلف مقیاسدهی و ترکیب میشوند.
plt.plot(noise_scheduler.alphas_cumprod.cpu() ** 0.5, label=r"") plt.plot((1 - noise_scheduler.alphas_cumprod.cpu()) ** 0.5, label=r"
") plt.legend(fontsize="x-large")
تمرین: شما میتوانید ببینید که این نمودار چگونه با تنظیمات مختلف beta_start، beta_end و beta_schedule تغییر میکند، با جایگزین کردن یکی از گزینههای comment شده موجود در اینجا:
# One with too little noise added: # noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_start=0.001, beta_end=0.004) # The 'cosine' schedule, which may be better for small image sizes: # noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_schedule='squaredcos_cap_v2')
مستقل از اینکه کدام scheduler را انتخاب کرده باشید، اکنون میتوانیم با استفاده از تابع noise_scheduler.add_noise به این شکل از آن برای افزودن نویز با مقادیر مختلف استفاده کنیم:
timesteps = torch.linspace(0, 999, 8).long().to(device)
noise = torch.randn_like(xb)
noisy_xb = noise_scheduler.add_noise(xb, noise, timesteps)
print("Noisy X shape", noisy_xb.shape)
show_images(noisy_xb).resize((8 * 64, 64), resample=Image.NEAREST)
Noisy X shape torch.Size([8, 3, 32, 32])
دوباره، اثر استفاده از noise schedules و پارامترهای مختلف را اینجا بررسی کنید. این ویدئو توضیح بسیار خوبی از برخی ریاضیات بالا ارائه میدهد و مقدمهای عالی برای برخی از این مفاهیم است.
گام ۴: تعریف مدل
حالا به بخش اصلی میرسیم: خود مدل.
بیشتر مدلهای انتشار از معماریهایی استفاده میکنند که نوعی U-Net هستند و همین معماری را ما نیز در اینجا به کار خواهیم برد.
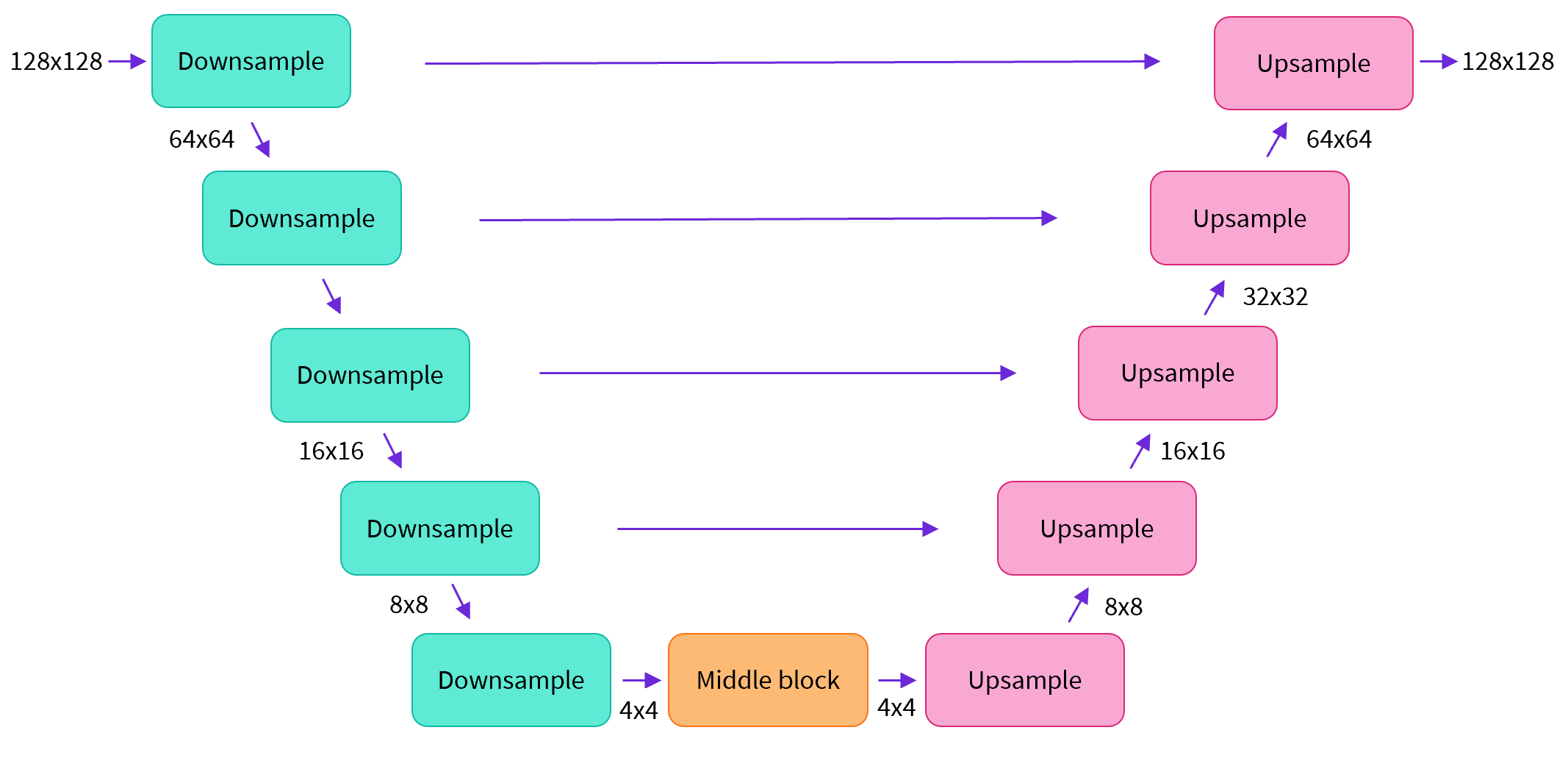
به طور خلاصه:
-
تصویر ورودی از چند بلوک ResNet عبور میکند که هر کدام اندازه تصویر را نصف میکنند.
-
سپس همان تعداد بلوک برای upsample کردن دوباره تصویر استفاده میشود.
-
skip connections ویژگیهای مسیر پایینآوری (downsample) را به لایههای متناظر در مسیر بالا آوردن (upsample) متصل میکنند.
ویژگی کلیدی این مدل این است که تصاویر هماندازه با ورودی پیشبینی میکند، که دقیقاً همان چیزی است که اینجا نیاز داریم.
اگر دوست دارید بیشتر در مورد Unet بدانید فصل 6 از دورهی جامع یادگیری عمیق با موضوع “Model Subclassing، خودرمزنگارها و GAN ها” را در کلاس ویژن یا در مکتبخونه ببینید.
دوره جامع یادگیری عمیق: تسلط بر هوش مصنوعی با 40 ساعت آموزش (Tensorflow/keras)
کتابخانه Diffusers یک کلاس کاربردی به نام UNet2DModel در اختیار ما قرار میدهد که معماری موردنظر را در PyTorch ایجاد میکند.
بیایید یک U-Net برای اندازه تصویر دلخواه خود بسازیم. توجه داشته باشید که:
-
down_block_types به بلوکهای downsampling (سبز در نمودار بالا) اشاره دارند،
-
و up_block_types به بلوکهای upsampling (قرمز در نمودار) مربوط میشوند.
from diffusers import UNet2DModel
# Create a model
model = UNet2DModel(
sample_size=image_size, # the target image resolution
in_channels=3, # the number of input channels, 3 for RGB images
out_channels=3, # the number of output channels
layers_per_block=2, # how many ResNet layers to use per UNet block
block_out_channels=(64, 128, 128, 256), # More channels -> more parameters
down_block_types=(
"DownBlock2D", # a regular ResNet downsampling block
"DownBlock2D",
"AttnDownBlock2D", # a ResNet downsampling block with spatial self-attention
"AttnDownBlock2D",
),
up_block_types=(
"AttnUpBlock2D",
"AttnUpBlock2D", # a ResNet upsampling block with spatial self-attention
"UpBlock2D",
"UpBlock2D", # a regular ResNet upsampling block
),
)
model.to(device)
وقتی با ورودیهایی با رزولوشن بالاتر کار میکنید، ممکن است بخواهید از تعداد بیشتری بلوک down و up استفاده کنید و لایههای attention را فقط در پایینترین رزولوشن (لایههای پایین) نگه دارید تا مصرف حافظه کاهش یابد. بعداً درباره نحوه آزمایش برای پیدا کردن بهترین تنظیمات برای کاربرد خود صحبت خواهیم کرد.
میتوانیم بررسی کنیم که با وارد کردن یک batch از دادهها و چند timestep تصادفی، خروجی با همان شکل ورودی تولید میشود:
with torch.no_grad():
model_prediction = model(noisy_xb, timesteps).sample
model_prediction.shape
در بخش بعدی، نحوه آموزش این مدل را خواهیم دید.
گام ۵: ایجاد یک Training Loop
وقت آموزش است! در ادامه یک loop بهینهسازی معمول در PyTorch آمده است، که در آن دادهها batch به batch پردازش میشوند و پارامترهای مدل در هر مرحله با استفاده از یک optimizer بهروزرسانی میشوند — در این مثال از AdamW با learning rate = 0.0004 استفاده شده است.
برای هر batch داده، ما:
-
چند timestep تصادفی نمونهگیری میکنیم
-
دادهها را مطابق آن نویزی میکنیم
-
دادههای نویزی را به مدل میدهیم
-
پیشبینیهای مدل را با هدف واقعی (در اینجا همان نویز) مقایسه میکنیم و mean squared error را به عنوان تابع loss استفاده میکنیم
-
پارامترهای مدل را با
loss.backward()وoptimizer.step()بهروزرسانی میکنیم
در این فرآیند، مقادیر loss را نیز ثبت میکنیم تا بعداً بتوانیم آنها را رسم کنیم.
توجه: این کد تقریباً ۱۰ دقیقه زمان اجرا میبرد — اگر عجله دارید، میتوانید این دو سلول را رد کرده و از مدل آموزشدیده استفاده کنید. بهطور جایگزین، میتوانید با کاهش تعداد کانالها در هر لایه از طریق تعریف مدل بالا، سرعت اجرای آموزش را افزایش دهید.
مثال رسمی آموزش در diffusers، مدل بزرگتری را روی همین مجموعه داده با رزولوشن بالاتر آموزش میدهد و مرجع خوبی برای دیدن یک training loop کمتر مینیمال است:
# Set the noise scheduler
noise_scheduler = DDPMScheduler(num_train_timesteps=1000, beta_schedule="squaredcos_cap_v2")
# Training loop
optimizer = torch.optim.AdamW(model.parameters(), lr=4e-4)
losses = []
for epoch in range(30):
for step, batch in enumerate(train_dataloader):
clean_images = batch["images"].to(device)
# Sample noise to add to the images
noise = torch.randn(clean_images.shape).to(clean_images.device)
bs = clean_images.shape[0]
# Sample a random timestep for each image
timesteps = torch.randint(0, noise_scheduler.num_train_timesteps, (bs,), device=clean_images.device).long()
# Add noise to the clean images according to the noise magnitude at each timestep
noisy_images = noise_scheduler.add_noise(clean_images, noise, timesteps)
# Get the model prediction
noise_pred = model(noisy_images, timesteps, return_dict=False)[0]
# Calculate the loss
loss = F.mse_loss(noise_pred, noise)
loss.backward(loss)
losses.append(loss.item())
# Update the model parameters with the optimizer
optimizer.step()
optimizer.zero_grad()
if (epoch + 1) % 5 == 0:
loss_last_epoch = sum(losses[-len(train_dataloader) :]) / len(train_dataloader)
print(f"Epoch:{epoch+1}, loss: {loss_last_epoch}")
Epoch:5, loss: 0.16273280512541533 Epoch:10, loss: 0.11161588924005628 Epoch:15, loss: 0.10206522420048714 Epoch:20, loss: 0.08302505919709802 Epoch:25, loss: 0.07805309211835265 Epoch:30, loss: 0.07474562455900013
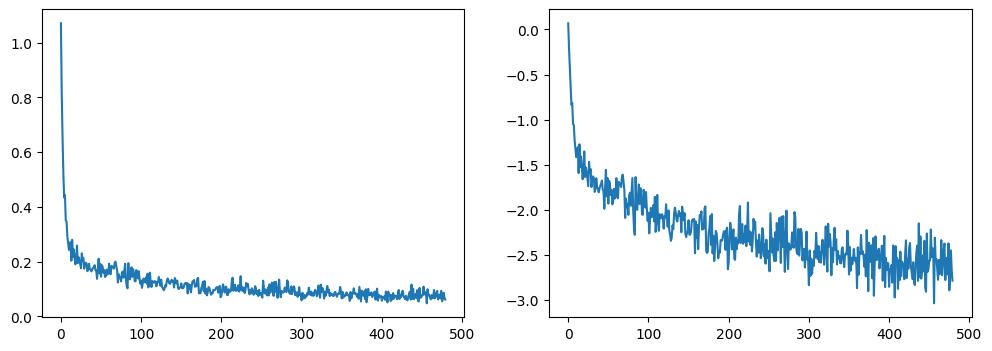
با رسم loss، مشاهده میکنیم که مدل در ابتدا بهسرعت بهبود مییابد و سپس با سرعت کندتری بهبود پیدا میکند (این روند وقتی از مقیاس لگاریتمی استفاده میکنیم، همانطور که در سمت راست نشان داده شده، واضحتر است):
fig, axs = plt.subplots(1, 2, figsize=(12, 4)) axs[0].plot(losses) axs[1].plot(np.log(losses)) plt.show()
به عنوان جایگزین اجرای کد آموزش بالا، میتوانید از مدل موجود در pipeline به این شکل استفاده کنید:
# Uncomment to instead load the model I trained earlier: # model = butterfly_pipeline.unet
گام ۶: تولید تصاویر
چگونه میتوان با این مدل تصاویر تولید کرد؟
گزینه ۱: ایجاد یک pipeline
from diffusers import DDPMPipeline image_pipe = DDPMPipeline(unet=model, scheduler=noise_scheduler)
pipeline_output = image_pipe() pipeline_output.images[0]
![]()
میتونیم این pipeline هم در یک فولدر برای بعدا سیو کنیم:
image_pipe.save_pretrained("my_pipeline")
اگر محتوای این پوشه را نگاهی بیندازیم این فایلها را خواهیم دید:
!ls my_pipeline/
model_index.json scheduler unet
زیرپوشههای scheduler و unet شامل همه موارد لازم برای بازسازی این اجزا هستند. به عنوان مثال، در داخل پوشه unet میتوانید وزنهای مدل (diffusion_pytorch_model.bin) و همچنین یک فایل پیکربندی (config) پیدا کنید که معماری UNet را مشخص میکند.
!ls my_pipeline/unet/
config.json diffusion_pytorch_model.bin
این فایلها بهطور کامل شامل همه موارد لازم برای بازسازی pipeline هستند. شما میتوانید آنها را بهصورت دستی در Hub آپلود کنید تا pipeline را با دیگران به اشتراک بگذارید، یا در بخش بعدی کد مربوط به انجام این کار از طریق API را بررسی کنید.
گزینه ۲: نوشتن یک Sampling Loop
اگر متد forward در pipeline را بررسی کنید، میتوانید ببینید هنگام اجرای image_pipe() چه اتفاقی میافتد:
# ??image_pipe.forward
ما با نویز تصادفی شروع میکنیم و از طریق timesteps scheduler از بیشترین تا کمترین نویز عبور میکنیم، و در هر مرحله مقداری از نویز را بر اساس پیشبینی مدل حذف میکنیم:
# Random starting point (8 random images):
sample = torch.randn(8, 3, 32, 32).to(device)
for i, t in enumerate(noise_scheduler.timesteps):
# Get model pred
with torch.no_grad():
residual = model(sample, t).sample
# Update sample with step
sample = noise_scheduler.step(residual, t, sample).prev_sample
show_images(sample)
![]()
در مثال قبلی، ما pipeline خود را در یک پوشه محلی ذخیره کردیم.
برای اینکه مدل را به Hugging Face Hub ارسال کنیم، باید یک repository برای مدل مشخص کنیم تا فایلها در آن آپلود شوند.
نام این repository بر اساس model ID تعیین میشود (میتوانید model_name را با نام دلخواه خود جایگزین کنید؛ فقط باید شامل username شما باشد).
تابع get_full_repo_name() همین کار را انجام میدهد و نام کامل ریپو (با یوزرنیم + مدلنیم) را برمیگرداند.
from huggingface_hub import get_full_repo_name model_name = "sd-class-butterflies-32" hub_model_id = get_full_repo_name(model_name) hub_model_id
حالا باید یک repository روی Hugging Face Hub ساخته و مدل را در آن قرار بدهیم.
from huggingface_hub import HfApi, create_repo
create_repo(hub_model_id)
api = HfApi()
api.upload_folder(folder_path="my_pipeline/scheduler", path_in_repo="", repo_id=hub_model_id)
api.upload_folder(folder_path="my_pipeline/unet", path_in_repo="", repo_id=hub_model_id)
api.upload_file(
path_or_fileobj="my_pipeline/model_index.json",
path_in_repo="model_index.json",
repo_id=hub_model_id,
)
آخرین کاری که باید انجام دهیم این است که یک کارت مدل (Model Card) خوب بسازیم تا مولد پروانهی ما به راحتی در Hub پیدا شود (میتوانید توضیحات را گسترش دهید و ویرایش کنید!).
from huggingface_hub import ModelCard
content = f"""
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class ](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute .
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('{hub_model_id}')
image = pipeline().images[0]
image
حالا که مدل روی Hub قرار گرفته است، میتوانید آن را از هر جایی با استفاده از متدfrom_pretrained() از کلاس DDPMPipeline به شکل زیر دانلود کنید:
from diffusers import DDPMPipeline image_pipe = DDPMPipeline.from_pretrained(hub_model_id) pipeline_output = image_pipe() pipeline_output.images[0]
منبع: https://huggingface.co/learn/diffusion-course/
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

دیدگاهتان را بنویسید