Foundation model یا مدل بنیادی
- مدل پایه چیست؟
- چه چیزی مدلهای پایه را منحصربهفرد میکند؟
- چرا مدلهای پایه اهمیت دارند؟
- مدلهای پایه چگونه کار میکنند؟
- مدلهای پایه چه تواناییهایی دارند؟
- نمونههایی از مدلهای پایه
- چالشهای مدلهای پایه
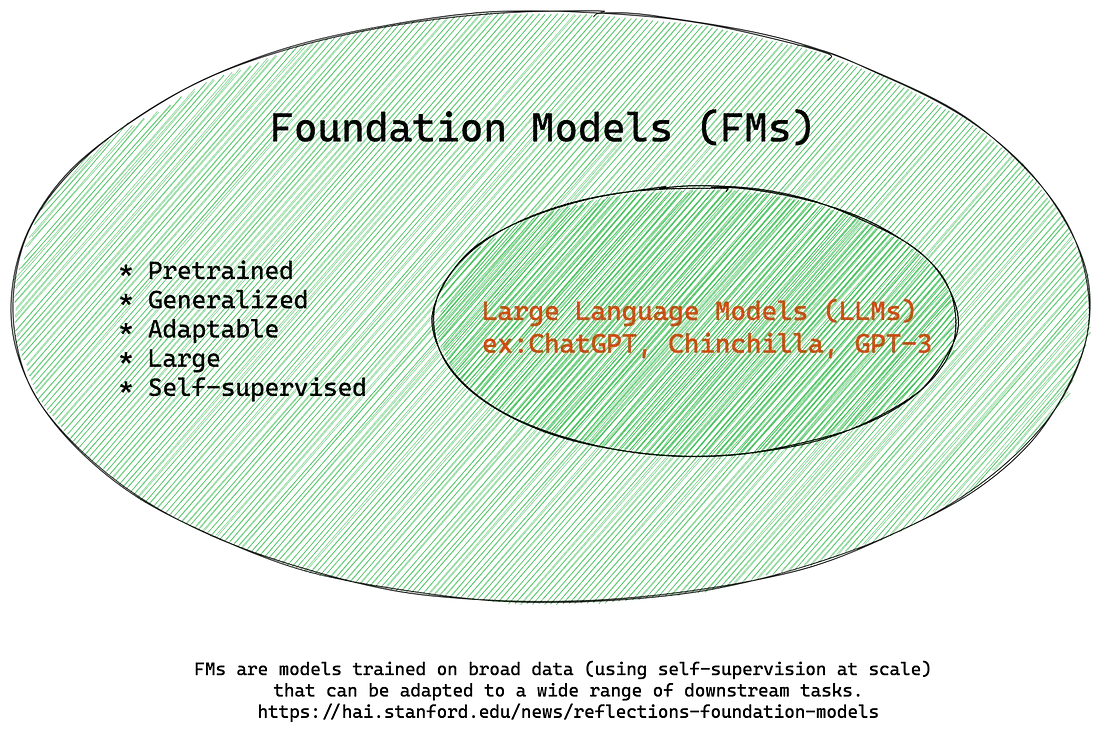
مدل پایه چیست؟
مدلهای پایه (Foundation Models) که بر روی مجموعه دادههای عظیمی آموزش دیدهاند، شبکههای عصبی عمیق و بزرگی هستند که روش کار دانشمندان داده را در یادگیری ماشین (ML) متحول کردهاند. به جای توسعه هوش مصنوعی (AI) از ابتدا، دانشمندان داده از یک مدل پایه به عنوان نقطه شروع برای توسعه مدلهای ML استفاده میکنند که برنامههای جدید را سریعتر و با هزینه کمتر قدرت میبخشند. اصطلاح مدل پایه توسط محققان برای توصیف مدلهای ML که بر روی طیف وسیعی از دادههای عمومی و بدون برچسب آموزش دیدهاند و قادر به انجام وظایف عمومی متنوعی مانند درک زبان، تولید متن و تصویر، و مکالمه به زبان طبیعی هستند، ابداع شد.
چه چیزی مدلهای پایه را منحصربهفرد میکند؟
یکی از ویژگیهای منحصربهفرد مدلهای پایه، انعطافپذیری آنها است. این مدلها میتوانند طیف گستردهای از وظایف متفاوت را با دقت بالا بر اساس ورودیها (prompts) انجام دهند. برخی از این وظایف عبارتاند از:
- پردازش زبان طبیعی (NLP)
- پاسخگویی به سؤالات
- طبقهبندی تصاویر
اندازه و ماهیت عمومی مدلهای پایه آنها را از مدلهای سنتی یادگیری ماشین متمایز میکند، که معمولاً وظایف خاصی مانند تحلیل احساسات در متن، دستهبندی تصاویر و پیشبینی روندها را انجام میدهند.
میتوانید از مدلهای foundation به عنوان مدلهای پایه برای توسعه کاربردهای تخصصیتر downstream استفاده کنید. این مدلها نتیجه بیش از یک دهه کار هستند که طی آن اندازه و پیچیدگیشان افزایش یافته است.
برای مثال، BERT، یکی از اولین مدلهای foundation دوطرفه، در سال ۲۰۱۸ منتشر شد. این مدل با استفاده از ۳۴۰ میلیون پارامتر و یک مجموعه داده آموزشی ۱۶ گیگابایتی آموزش دیده بود. در سال ۲۰۲۳، تنها پنج سال بعد، OpenAI مدل GPT-4 را با استفاده از ۱۷۰ تریلیون پارامتر و یک مجموعه داده آموزشی ۴۵ گیگابایتی آموزش داد. طبق گفته OpenAI، قدرت محاسباتی مورد نیاز برای مدلسازی foundation از سال ۲۰۱۲ هر ۳.۴ ماه دو برابر شده است. مدلهای FM امروزی، مانند مدلهای زبانی بزرگ (LLM) مثل Claude 2 و Llama 2، و مدل تبدیل متن به تصویر Stable Diffusion از شرکت Stability AI، میتوانند بدون نیاز به تنظیمات اضافی، طیف وسیعی از وظایف در حوزههای مختلف را انجام دهند، مانند نوشتن پستهای وبلاگ، تولید تصاویر، حل مسائل ریاضی، شرکت در گفتگو و پاسخ به سؤالات بر اساس یک سند.
چرا مدلهای پایه اهمیت دارند؟
مدلهای پایه میتوانند چرخه عمر یادگیری ماشین را به طور اساسی تغییر دهند. با اینکه توسعه این مدلها از ابتدا میلیونها دلار هزینه دارد، در بلندمدت مقرونبهصرفه است. زیرا دانشمندان داده میتوانند با استفاده از مدلهای از پیش آموزشدیدهشده، برنامههای جدید ML را سریعتر و ارزانتر توسعه دهند.
یکی از کاربردهای بالقوه، خودکارسازی وظایف و فرآیندها، به ویژه آنهایی است که نیازمند قابلیتهای استدلال هستند. در اینجا چند کاربرد برای مدلهای foundation آورده شده است:
- پشتیبانی مشتری
- ترجمه زبان
- تولید محتوا
- نگارش متون تبلیغاتی
- طبقهبندی تصاویر
- ایجاد و ویرایش تصاویر با وضوح بالا
- استخراج اطلاعات از اسناد
- رباتیک
- مراقبتهای بهداشتی
- خودروهای خودران
مدلهای پایه چگونه کار میکنند؟
مدلهای پایه نوعی هوش مصنوعی مولد (Generative AI) هستند. آنها بر اساس یک یا چند ورودی (prompt) و دستورالعملهای زبان انسانی، خروجی تولید میکنند. این مدلها بر روی شبکههای عصبی پیچیدهای مانند GANs، Transformers و VAE ساخته شدهاند.
اگرچه هر نوع شبکه به شکل متفاوتی عمل میکند، اما اصول پشت نحوه کار آنها مشابه است. به طور کلی، یک مدل بنیادی از الگوها و روابط آموخته شده برای پیشبینی مورد بعدی در یک توالی استفاده میکند. به عنوان مثال، در تولید تصویر، مدل تصویر را تحلیل کرده و نسخهای واضحتر و دقیقتر از تصویر ایجاد میکند. به طور مشابه، با متن، مدل کلمه بعدی در یک رشته متنی را بر اساس کلمات قبلی و بافت آن پیشبینی میکند. سپس با استفاده از تکنیکهای توزیع احتمالی، کلمه بعدی را انتخاب میکند.
مدلهای foundation از یادگیری خود-نظارتی برای ایجاد برچسبها از دادههای ورودی استفاده میکنند. این بدان معناست که هیچ کس مدل را با مجموعه دادههای آموزشی برچسبگذاری شده آموزش نداده است. این ویژگی، LLMها را از معماریهای ML قبلی که از یادگیری با نظارت یا بدون نظارت استفاده میکنند، متمایز میسازد.
مدلهای پایه چه تواناییهایی دارند؟
مدلهای پایه یا foundation، حتی با وجود اینکه از قبل آموزش دیدهاند، میتوانند در حین استنتاج (Inference) از ورودیهای داده یا promptها یاد بگیرند. این بدان معناست که میتوانید از طریق promptهای دقیق و حساب شده، خروجیهای جامعی را توسعه دهید. وظایفی که مدلهای بنیادی میتوانند انجام دهند شامل پردازش زبان، درک بصری، تولید کد و تعامل انسانمحور است.
پردازش زبان
این مدلها قابلیتهای قابل توجهی برای پاسخ به سؤالات زبان طبیعی و حتی توانایی نوشتن اسکریپتها یا مقالات کوتاه در پاسخ به promptها دارند. آنها همچنین میتوانند با استفاده از فناوریهای NLP، زبانها را ترجمه کنند.
درک بصری
مدلهای بنیادی در بینایی کامپیوتر، به ویژه در شناسایی تصاویر و اشیاء فیزیکی عملکرد عالی دارند. این قابلیتها ممکن است در کاربردهایی مانند رانندگی خودکار و رباتیک استفاده شوند. قابلیت دیگر، تولید تصاویر از متن ورودی و همچنین ویرایش عکس و ویدیو است.
تولید کد
مدلهای بنیادی میتوانند بر اساس ورودیهای زبان طبیعی، کد کامپیوتری در زبانهای برنامهنویسی مختلف تولید کنند. استفاده از مدلهای بنیادی برای ارزیابی و اشکالزدایی کد نیز امکانپذیر است.
تعامل انسانمحور
مدلهای هوش مصنوعی مولد از ورودیهای انسانی برای یادگیری و بهبود پیشبینیها استفاده میکنند. یک کاربرد مهم و گاهی نادیده گرفته شده، توانایی این مدلها در پشتیبانی از تصمیمگیری انسان است. استفادههای بالقوه شامل تشخیصهای بالینی، سیستمهای پشتیبانی تصمیم و تحلیلها میشود.
قابلیت دیگر، توسعه کاربردهای جدید AI با fine-tuning مدلهای بنیادی موجود است.
تبدیل گفتار به متن
از آنجا که مدلهای بنیادی زبان را درک میکنند، میتوانند برای وظایف تبدیل گفتار به متن مانند رونویسی و زیرنویس ویدیو در زبانهای مختلف استفاده شوند.
نمونههایی از مدلهای پایه
مدلهای پایه در سالهای اخیر رشد قابل توجهی داشتهاند. برخی از مدلهای برجسته از سال ۲۰۱۸ تاکنون عبارتاند از:
- BERT (مدل bidirectional مبتنی بر Transformer)
منتشر شده در سال ۲۰۱۸، Bidirectional Encoder Representations from Transformers (BERT) یکی از اولین مدلهای foundation بود. BERT یک مدل bidirectional است که زمینه یک توالی کامل را تحلیل میکند و سپس پیشبینی میکند. این مدل روی مجموعهای از متون ساده و ویکیپدیا با استفاده از ۳.۳ میلیارد توکن (کلمه) و ۳۴۰ میلیون پارامتر آموزش دیده است. BERT میتواند به سؤالات پاسخ دهد، جملات را پیشبینی کند و متون را ترجمه کند. - GPT (Generative Pre-trained Transformer) از OpenAI
مدل Generative Pre-trained Transformer (GPT) در سال ۲۰۱۸ توسط OpenAI توسعه یافت. این مدل از یک دیکودر ترانسفورمر ۱۲ لایه با مکانیسم خود-توجهی استفاده میکند و روی مجموعه داده BookCorpus که شامل بیش از ۱۱,۰۰۰ رمان رایگان است، آموزش دیده است. یک ویژگی قابل توجه GPT-1 توانایی انجام یادگیری بدون نمونه (zero-shot learning) است.
GPT-2 در سال ۲۰۱۹ منتشر شد. OpenAI آن را با استفاده از ۱.۵ میلیارد پارامتر (در مقایسه با ۱۱۷ میلیون پارامتر استفاده شده در GPT-1) آموزش داد. GPT-3 دارای یک شبکه عصبی ۹۶ لایه و ۱۷۵ میلیارد پارامتر است و با استفاده از مجموعه داده Common Crawl با ۵۰۰ میلیارد کلمه آموزش دیده است. چتبات محبوب ChatGPT بر اساس GPT-3.5 است. و GPT-4، آخرین نسخه، در اواخر سال ۲۰۲۲ راهاندازی شد و با موفقیت آزمون یکنواخت وکالت را با نمره ۲۹۷ (۷۶٪) گذراند.
- Amazon Nova (شامل مدلهای درک متن و تصویر)
Amazon Nova نسل جدیدی از مدلهای foundation که توسط آمازون اراده شده اند.Amazon Nova Micro، Amazon Nova Lite و Amazon Nova Pro مدلهای درک هستند که ورودیهای متنی، تصویری و ویدیویی را میپذیرند و خروجی متنی تولید میکنند.
Amazon Nova Canvas و Amazon Nova Reel مدلهای تولید محتوای خلاقانه هستند که ورودیهای متنی و تصویری را میپذیرند و تصاویر یا ویدیوهای خروجی تولید میکنند. آنها برای ارائه تصاویر و ویدیوهای قابل سفارشیسازی با کیفیت بالا برای تولید محتوای بصری طراحی شدهاند. - AI21 Jurassic (مدل پردازش زبان طبیعی)
Jurassic-1 که در سال ۲۰۲۱ منتشر شد، یک مدل زبانی auto-regressive با ۷۶ لایه با ۱۷۸ میلیارد پارامتر است. Jurassic-1 متن شبیه انسان تولید میکند و وظایف پیچیده را حل میکند. عملکرد آن قابل مقایسه با GPT-3 است.در مارس ۲۰۲۳، AI21 Labs نسخه Jurrassic-2 را منتشر کرد که قابلیتهای پیروی از دستورالعمل و زبانی بهبود یافتهای دارد. - Claude 3.7 Sonnet
هوشمندترین و پیشرفتهترین مدل Anthropic، Claude 3.7 Sonnet، قابلیتهای استثنایی در طیف متنوعی از وظایف و ارزیابیها نشان میدهد و همچنین از Claude 3 Opus پیشی میگیرد.
- Claude 3 Opus
Opus یک مدل بسیار هوشمند با عملکرد قابل اعتماد در وظایف پیچیده است. میتواند با promptهای باز و سناریوهای ناشناخته با روانی قابل توجه و درک شبیه انسان کار کند. از Opus برای خودکارسازی وظایف و تسریع تحقیق و توسعه در طیف متنوعی از موارد استفاده و صنایع استفاده کنید. - Claude Haiku
Haiku سریعترین و فشردهترین مدل Anthropic برای پاسخگویی تقریباً آنی است. Haiku بهترین انتخاب برای ساخت تجربههای AI بینقص است که تعاملات انسانی را تقلید میکنند. شرکتها میتوانند از Haiku برای نظارت بر محتوا، بهینهسازی مدیریت موجودی، تولید ترجمههای سریع و دقیق، خلاصهسازی دادههای ساختار نیافته و موارد دیگر استفاده کنند. - Cohere (مدلهای پردازش زبان و تولید متن)
Cohere دو LLM دارد: یکی مدل تولید با قابلیتهای مشابه GPT-3 و دیگری representation model برای درک زبانها است. در حالی که Cohere تنها ۵۲ میلیارد پارامتر دارد، در بسیاری از جنبهها از GPT-3 پیشی میگیرد. - Stable Diffusion (مدل تولید تصویر از متن)
Stable Diffusion یک مدل متن به تصویر است که میتواند تصاویر واقعی با وضوح بالا تولید کند. این مدل در سال ۲۰۲۲ منتشر شد و دارای یک مدل انتشار است که از فناوریهای نویزدار کردن و حذف نویز برای یادگیری نحوه ایجاد تصاویر استفاده میکند.این مدل کوچکتر از فناوریهای انتشار رقیب مانند DALL-E 2 است، به این معنی که نیازی به زیرساخت محاسباتی گسترده ندارد. Stable Diffusion روی یک کارت گرافیک معمولی یا حتی روی یک گوشی هوشمند با پلتفرم Snapdragon Gen2 اجرا میشود. - BLOOM (مدل چندزبانه با قابلیت تولید متن و کد)
BLOOM یک مدل چندزبانه (multilingual) با معماری مشابه GPT-3 است. این مدل در سال ۲۰۲۲ به عنوان یک تلاش مشترک با مشارکت بیش از هزار دانشمند و تیم Hugging Space توسعه یافت. این مدل دارای ۱۷۶ میلیارد پارامتر است و آموزش آن سه و نیم ماه با استفاده از ۳۸۴ GPU Nvidia A100 طول کشید. اگرچه checkpoint این مدب به ۳۳۰ گیگابایت فضای ذخیرهسازی نیاز دارد، اما روی یک کامپیوتر مستقل با ۱۶ گیگابایت RAM اجرا میشود. BLOOM میتواند متن به ۴۶ زبان ایجاد کند و به ۱۳ زبان برنامهنویسی کد بنویسد. - Hugging Face (پلتفرم توسعه و بهاشتراکگذاری مدلهای یادگیری ماشین)
Hugging Face یک پلتفرم است که ابزارهای متنباز برای ساخت و استقرار مدلهای یادگیری ماشین ارائه میدهد. به عنوان یک کامیونیتی (community hub) عمل میکند و توسعهدهندگان میتوانند مدلها و مجموعه دادهها را به اشتراک بگذارند و سرچ کنند. عضویت برای افراد رایگان است، اگرچه اشتراکهای پولی سطوح بالاتری از دسترسی را ارائه میدهند. شما دسترسی عمومی به تقریباً ۲۰۰,۰۰۰ مدل و ۳۰,۰۰۰ مجموعه داده دارید.
چالشهای مدلهای پایه
مدلهای foundation میتوانند به طور منسجم به promptها درباره موضوعاتی که به طور صریح روی آنها آموزش ندیدهاند، پاسخ دهند. اما آنها نقاط ضعف خاصی دارند. در اینجا برخی از چالشهای پیش روی مدلهای foundation آمده است:
- نیاز به زیرساخت قوی:
توسعه مدلهای پایه از ابتدا بسیار پرهزینه و زمانبر است. و به منابع عظیمی نیاز دارد، و آموزش ممکن است ماهها طول بکشد. - ادغام در سیستمهای نرمافزاری – برای کاربرد عملی، این مدلها باید با ابزارهای مهندسی prompt و fine-tuning یکپارچه شوند.
- عدم درک عمیق – مدلها ممکن است پاسخهای دستوری و ظاهراً صحیح، اما بدون درک واقعی از مفهوم پرسش ارائه دهند. مدلهای foundation در درک زمینه یک prompt مشکل دارند. و آنها از نظر اجتماعی یا روانشناختی آگاه نیستند.
- پاسخهای نادرست یا نامناسب – برخی پاسخها ممکن است اشتباه، نامناسب یا مغرضانه باشند.
- تعصب و سوگیری دادهها – اگر مجموعه دادههای آموزشی حاوی محتوای نامناسب یا جانبدارانه باشند، مدل این سوگیری را به ارث خواهد برد.
تعصب یک احتمال مشخص است زیرا مدلها میتوانند گفتار نفرتانگیز و زیرمتنهای نامناسب را از مجموعه دادههای آموزشی دریافت کنند. برای جلوگیری از این مسئله، توسعهدهندگان باید دادههای آموزشی را با دقت فیلتر کرده و هنجارهای خاصی را در مدلهای خود کدگذاری کنند.
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

دیدگاهتان را بنویسید