فصل 15: مدلهای زبانی و ترنسفورمر در Keras
این پست ترجمه فصل 15 کتاب Deep Learning with Python ویرایش سوم است.
این فصل شامل موارد زیر است:
- چگونه با یک مدل یادگیری عمیق متن تولید کنیم
- آموزش یک مدل برای ترجمه از انگلیسی به اسپانیایی
- ترنسفورمر، یک معماری قدرتمند برای مسائل مدلسازی متن
با پوشش مبانی پیشپردازش و مدلسازی متن در فصل قبل، این فصل به برخی از مسائل پیچیدهتر زبانی مانند ترجمه ماشینی میپردازد. ما یک درک محکم از مدل ترنسفورمر که محصولاتی مانند ChatGPT را قدرت میبخشد و به راهاندازی موج سرمایهگذاری در پردازش زبان طبیعی (NLP) کمک کرده است، ایجاد خواهیم کرد.
15.1 مدل زبانی
در فصل قبل، یاد گرفتیم چگونه دادههای متنی را به ورودیهای عددی تبدیل کرده و از این نمایش عددی برای طبقهبندی نقدهای فیلم استفاده کنیم. با این حال، طبقهبندی متن از بسیاری جهات یک مسئله منحصر به فرد ساده است. ما فقط نیاز داریم که برای طبقهبندی دودویی یک عدد اعشار واحد خروجی دهیم و در بدترین حالت، N عدد برای طبقهبندی N-طرفه.
اما در مورد سایر وظایف مبتنی بر متن مانند پاسخ به سوال یا ترجمه چطور؟ برای بسیاری از مسائل دنیای واقعی، ما به یک مدل علاقهمندیم که بتواند یک خروجی متنی برای یک ورودی داده شده تولید کند. درست مانند اینکه برای مدیریت متن در “مسیر ورود” به مدل به tokenizer و embedding نیاز داشتیم، باید قبل از تولید متن در “مسیر خروج”، برخی تکنیکها را بسازیم.
ما نیاز نداریم از ابتدا شروع کنیم؛ میتوانیم به استفاده از ایده دنباله اعداد صحیح به عنوان یک نمایش عددی طبیعی برای متن ادامه دهیم. در فصل قبل، tokenize کردن یک رشته را پوشش دادیم، جایی که ورودیها را به token تقسیم کرده و هر token را به یک عدد صحیح نگاشت میکنیم. میتوانیم یک دنباله را با عکس این فرآیند detokenize کنیم – اعداد صحیح را به tokenهای رشتهای برگردانده و آنها را به هم وصل میکنیم. با این رویکرد، مسئله ما تبدیل میشود به ساختن مدلی که میتواند یک دنباله عدد صحیح از tokenها را پیشبینی کند.
مفهوم کلیدی
یک مدل زبانی (Language Model) مدلی است که در سادهترین شکل خود، یک توزیع احتمال را یاد میگیرد: p(token|past tokens). با توجه به دنبالهای از تمام tokenهای مشاهده شده تا یک نقطه، یک مدل زبانی تلاش میکند تا یک توزیع احتمال روی تمام tokenهای ممکنی که میتوانند بعدی باشند، خروجی دهد.
سادهترین گزینهای که ممکن است در نظر بگیریم این است که یک طبقهبند مستقیم روی فضای تمام دنبالههای عددی خروجی ممکن آموزش دهیم، اما محاسبات ساده نشان میدهد که این غیرقابل حل است. با یک واژگان 20،000 کلمهای، 20000^4 یا 160 کوادریلیون دنباله 4 کلمهای ممکن وجود دارد، و اتمهای موجود در جهان کمتر از دنبالههای 20 کلمهای ممکن هستند.
یک رویکرد عملی برای امکانپذیر کردن چنین مسئله پیشبینی این است که مدلی بسازیم که فقط یک خروجی token در یک زمان پیشبینی کند. با پیشبینی مکرر token بعدی، مدلی ساختهایم که میتواند یک دنباله طولانی از متن تولید کند.
15.1.1 آموزش یک مدل زبانی شکسپیر
برای شروع، میتوانیم مجموعهای از برخی نمایشنامهها و سرودههای شکسپیر را دانلود کنیم.
import keras
filename = keras.utils.get_file(
origin=(
"https://storage.googleapis.com/download.tensorflow.org/"
"data/shakespeare.txt"
),
)
shakespeare = open(filename, "r").read()
لیست 15.1: دانلود مجموعه خلاصهشده از آثار شکسپیر
بیایید نگاهی به برخی از دادهها بیندازیم:
>>> shakespeare[:250] First Citizen: Before we proceed any further, hear me speak. All: Speak, speak. First Citizen: You are all resolved rather to die than to famish? All: Resolved. resolved. First Citizen: First, you know Caius Marcius is chief enemy to the people.
برای ساختن یک مدل زبانی از این ورودی، ابتدا باید متن منبع را پردازش کنیم. دادههای خود را به قطعات همطول تقسیم میکنیم، درست مانند کاری که برای اندازهگیریهای آب و هوا در فصل سریهای زمانی انجام دادیم. چون در اینجا از یک tokenizer سطح کاراکتر استفاده میکنیم، میتوانیم این تقسیمبندی را مستقیماً روی ورودی رشته انجام دهیم. یک رشته 100 کاراکتری به یک دنباله 100 عددی نگاشت خواهد شد.
همچنین هر ورودی را به دو دنباله feature و label جداگانه تقسیم میکنیم، که هر دنباله label به سادگی دنباله ورودی با یک کاراکتر جابهجایی است.
import tensorflow as tf
# اندازه قطعهای که در طول آموزش استفاده خواهیم کرد
sequence_length = 100
def split_input(input, sequence_length):
for i in range(0, len(input), sequence_length):
yield input[i : i + sequence_length]
features = list(split_input(shakespeare[:-1], sequence_length))
labels = list(split_input(shakespeare[1:], sequence_length))
dataset = tf.data.Dataset.from_tensor_slices((features, labels))
لیست 15.2: تقسیم متن به قطعات برای آموزش مدل زبانی
برای نگاشت این ورودی به یک دنباله از اعداد صحیح، میتوانیم دوباره از لایه TextVectorization که در فصل گذشته دیدیم استفاده کنیم. برای یادگیری یک واژگان سطح کاراکتر به جای واژگان سطح کلمه، میتوانیم آرگومان split را تغییر دهیم. به جای تقسیم پیشفرض "whitespace"، به جای آن با "character" تقسیم میکنیم.
from keras import layers
tokenizer = layers.TextVectorization(
standardize=None,
split="character",
output_sequence_length=sequence_length,
)
tokenizer.adapt(dataset.map(lambda text, labels: text))
لیست 15.3: یادگیری یک واژگان سطح کاراکتر با لایه TextVectorization
چرا سطح کاراکتر؟
در این مثال از tokenization سطح کاراکتر استفاده میکنیم زیرا:
- واژگان بسیار کوچک است (فقط 67 کاراکتر)
- آموزش سریعتر است
- برای یک مثال آموزشی مناسبتر است
⚠️ توجه: در پروژههای واقعی معمولاً از tokenization سطح کلمه یا زیرکلمه (subword) استفاده میشود.
بیایید واژگان را بررسی کنیم:
>>> vocabulary_size = tokenizer.vocabulary_size() >>> vocabulary_size 67
ما فقط به 67 کاراکتر نیاز داریم تا متن منبع کامل را مدیریت کنیم. سپس میتوانیم dataset خود را آماده کنیم:
dataset = dataset.map(
lambda features, labels: (tokenizer(features), tokenizer(labels)),
num_parallel_calls=8,
)
training_data = dataset.shuffle(10_000).batch(64).cache()
برای ساختن مدل زبانی ساده خود، میخواهیم احتمال یک کاراکتر را با توجه به تمام کاراکترهای گذشته پیشبینی کنیم. از میان تمام امکانات مدلسازی که تاکنون در این کتاب دیدهایم، یک RNN طبیعیترین انتخاب است.
embedding_dim = 256 hidden_dim = 1024 inputs = layers.Input(shape=(sequence_length,), dtype="int", name="token_ids") x = layers.Embedding(vocabulary_size, embedding_dim)(inputs) x = layers.GRU(hidden_dim, return_sequences=True)(x) x = layers.Dropout(0.1)(x) # یک توزیع احتمال روی تمام tokenهای بالقوه در واژگان ما خروجی میدهد outputs = layers.Dense(vocabulary_size, activation="softmax")(x) model = keras.Model(inputs, outputs)
لیست 15.4: ساختن یک مدل زبانی کوچک
بیایید مدل را آموزش دهیم:
model.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
metrics=["sparse_categorical_accuracy"],
)
model.fit(training_data, epochs=20)
لیست 15.5: آموزش یک مدل زبانی کوچک
15.1.2 تولید شکسپیر
حالا که یک مدل آموزش دادهایم که میتواند tokenهای منفرد بعدی را با دقت پیشبینی کند، میخواهیم از آن برای برونیابی کل دنباله پیشبینی شده استفاده کنیم. میتوانیم این کار را با فراخوانی مدل در یک حلقه انجام دهیم، جایی که خروجی پیشبینی شده مدل در یک گام زمانی، ورودی مدل در گام زمانی بعدی میشود. یک مدل ساخته شده برای این نوع حلقه بازخورد گاهی اوقات مدل خودبازگشتی (Autoregressive) نامیده میشود.
برای اجرای چنین حلقهای، باید یک جراحی جزئی روی مدل انجام دهیم:
# یک مدل ایجاد میکند که وضعیت RNN را دریافت و خروجی میدهد
inputs = keras.Input(shape=(1,), dtype="int", name="token_ids")
input_state = keras.Input(shape=(hidden_dim,), name="state")
x = layers.Embedding(vocabulary_size, embedding_dim)(inputs)
x, output_state = layers.GRU(hidden_dim, return_state=True)(
x, initial_state=input_state
)
outputs = layers.Dense(vocabulary_size, activation="softmax")(x)
generation_model = keras.Model(
inputs=(inputs, input_state),
outputs=(outputs, output_state),
)
# پارامترها را از مدل اصلی کپی میکند
generation_model.set_weights(model.get_weights())
لیست 15.6: تغییر مدل زبانی برای استنتاج خودبازگشتی
برای شروع تولید، ابتدا باید حالت داخلی GRU را با prompt خود آماده کنیم:
tokens = tokenizer.get_vocabulary()
token_ids = range(vocabulary_size)
char_to_id = dict(zip(tokens, token_ids))
id_to_char = dict(zip(token_ids, tokens))
prompt = """
KING RICHARD III:
"""
input_ids = [char_to_id[c] for c in prompt]
state = keras.ops.zeros(shape=(1, hidden_dim))
for token_id in input_ids:
inputs = keras.ops.expand_dims([token_id], axis=0)
# کاراکتر prompt را کاراکتر به کاراکتر برای بهروزرسانی state تغذیه میکند
predictions, state = generation_model.predict((inputs, state), verbose=0)
لیست 15.7: استفاده از یک prompt ثابت برای محاسبه state شروع مدل زبانی
حالا میتوانیم یک دنباله کامل تولید کنیم:
import numpy as np
generated_ids = []
max_length = 250
# کاراکترها را یکی یکی تولید میکند، و در هر تکرار یک state جدید محاسبه میکند
for i in range(max_length):
# کاراکتر بعدی، index خروجی با بالاترین احتمال است
next_char = int(np.argmax(predictions, axis=-1)[0])
generated_ids.append(next_char)
inputs = keras.ops.expand_dims([next_char], axis=0)
predictions, state = generation_model.predict((inputs, state), verbose=0)
output = "".join([id_to_char[token_id] for token_id in generated_ids])
print(prompt + output)
لیست 15.8: پیشبینی با مدل زبانی یک token در یک زمان
خروجی نمونه:
KING RICHARD III: Stay, men! hear me speak. FRIAR LAURENCE: Thou wouldst have done thee here that he hath made for them? BUCKINGHAM: What straight shall stop his dismal threatening son, Thou bear them both. Here comes the king; Though I be good to put a wife to him,
15.2 یادگیری دنباله به دنباله
حال ایده مدل زبانی را گسترش داده و آن را برای حل یک مسئله مهم – ترجمه ماشینی (Machine Translation) – به کار میبریم. ترجمه به کلاسی از مسائل مدلسازی تعلق دارد که مدلسازی دنباله به دنباله (Sequence-to-Sequence) یا Seq2Seq نامیده میشود.
تفاوت اصلی
مدل زبانی ساده: p(token | past tokens)
مدل Seq2Seq: p(target_token | past_target_tokens, source_sequence)
در Seq2Seq، مدل علاوه بر tokenهای قبلی هدف، از کل دنباله منبع نیز استفاده میکند.
الگوی کلی پشت مدلهای دنباله به دنباله در شکل 15.1 توضیح داده شده است. در طول آموزش:
- یک مدل encoder، دنباله منبع را به یک نمایش میانی تبدیل میکند.
- یک decoder با استفاده از تنظیم مدلسازی زبانی آموزش داده میشود و به طور بازگشتی token بعدی در دنباله هدف را پیشبینی میکند.
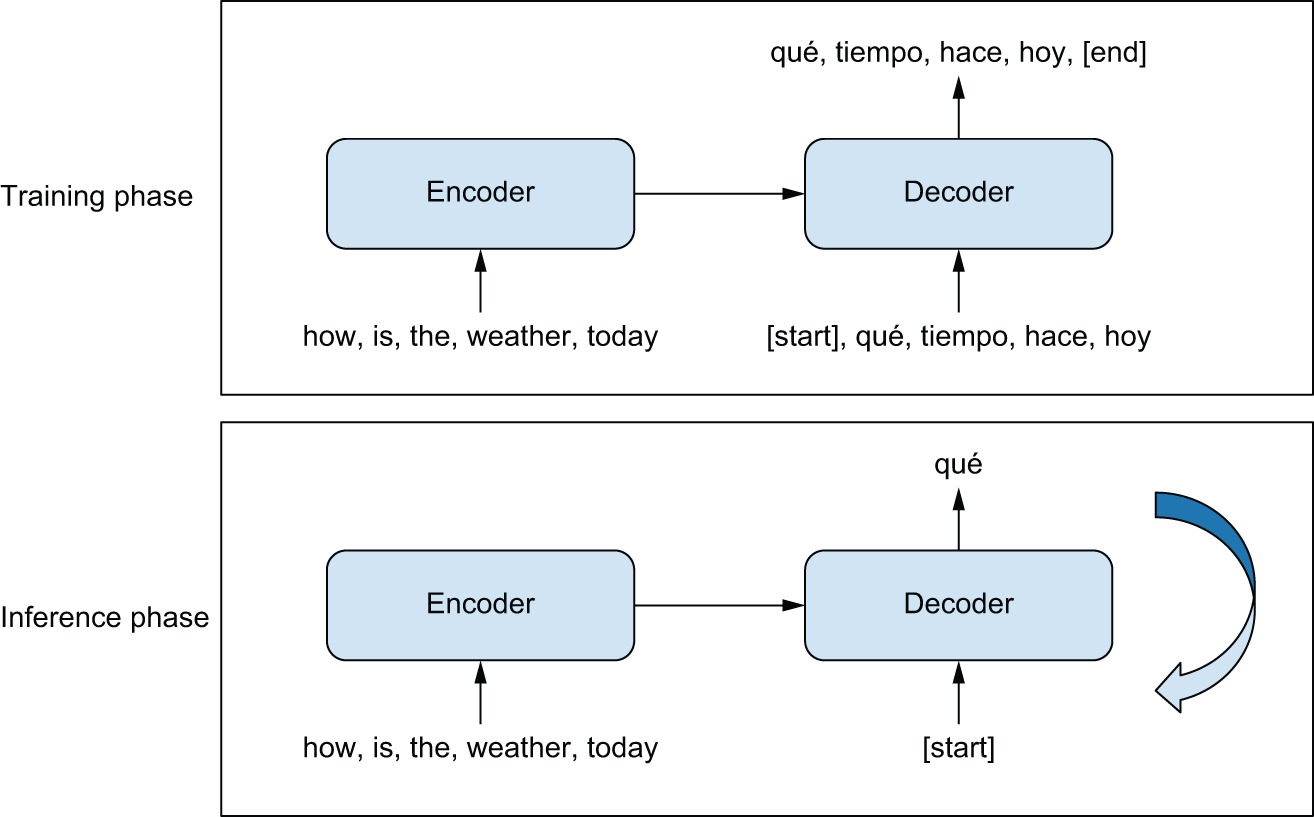
شکل 15.1: یادگیری دنباله به دنباله: دنباله منبع توسط encoder پردازش میشود و سپس به decoder ارسال میشود.
15.2.1 ترجمه انگلیسی به اسپانیایی
ما روی یک dataset ترجمه انگلیسی به اسپانیایی کار خواهیم کرد:
import pathlib
zip_path = keras.utils.get_file(
origin=(
"http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip"
),
fname="spa-eng",
extract=True,
)
text_path = pathlib.Path(zip_path) / "spa-eng" / "spa.txt"
with open(text_path) as f:
lines = f.read().split("\n")[:-1]
text_pairs = []
for line in lines:
english, spanish = line.split("\t")
spanish = "[start] " + spanish + " [end]"
text_pairs.append((english, spanish))
تقسیم به مجموعههای آموزش، اعتبارسنجی و تست:
import random random.shuffle(text_pairs) val_samples = int(0.15 * len(text_pairs)) train_samples = len(text_pairs) - 2 * val_samples train_pairs = text_pairs[:train_samples] val_pairs = text_pairs[train_samples : train_samples + val_samples] test_pairs = text_pairs[train_samples + val_samples :]
آمادهسازی tokenizer برای انگلیسی و اسپانیایی:
import string
import re
strip_chars = string.punctuation + "¿"
strip_chars = strip_chars.replace("[", "")
strip_chars = strip_chars.replace("]", "")
def custom_standardization(input_string):
lowercase = tf.strings.lower(input_string)
return tf.strings.regex_replace(
lowercase, f"[{re.escape(strip_chars)}]", ""
)
vocab_size = 15000
sequence_length = 20
english_tokenizer = layers.TextVectorization(
max_tokens=vocab_size,
output_mode="int",
output_sequence_length=sequence_length,
)
spanish_tokenizer = layers.TextVectorization(
max_tokens=vocab_size,
output_mode="int",
output_sequence_length=sequence_length + 1,
standardize=custom_standardization,
)
train_english_texts = [pair[0] for pair in train_pairs]
train_spanish_texts = [pair[1] for pair in train_pairs]
english_tokenizer.adapt(train_english_texts)
spanish_tokenizer.adapt(train_spanish_texts)
لیست 15.9: یادگیری واژگان token برای متن انگلیسی و اسپانیایی
آمادهسازی dataset:
batch_size = 64
def format_dataset(eng, spa):
eng = english_tokenizer(eng)
spa = spanish_tokenizer(spa)
features = {"english": eng, "spanish": spa[:, :-1]}
labels = spa[:, 1:]
sample_weights = labels != 0
return features, labels, sample_weights
def make_dataset(pairs):
eng_texts, spa_texts = zip(*pairs)
eng_texts = list(eng_texts)
spa_texts = list(spa_texts)
dataset = tf.data.Dataset.from_tensor_slices((eng_texts, spa_texts))
dataset = dataset.batch(batch_size)
dataset = dataset.map(format_dataset, num_parallel_calls=4)
return dataset.shuffle(2048).cache()
train_ds = make_dataset(train_pairs)
val_ds = make_dataset(val_pairs)
لیست 15.10: آمادهسازی دادههای ترجمه
15.2.2 یادگیری دنباله به دنباله با RNNها
⚠️ مشکل اساسی RNN برای ترجمه
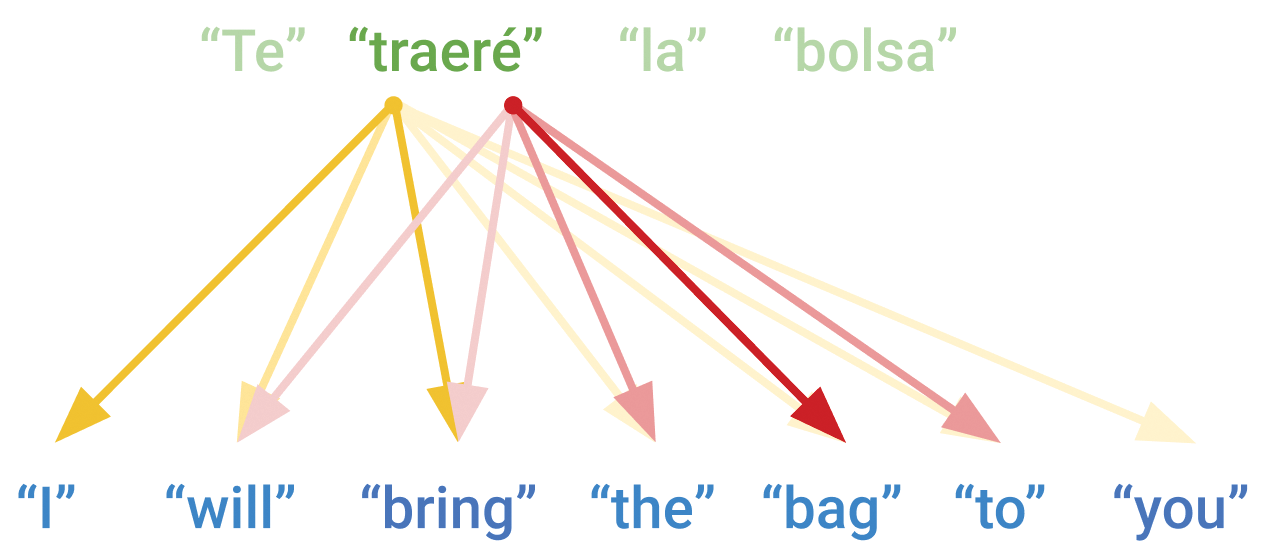
جمله را در نظر بگیرید: “I will bring the bag to you.”
ترجمه اسپانیایی: “Te traeré la bolsa”
مشکل: کلمه “Te” (معادل “you”) اولین کلمه ترجمه است، اما متناظر با آخرین کلمه جمله انگلیسی! یک RNN ساده نمیتواند بدون دیدن کل جمله منبع، این ترجمه را انجام دهد.
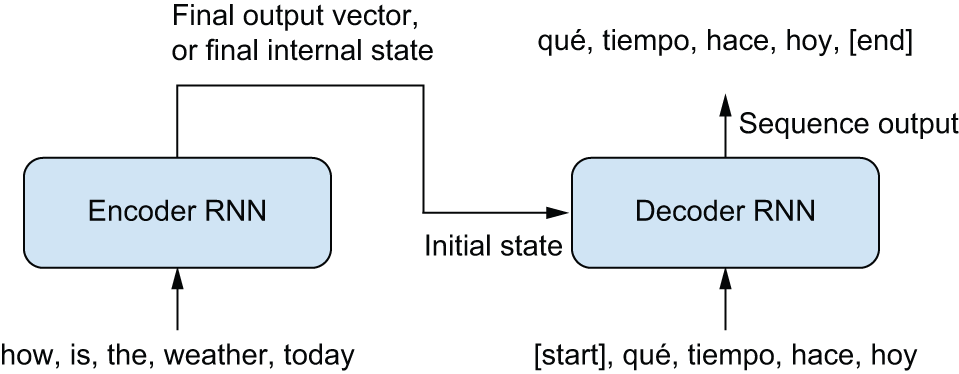
شکل 15.2: یک RNN دنباله به دنباله
ساخت encoder:
embed_dim = 256 hidden_dim = 1024 source = keras.Input(shape=(None,), dtype="int32", name="english") x = layers.Embedding(vocab_size, embed_dim, mask_zero=True)(source) rnn_layer = layers.GRU(hidden_dim) rnn_layer = layers.Bidirectional(rnn_layer, merge_mode="sum") encoder_output = rnn_layer(x)
لیست 15.11: ساختن یک encoder دنباله به دنباله
ساخت decoder:
target = keras.Input(shape=(None,), dtype="int32", name="spanish") x = layers.Embedding(vocab_size, embed_dim, mask_zero=True)(target) rnn_layer = layers.GRU(hidden_dim, return_sequences=True) x = rnn_layer(x, initial_state=encoder_output) x = layers.Dropout(0.5)(x) # کلمه بعدی ترجمه را، با توجه به کلمه فعلی، پیشبینی میکند target_predictions = layers.Dense(vocab_size, activation="softmax")(x) seq2seq_rnn = keras.Model([source, target], target_predictions)
لیست 15.12: ساختن یک decoder دنباله به دنباله
آموزش مدل:
seq2seq_rnn.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
weighted_metrics=["accuracy"],
)
seq2seq_rnn.fit(train_ds, epochs=15, validation_data=val_ds)
تولید ترجمهها:
import numpy as np
spa_vocab = spanish_tokenizer.get_vocabulary()
spa_index_lookup = dict(zip(range(len(spa_vocab)), spa_vocab))
def generate_translation(input_sentence):
tokenized_input_sentence = english_tokenizer([input_sentence])
decoded_sentence = "[start]"
for i in range(sequence_length):
tokenized_target_sentence = spanish_tokenizer([decoded_sentence])
inputs = [tokenized_input_sentence, tokenized_target_sentence]
next_token_predictions = seq2seq_rnn.predict(inputs, verbose=0)
sampled_token_index = np.argmax(next_token_predictions[0, i, :])
sampled_token = spa_index_lookup[sampled_token_index]
decoded_sentence += " " + sampled_token
if sampled_token == "[end]":
break
return decoded_sentence
test_eng_texts = [pair[0] for pair in test_pairs]
for _ in range(5):
input_sentence = random.choice(test_eng_texts)
print("-")
print(input_sentence)
print(generate_translation(input_sentence))
لیست 15.13: تولید ترجمهها با یک RNN seq2seq
⚡ 15.3 معماری ترنسفورمر
در سال 2017، Vaswani و همکارانش معماری ترنسفورمر را در مقاله تأثیرگذار “Attention Is All You Need” معرفی کردند. کشف حیاتی این بود که یک مکانیسم ساده به نام attention میتواند برای ساختن مدلهای دنباله قدرتمند بدون لایههای بازگشتی استفاده شود.
نماد Einsum چیست؟
در کدهای یادگیری ماشین، اغلب عباراتی مانند np.einsum('ij,jk->ik', a, b) خواهید دید. این نماد Einsum (Einstein summation notation) نامیده میشود.
قوانین اساسی:
- هر محور ورودی با یک حرف نشان داده میشود
- حروف تکراری → ضرب مقادیر در آن محورها
- حروفی که در خروجی نیستند → جمع روی آن محورها
مثالها:
# Transpose
np.einsum("ij->ji")
# Matrix multiplication
np.einsum("ij,jk->ik")
# Dot-product
np.einsum("i,i->")
15.3.2 Attention با dot-product
ایده اصلی Attention
تصور کنید دارید کتاب درسی میخوانید. وقتی به سوالی میرسید، به جای خواندن مجدد کل کتاب، فقط به بخشهای مرتبط برمیگردید. Attention دقیقاً همین کار را میکند – به مدل اجازه میدهد به بخشهای مهم توجه بیشتری داشته باشد.
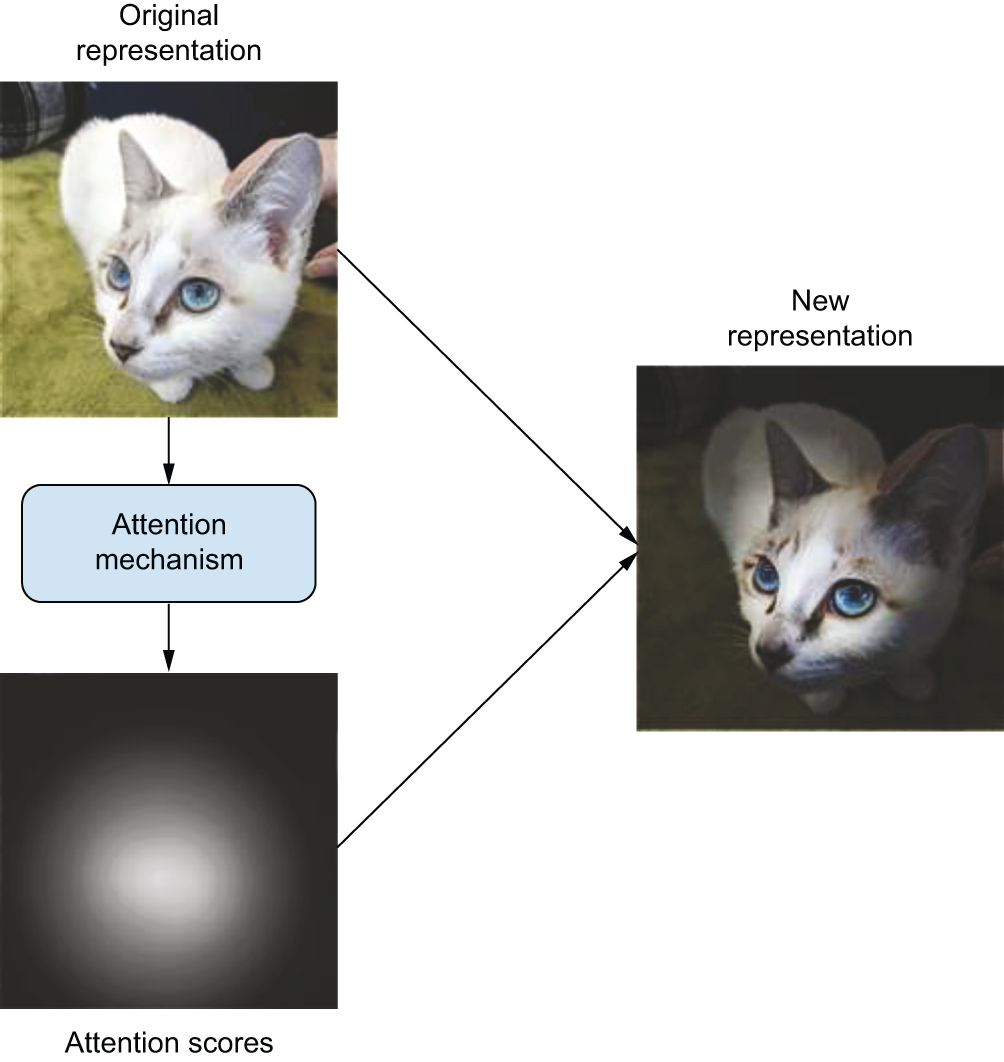
شکل 15.3: مفهوم کلی attention در یادگیری عمیق
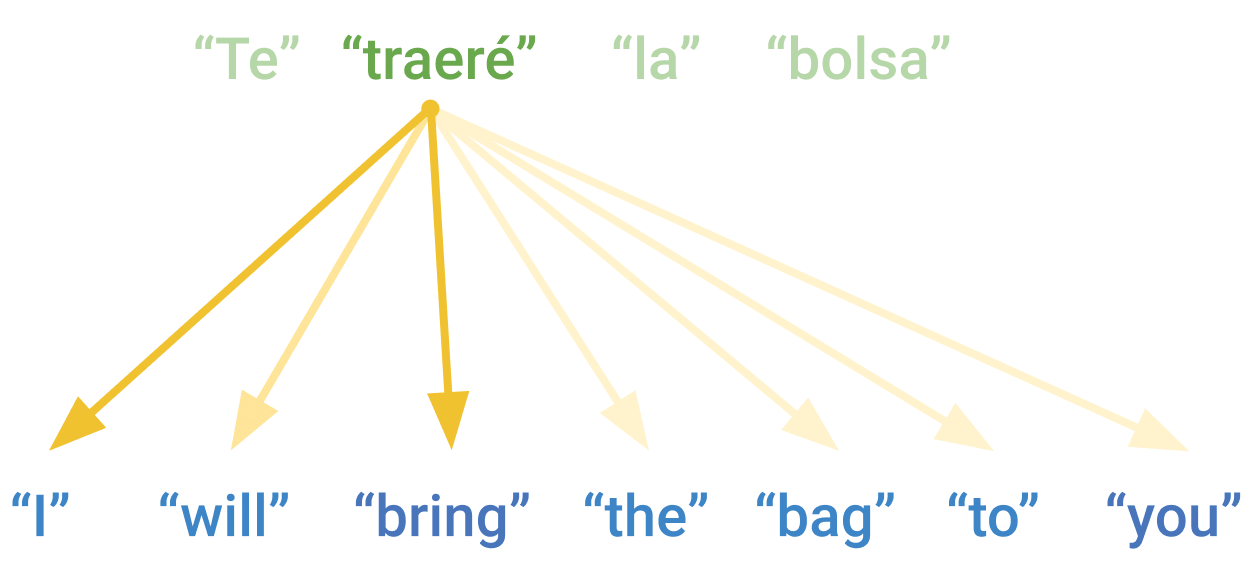
شکل 15.4: Attention یک امتیاز ارتباط به هر بردار اختصاص میدهد

شکل 15.5: وقتی هر دو target و source دنبالهاند، امتیازات attention یک ماتریس 2D هستند
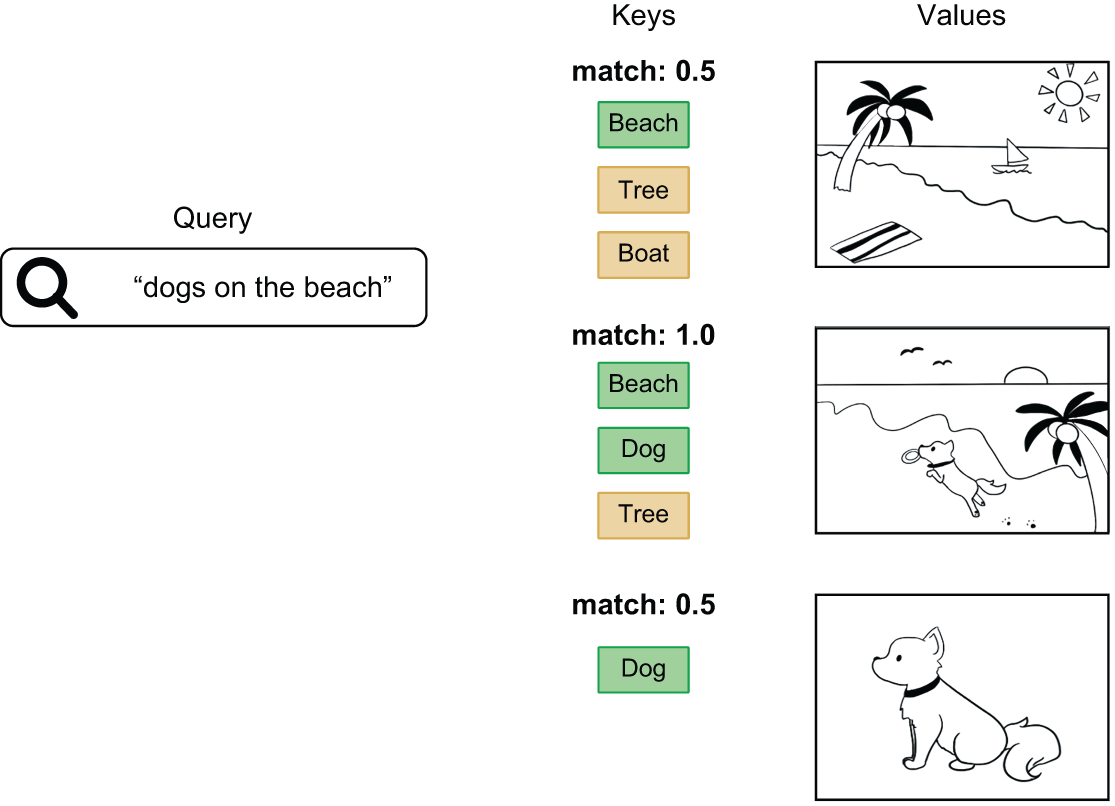
شکل 15.6: بازیابی تصاویر از یک پایگاه داده با query، key و value
شکل 15.7: Multi-headed attention
15.3.3 بلوک Encoder ترنسفورمر
class TransformerEncoder(keras.Layer):
def __init__(self, hidden_dim, intermediate_dim, num_heads):
super().__init__()
key_dim = hidden_dim // num_heads
# لایههای Self-attention
self.self_attention = layers.MultiHeadAttention(num_heads, key_dim)
self.self_attention_layernorm = layers.LayerNormalization()
# لایههای Feedforward
self.feed_forward_1 = layers.Dense(intermediate_dim, activation="relu")
self.feed_forward_2 = layers.Dense(hidden_dim)
self.feed_forward_layernorm = layers.LayerNormalization()
def call(self, source, source_mask):
# محاسبه Self-attention
residual = x = source
mask = source_mask[:, None, :]
x = self.self_attention(query=x, key=x, value=x, attention_mask=mask)
x = x + residual
x = self.self_attention_layernorm(x)
# محاسبه Feedforward
residual = x
x = self.feed_forward_1(x)
x = self.feed_forward_2(x)
x = x + residual
x = self.feed_forward_layernorm(x)
return x
لیست 15.14: یک بلوک encoder ترنسفورمر
⚠️ نکته مهم: LayerNormalization vs BatchNormalization
در ترنسفورمر از LayerNormalization استفاده میکنیم، نه BatchNormalization.
دلیل:
- BatchNorm: نرمالسازی روی محور batch → برای دادههای دنبالهای مناسب نیست
- LayerNorm: نرمالسازی مستقل برای هر دنباله → برای متن بهتر است
15.3.4 بلوک Decoder ترنسفورمر
class TransformerDecoder(keras.Layer):
def __init__(self, hidden_dim, intermediate_dim, num_heads):
super().__init__()
key_dim = hidden_dim // num_heads
# لایههای Self-attention
self.self_attention = layers.MultiHeadAttention(num_heads, key_dim)
self.self_attention_layernorm = layers.LayerNormalization()
# لایههای Cross-attention
self.cross_attention = layers.MultiHeadAttention(num_heads, key_dim)
self.cross_attention_layernorm = layers.LayerNormalization()
# لایههای Feedforward
self.feed_forward_1 = layers.Dense(intermediate_dim, activation="relu")
self.feed_forward_2 = layers.Dense(hidden_dim)
self.feed_forward_layernorm = layers.LayerNormalization()
def call(self, target, source, source_mask):
# محاسبه Self-attention
residual = x = target
x = self.self_attention(query=x, key=x, value=x, use_causal_mask=True)
x = x + residual
x = self.self_attention_layernorm(x)
# محاسبه Cross-attention
residual = x
mask = source_mask[:, None, :]
x = self.cross_attention(
query=x, key=source, value=source, attention_mask=mask
)
x = x + residual
x = self.cross_attention_layernorm(x)
# محاسبه Feedforward
residual = x
x = self.feed_forward_1(x)
x = self.feed_forward_2(x)
x = x + residual
x = self.feed_forward_layernorm(x)
return x
لیست 15.15: یک بلوک decoder ترنسفورمر
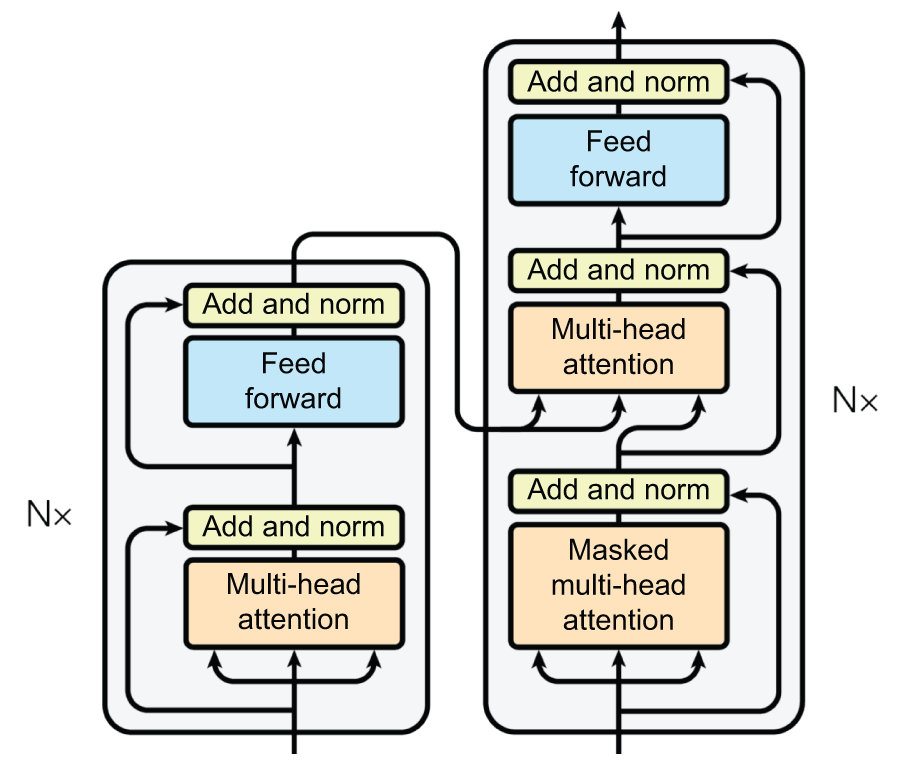
شکل 15.8: نمایش بصری محاسبات برای بلوکهای TransformerEncoder و TransformerDecoder
15.3.5 یادگیری دنباله به دنباله با ترنسفورمر
hidden_dim = 256
intermediate_dim = 2048
num_heads = 8
source = keras.Input(shape=(None,), dtype="int32", name="english")
x = layers.Embedding(vocab_size, hidden_dim)(source)
encoder_output = TransformerEncoder(hidden_dim, intermediate_dim, num_heads)(
source=x,
source_mask=source != 0,
)
target = keras.Input(shape=(None,), dtype="int32", name="spanish")
x = layers.Embedding(vocab_size, hidden_dim)(target)
x = TransformerDecoder(hidden_dim, intermediate_dim, num_heads)(
target=x,
source=encoder_output,
source_mask=source != 0,
)
x = layers.Dropout(0.5)(x)
target_predictions = layers.Dense(vocab_size, activation="softmax")(x)
transformer = keras.Model([source, target], target_predictions)
لیست 15.16: ساختن یک مدل ترنسفورمر
آموزش مدل:
transformer.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
weighted_metrics=["accuracy"],
)
transformer.fit(train_ds, epochs=15, validation_data=val_ds)
15.3.6 جاسازی اطلاعات موقعیتی
⚠️ چرا Positional Embedding ضروری است؟
مشکل: مکانیسم attention به ترتیب کلمات توجه ندارد! بدون positional embedding، این دو جمله یکسان پردازش میشوند:
- “سگ گربه را دید” →
- “گربه سگ را دید” →
راهحل: با اضافه کردن positional embedding، مدل میفهمد کلمه اول چیست و کلمه دوم چیست.
from keras import ops
class PositionalEmbedding(keras.Layer):
def __init__(self, sequence_length, input_dim, output_dim):
super().__init__()
self.token_embeddings = layers.Embedding(input_dim, output_dim)
self.position_embeddings = layers.Embedding(sequence_length, output_dim)
def call(self, inputs):
# موقعیتهای افزایشی [0, 1, 2...] را برای هر دنباله در batch محاسبه میکند
positions = ops.cumsum(ops.ones_like(inputs), axis=-1) - 1
embedded_tokens = self.token_embeddings(inputs)
embedded_positions = self.position_embeddings(positions)
return embedded_tokens + embedded_positions
لیست 15.17: یک لایه position embedding یادگیری شده
ترنسفورمر با positional embedding:
hidden_dim = 256
intermediate_dim = 2056
num_heads = 8
source = keras.Input(shape=(None,), dtype="int32", name="english")
x = PositionalEmbedding(sequence_length, vocab_size, hidden_dim)(source)
encoder_output = TransformerEncoder(hidden_dim, intermediate_dim, num_heads)(
source=x,
source_mask=source != 0,
)
target = keras.Input(shape=(None,), dtype="int32", name="spanish")
x = PositionalEmbedding(sequence_length, vocab_size, hidden_dim)(target)
x = TransformerDecoder(hidden_dim, intermediate_dim, num_heads)(
target=x,
source=encoder_output,
source_mask=source != 0,
)
x = layers.Dropout(0.5)(x)
target_predictions = layers.Dense(vocab_size, activation="softmax")(x)
transformer = keras.Model([source, target], target_predictions)
لیست 15.18: ساختن یک مدل ترنسفورمر با positional embeddings
آموزش:
transformer.compile(
optimizer="adam",
loss="sparse_categorical_crossentropy",
weighted_metrics=["accuracy"],
)
transformer.fit(train_ds, epochs=30, validation_data=val_ds)
تولید ترجمهها:
import numpy as np
spa_vocab = spanish_tokenizer.get_vocabulary()
spa_index_lookup = dict(zip(range(len(spa_vocab)), spa_vocab))
def generate_translation(input_sentence):
tokenized_input_sentence = english_tokenizer([input_sentence])
decoded_sentence = "[start]"
for i in range(sequence_length):
tokenized_target_sentence = spanish_tokenizer([decoded_sentence])
tokenized_target_sentence = tokenized_target_sentence[:, :-1]
inputs = [tokenized_input_sentence, tokenized_target_sentence]
next_token_predictions = transformer.predict(inputs, verbose=0)
sampled_token_index = np.argmax(next_token_predictions[0, i, :])
sampled_token = spa_index_lookup[sampled_token_index]
decoded_sentence += " " + sampled_token
if sampled_token == "[end]":
break
return decoded_sentence
test_eng_texts = [pair[0] for pair in test_pairs]
for _ in range(5):
input_sentence = random.choice(test_eng_texts)
print("-")
print(input_sentence)
print(generate_translation(input_sentence))
لیست 15.19: تولید ترجمهها با یک ترنسفورمر
15.4 طبقهبندی با یک ترنسفورمر پیشآموزشدیده
بعد از مقاله “Attention is all you need”، مردم شروع به توجه کردند که تا چه حد میتوان آموزش Transformer را مقیاسپذیر کرد، بهخصوص در مقایسه با مدلهایی که قبلاً وجود داشتند. همانطور که اشاره کردیم، یکی از مزایای بزرگ این بود که این مدل سریعتر از RNNها آموزش داده میشود. دیگر حلقهای در طول آموزش وجود ندارد، که همیشه هنگام کار با GPU یا TPU مطلوب است.
این معماری مدل همچنین بسیار دادهخواه است. در واقع در بخش قبل کمی با این موضوع آشنا شدیم. در حالی که مدل ترجمه RNN ما بعد از حدود 5 epoch در عملکرد اعتبارسنجی به سطح ثابتی رسید، مدل Transformer هنوز بعد از 30 epoch آموزش در حال بهبود امتیاز اعتبارسنجی خود بود.
این مشاهدات بسیاری را ترغیب کرد تا مقیاسپذیری Transformer را با داده، لایه و پارامترهای بیشتر امتحان کنند – با نتایج عالی. این امر باعث تغییر مشخصی در این حوزه به سمت مدلهای بزرگ پیشآموزشدیده شد که ممکن است آموزش آنها میلیونها دلار هزینه داشته باشد اما بهطور قابل توجهی در طیف گستردهای از مسائل در حوزه متن بهتر عمل میکنند.
برای آخرین مثال کدنویسی در بخش متن، به مسئله طبقهبندی متن IMDb خود باز خواهیم گشت، این بار با یک مدل Transformer پیشآموزشدیده.
15.4.1 پیشآموزش یک Encoder ترنسفورمر
یکی از اولین Transformerهای پیشآموزشدیده که در NLP محبوب شد، BERT نام داشت، که مخفف Bidirectional Encoder Representations from Transformers است. این مقاله و مدل یک سال بعد از “Attention Is All You Need” منتشر شدند. ساختار مدل دقیقاً همانند بخش رمزگذار Transformer ترجمهای بود که اخیراً ساختیم. این مدل رمزگذار دوطرفه است، به این معنی که هر موقعیت در توالی میتواند به موقعیتهای جلوتر و عقبتر خود توجه کند. این بدان معناست که مدل خوبی برای محاسبه یک نمایش غنی از متن ورودی است، اما مدلی نیست که برای اجرای تولید در یک حلقه طراحی شده باشد.
BERT در اندازههای بین 100 میلیون تا 300 میلیون پارامتر آموزش داده شد، بسیار بزرگتر از Transformer با اندازه 14 میلیون پارامتری که تازه آموزش دادیم. این به این معنی بود که مدل برای عملکرد خوب به دادههای آموزشی زیادی نیاز داشت. برای دستیابی به این هدف، نویسندگان از نوعی از راهاندازی کلاسیک مدلسازی زبانی به نام مدلسازی زبانی ماسکشده استفاده کردند. برای پیشآموزش مدل، یک توالی متن را میگیریم و حدود 15 درصد از توکنها را با یک توکن ویژه [MASK] جایگزین میکنیم. مدل سعی خواهد کرد در طول آموزش مقادیر توکنهای ماسکشده اصلی را پیشبینی کند. در حالی که مدل زبانی کلاسیک، که گاهی مدل زبانی علّی نامیده میشود، سعی در پیشبینی p(token|past tokens) دارد، مدل زبانی ماسکشده سعی در پیشبینی p(token|surrounding tokens) دارد.
این راهاندازی آموزشی بدون نظارت است. به هیچ برچسبی درباره متنی که وارد میکنید نیاز ندارید؛ برای هر توالی متنی، به راحتی میتوانید برخی توکنهای تصادفی را انتخاب کرده و آنها را ماسک کنید. این امر برای نویسندگان آسان کرد که مقدار زیادی داده متنی مورد نیاز برای آموزش مدلهای با این اندازه را پیدا کنند. عمدتاً آنها از ویکیپدیا بهعنوان منبع استفاده کردند.
استفاده از embeddingهای پیشآموزشدیده کلمات قبلاً هنگام انتشار BERT یک عمل رایج بود – خودمان این را در فصل قبل دیدیم. اما پیشآموزش یک Transformer کامل چیزی بسیار قدرتمندتر ارائه داد – توانایی محاسبه embedding کلمه برای یک کلمه در زمینه کلمات اطراف آن. و Transformer این امکان را با مقیاس و کیفیتی فراهم کرد که در آن زمان بیسابقه بود.
نویسندگان BERT این مدل را گرفتند، روی مقدار عظیمی از متن پیشآموزش دادند، و آن را تخصصی کردند تا به نتایج پیشرفته در چندین معیار NLP در آن زمان دست یابند. این نشاندهنده یک تغییر مشخص در این حوزه به سمت استفاده از مدلهای بسیار بزرگ و پیشآموزشدیده بود، که اغلب تنها با مقدار کمی فاینتیون همراه بود. بیایید این را امتحان کنیم.
داستان BERT
BERT (Bidirectional Encoder Representations from Transformers) یکی از اولین مدلهای پیشآموزشدیده موفق بود.
روش آموزش: Masked Language Modeling
- 15% از کلمات را با [MASK] پوشانده میشود
- مدل باید کلمات پوشانده شده را حدس بزند
- بدون نیاز به label → میتوان از هر متنی استفاده کرد!
15.4.2 بارگذاری یک ترنسفورمر پیشآموزشدیده
بهجای استفاده از BERT در اینجا، بیایید از یک مدل بعدی به نام RoBERTa استفاده کنیم، که مخفف Robustly Optimized BERT است. RoBERTa برخی سادهسازیهای جزئی را در معماری BERT انجام داد، اما مهمتر از همه از دادههای آموزشی بیشتری برای بهبود عملکرد استفاده کرد. BERT از 16 گیگابایت متن زبان انگلیسی، عمدتاً از ویکیپدیا، استفاده کرد. نویسندگان RoBERTa از 160 گیگابایت متن از سراسر وب استفاده کردند. تخمین زده میشود که آموزش RoBERTa در آن زمان چند صد هزار دلار هزینه داشته است. به دلیل این دادههای آموزشی اضافی، مدل برای تعداد پارامترهای کلی معادل بهطور قابل توجهی بهتر عمل میکند.
برای استفاده از یک مدل پیشآموزشدیده به چند چیز نیاز خواهیم داشت:
- یک توکنایزر متناظر – که با خود مدل پیشآموزشدیده استفاده میشود. هر متنی باید به همان روشی که در طول پیشآموزش بود توکنایز شود. اگر کلمات نقدهای IMDb ما به شاخصهای توکن متفاوتی نسبت به زمان پیشآموزش نگاشت شوند، نمیتوانیم از نمایشهای آموختهشده هر توکن در مدل استفاده کنیم.
- یک معماری مدل متناظر – برای استفاده از مدل پیشآموزشدیده، باید دقیقاً ریاضیات استفادهشده در داخل مدل برای پیشآموزش را بازسازی کنیم.
- وزنهای پیشآموزشدیده – این وزنها با آموزش مدل به مدت حدود یک روز روی 1024 GPU و میلیاردها کلمه ورودی ایجاد شدند.
بازسازی کد توکنایزر و معماری خودمان چندان سخت نخواهد بود. داخلیهای مدل تقریباً دقیقاً با TransformerEncoder که قبلاً ساختیم مطابقت دارند. با این حال، تطبیق یک پیادهسازی مدل یک فرآیند زمانبر است، و همانطور که قبلاً در این کتاب انجام دادیم، میتوانیم بهجای آن از کتابخانه KerasHub برای دسترسی به پیادهسازیهای مدل پیشآموزشدیده برای Keras استفاده کنیم.
بیایید از KerasHub برای بارگذاری یک توکنایزر و مدل RoBERTa استفاده کنیم. میتوانیم از سازنده ویژه from_preset() برای بارگذاری وزنها، پیکربندی و داراییهای توکنایزر یک مدل پیشآموزشدیده از دیسک استفاده کنیم. مدل پایه RoBERTa را بارگذاری خواهیم کرد، که کوچکترین checkpoint از چند checkpoint پیشآموزشدیده منتشرشده با مقاله RoBERTa است.
ما از RoBERTa استفاده خواهیم کرد:
import keras_hub
tokenizer = keras_hub.models.Tokenizer.from_preset("roberta_base_en")
backbone = keras_hub.models.Backbone.from_preset("roberta_base_en")
لیست 15.20: بارگذاری مدل پیشآموزشدیده RoBERTa با KerasHub
تفاوت RoBERTa با BERT
| ویژگی | BERT | RoBERTa |
|---|---|---|
| حجم داده آموزشی | 16 GB | 160 GB |
| منبع داده | ویکیپدیا + کتاب | وب کامل |
| عملکرد | خوب | بهتر |
15.4.3 پیشپردازش نقدهای فیلم IMDb
from keras.utils import text_dataset_from_directory
batch_size = 16
train_ds = text_dataset_from_directory(train_dir, batch_size=batch_size)
val_ds = text_dataset_from_directory(val_dir, batch_size=batch_size)
test_ds = text_dataset_from_directory(test_dir, batch_size=batch_size)
def preprocess(text, label):
packer = keras_hub.layers.StartEndPacker(
sequence_length=512,
start_value=tokenizer.start_token_id,
end_value=tokenizer.end_token_id,
pad_value=tokenizer.pad_token_id,
return_padding_mask=True,
)
token_ids, padding_mask = packer(tokenizer(text))
return {"token_ids": token_ids, "padding_mask": padding_mask}, label
preprocessed_train_ds = train_ds.map(preprocess)
preprocessed_val_ds = val_ds.map(preprocess)
preprocessed_test_ds = test_ds.map(preprocess)
لیست 15.21: پیشپردازش نقدهای فیلم IMDb با tokenizer RoBERTa
15.4.4 تنظیم دقیق (Fine-tuning) یک ترنسفورمر پیشآموزشدیده
قبل از اینکه backbone خود را برای پیشبینی نقدهای فیلم تنظیم دقیق کنیم، باید آن را بهروزرسانی کنیم تا یک برچسب طبقهبندی دودویی خروجی دهد. backbone یک توالی کامل با شکل (batch_size, sequence_length, 768) خروجی میدهد، که در آن هر بردار 768 بعدی نشاندهنده یک کلمه ورودی در زمینه کلمات اطراف آن است. قبل از پیشبینی یک برچسب، باید این توالی را به یک بردار واحد به ازای هر نمونه متراکم کنیم.
یک گزینه این است که mean pooling یا max pooling را در کل توالی انجام دهیم و میانگین همه بردارهای توکن را محاسبه کنیم. آنچه کمی بهتر کار میکند صرفاً استفاده از نمایش توکن اول بهعنوان مقدار pooled شده است. این به دلیل ماهیت attention در مدل ما است – موقعیت اول در لایه رمزگذار نهایی قادر خواهد بود به تمام موقعیتهای دیگر در توالی توجه کند و اطلاعات را از آنها استخراج کند. بنابراین بهجای اینکه اطلاعات را با چیزی درشت مانند محاسبه میانگین pool کنیم، attention به ما اجازه میدهد اطلاعات را بهصورت زمینهای در سراسر توالی pool کنیم.
حالا بیایید یک سر طبقهبندی (classification head) به backbone خود اضافه کنیم. همچنین یک projection نهایی Dense با یک غیرخطیبودگی قبل از تولید یک پیشبینی خروجی اضافه خواهیم کرد.
inputs = backbone.input x = backbone(inputs) # از نمایش مخفی token اول استفاده میکند x = x[:, 0, :] x = layers.Dropout(0.1)(x) x = layers.Dense(768, activation="relu")(x) x = layers.Dropout(0.1)(x) outputs = layers.Dense(1, activation="sigmoid")(x) classifier = keras.Model(inputs, outputs)
لیست 15.22: گسترش مدل پایه RoBERTa برای طبقهبندی
classifier.compile(
optimizer=keras.optimizers.Adam(5e-5),
loss="binary_crossentropy",
metrics=["accuracy"],
)
classifier.fit(
preprocessed_train_ds,
validation_data=preprocessed_val_ds,
)
لیست 15.23: آموزش مدل طبقهبندی RoBERTa
تنها در یک epoch از آموزش، مدل ما به 93% رسید، که بهبود قابل توجهی نسبت به سقف 90% است که در فصل قبل به آن رسیدیم. البته این مدلی بسیار پرهزینهتر برای استفاده نسبت به طبقهبند bigram سادهای است که قبلاً ساختیم، اما مزایای واضحی برای استفاده از چنین مدل بزرگی وجود دارد. و همه اینها با اندازه کوچکتر مدل RoBERTa است. با استفاده از مدل بزرگتر 300 میلیون پارامتری، میتوانیم به دقت بیش از 95% دست یابیم.
ارزیابی مدل آموزشدیده:
>>> classifier.evaluate(preprocessed_test_ds) [0.168127179145813, 0.9366399645805359]
در فقط یک epoch از آموزش، مدل ما به 93% رسید، یک پیشرفت قابل توجه نسبت به سقف 90% که در فصل قبل داشتیم.
15.5 چه چیزی ترنسفورمر را مؤثر میکند؟
ارتباط با Word2Vec
ترنسفورمر و Word2Vec (از سال 2013) اصل مشترکی دارند:
“کلماتی که با هم ظاهر میشوند، در فضای embedding به هم نزدیک میشوند”
تفاوت اصلی:
- Word2Vec: یک لایه ساده، فضای embedding ثابت
- Transformer: چندین لایه، فضاهای embedding تدریجی و پویا
Attention یک مکانیسم برای یادگیری یک فضای embedding جدید token است. ترنسفورمرها دو ویژگی حیاتی دارند:
- فضاهای embedding یادگیری شده، از نظر معنایی پیوسته هستند – یعنی حرکت کمی در یک فضای embedding فقط معنای انسانی tokenهای مربوطه را کمی تغییر میدهد.
- فضاهای embedding یادگیری شده، از نظر معنایی درونیاب هستند – یعنی گرفتن نقطه میانی بین دو نقطه در یک فضای embedding، نقطهای را تولید میکند که “معنای میانی” بین tokenهای مربوطه را نشان میدهد.
ترنسفورمر = پایگاه داده با ویژگیهای خاص
شباهت به پایگاه داده:
- اطلاعات را ذخیره میکند
- با query میتوان آنها را بازیابی کرد
تفاوتها:
- پیوستگی: به جای رکوردهای مجزا، فضای برداری پیوسته دارد
- برنامهها: علاوه بر داده، “برنامههای برداری” پیچیده نیز ذخیره میکند
15.6 خلاصه
✨ نکات کلیدی فصل
- مدل زبانی: یادگیری p(token|past tokens) برای تولید متن
- Seq2Seq: encoder + decoder برای ترجمه و تبدیل دنبالهها
- Attention: مکانیسم انتخابی برای دسترسی به اطلاعات مرتبط
- Transformer: attention + feedforward، بدون نیاز به RNN
- Positional Embedding: برای حفظ اطلاعات ترتیب در دنباله
- Pre-training + Fine-tuning: کلید موفقیت مدلهای بزرگ
قدمهای بعدی
حالا که با ترنسفورمر آشنا شدید:
- کدهای ریپوی transformer را اجرا کنید
- با hyperparameter های مختلف آزمایش کنید
- یک dataset ترجمه دیگر (مثلاً انگلیسی-فارسی) را امتحان کنید (دیتاست انگلیسی-فارسی شناسا)
- مدلهای پیشآموزشدیده دیگر مانند GPT را بررسی کنید
منابع استفاده شده برای نگارش این فصل
- Vaswani et al., “Attention Is All You Need” (2017), https://arxiv.org/abs/1706.03762
- Devlin et al., “BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding” (2019), https://arxiv.org/abs/1810.04805
- Liu et al., “RoBERTa: A Robustly Optimized BERT Pretraining Approach” (2019), https://arxiv.org/abs/1907.11692
منبع اصلی: Deep Learning with Python, Third Edition – Chapter 15
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 1

دیدگاهتان را بنویسید