هوش مصنوعی تفسیرپذیر و توضیح پذیر

تکنیکهای تفسیرپذیری (interpretability techniques) به کشف چگونگی پیشبینیهای مدلهای یادگیری ماشین کمک میکنند. با آشکار کردن اینکه چگونه ویژگیهای مختلف به پیشبینیها کمک میکنند (یا کمک نمیکنند)، تکنیکهای تفسیرپذیری میتوانند به شما کمک کنند تا تأیید کنید که یک مدل یادگیری ماشین از شواهد مناسب برای پیشبینیها استفاده میکند و تعصبات (biases) موجود در مدل خود را که در طول آموزش قابل مشاهده نبودند، پیدا کنید. برخی از مدلهای یادگیری ماشین، مانند رگرسیون خطی (linear regression)، درختهای تصمیم (decision trees) و مدلهای جمعی مولد (generative additive models) ذاتاً تفسیرپذیر هستند. با این حال، تفسیرپذیری اغلب به قیمت قدرت و دقت تمام میشود، همانطور که در شکل ۱ نشان داده شده است.

شکل ۱. تعادل بین عملکرد (performance) و تفسیرپذیری برای چندین الگوریتم محبوب یادگیری ماشین.
تفسیرپذیری در مقابل توضیحپذیری
هوش مصنوعی توضیحپذیر (Explainable AI) یا به اختصار XAI یک حوزه در حال ظهور است که در آن اصطلاحات مرتبط نزدیک به هم تفسیرپذیری و توضیحپذیری اغلب به صورت متقابل استفاده میشوند. با این حال، تفسیرپذیری (interpretability) و توضیحپذیری متفاوت هستند. توضیحپذیری به توضیح رفتار یک مدل یادگیری ماشین به زبان انسانی اشاره دارد، بدون اینکه لزوماً به درک مکانیزمهای درونی مدل بپردازد. توضیحپذیری همچنین میتواند به عنوان تفسیرپذیری مستقل از مدل (model-agnostic interpretability) در نظر گرفته شود.
برای مهندسان، یکی از رویکردها برای توضیح رفتار یک سیستم، استفاده از اصول اولیه (first principles) است. یک مدل بر اساس اصول اولیه دارای معنای فیزیکی واضح و قابل توضیح است و رفتار آن میتواند پارامترسازی (parameterized) شود. این نوع مدل به عنوان “جعبه سفید” (white box) شناخته میشود. رفتار مدلهای یادگیری ماشین بیشتر “مبهم” (opaque) است.
مدلهای یادگیری ماشین از نظر پیچیدگی (complexity)، شهود (intuitiveness) در نمایندگی دانش (knowledge representation) و در نتیجه، دشواری در درک کامل چگونگی کارکرد آنها متفاوت هستند. مدلهای یادگیری ماشین میتوانند “جعبه خاکستری” (gray box) باشند، که در این صورت میتوانید تکنیکهای تفسیرپذیری را برای درک مکانیزمهای درونی آنها به کار ببرید، یا “جعبه سیاه” (black box) باشند، که در این صورت میتوانید تکنیکهای توضیحپذیری (یا تفسیرپذیری مستقل از مدل) را برای درک رفتار آنها به کار ببرید. مدلهای یادگیری عمیق (deep learning models) معمولاً جعبه سیاه هستند.

تکنیکهای تفسیرپذیری Global و Local
تفسیرپذیری معمولاً در دو سطح اعمال میشود:
- روشهای Global : این روشهای تفسیرپذیری نمای کلی از متغیرهای تأثیرگذار در مدل را بر اساس دادههای ورودی و خروجی پیشبینی شده ارائه میدهند.
- روشهای Local : این روشهای تفسیرپذیری توضیحی از یک نتیجه پیشبینی خاص ارائه میدهند.
شکل ۳ تفاوت بین دامنه Local و Global تفسیرپذیری را نشان میدهد. همچنین میتوانید تفسیرپذیری را به گروههایی در دادههای خود اعمال کنید و به نتایجی در سطح گروه برسید، مانند اینکه چرا یک گروه از محصولات تولید شده به عنوان معیوب طبقهبندی شدهاند.
چرا تفسیرپذیری مهم است
مهندسان و دانشمندان به دلایل اصلی زیر به تفسیرپذیری مدلها نیاز دارند:
- اشکالزدایی (Debugging): درک اینکه پیشبینیها در کجا یا چرا اشتباه میشوند. اجرای سناریوهای “چه میشود اگر” میتواند به بهبود robustness (قوت) مدل و حذف تعصبات (bias) کمک کند.
- راهنماها (Guidelines): مدلهای جعبه سیاه (black-box) یا جعبه خاکستری (gray-box) ممکن است با بهترین شیوههای صنعتی (industry best practices) مغایرت داشته باشند.
- مقررات (Regulations): برخی از مقررات دولتی نیاز به تفسیرپذیری برای کاربردهای حساس، مانند مالی (finance)، بهداشت عمومی (public health) و حمل و نقل (transportation) دارند.
تفسیرپذیری مدل به این نگرانیها پاسخ میدهد و اعتماد به مدلها را در شرایطی که توضیحات برای پیشبینیها مهم هستند، مانند مقایسه نتایج بین مدلهای رقیب، یا در مواردی که تفسیرپذیری بهعنوان یک الزام قانونی ضروری است، افزایش میدهد.
کاربردهایی که در آن تفسیرپذیری مهم است
ابزارهای تفسیرپذیری به شما کمک میکنند تا درک کنید چرا یک مدل یادگیری ماشین پیشبینیهایی را که انجام میدهد، میسازد. تفسیرپذیری احتمالاً به طور فزایندهای مرتبط خواهد شد زیرا نهادهای نظارتی و حرفهای به کار بر روی چارچوبی برای صدور گواهینامه هوش مصنوعی (AI) برای کاربردهای حساس ادامه میدهند، مانند:
- سیستمهای رانندگی خودکار (Automated Driving Systems)
- دستگاههای پزشکی (Medical Devices)
- مالی محاسباتی (Computational Finance)
ابزارهای تفسیرپذیری
برخی از تکنیکهای محبوب تفسیرپذیری محبوب در زیر آمده است:
-
توضیحات مدل قابل تفسیر محلی و مستقل از مدل (LIME): از LIME برای تقریب یک مدل پیچیده در همسایگی پیشبینی مورد نظر با یک مدل ساده و قابل تفسیر، مانند یک مدل خطی یا درخت تصمیم استفاده کنید. سپس میتوانید از مدل سادهتر به عنوان یک نماینده برای توضیح اینکه مدل اصلی (پیچیده) چگونه کار میکند، استفاده کنید. شکل ۴ سه مرحله اصلی اعمال LIME را نشان میدهد.
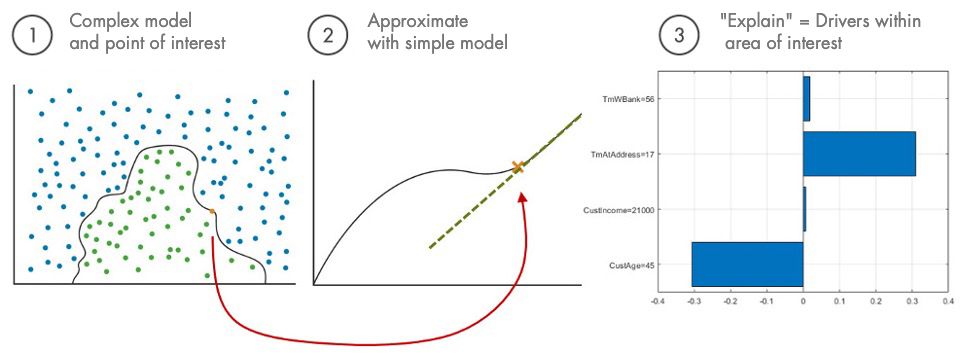
-
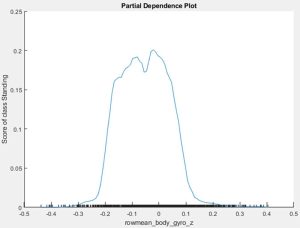
نمودارهای وابستگی جزئی (PDP) و انتظار شرطی فردی (ICE): با این روشها، تأثیر یک یا دو پیشبین (predictor) را بر پیشبینی کلی با میانگینگیری خروجی مدل بر روی تمام مقادیر ممکن ویژگیها بررسی میکنید. شکل ۵ یک نمودار وابستگی جزئی را نشان میدهد که با استفاده از تابع plotPartialDependence تولید شده است.
به طور دقیق، یک نمودار وابستگی جزئی نشان میدهد که برخی از دامنهها در مقدار یک پیشبین با احتمالهای خاصی برای پیشبینی مرتبط هستند؛ این برای ایجاد یک رابطه علی (causal relationship) کافی نیست. با این حال، اگر یک روش تفسیرپذیری محلی مانند LIME نشان دهد که پیشبین به طور قابل توجهی بر پیشبینی تأثیر گذاشته است (در یک ناحیه مورد نظر)، میتوانید به توضیحی برسید که چرا یک مدل به روشی خاص در آن ناحیه محلی رفتار کرده است.
- مقادیر شاپلی (Shapley Values): این تکنیک توضیح میدهد که هر پیشبین چقدر به یک پیشبینی کمک میکند با محاسبه انحراف یک پیشبینی مورد نظر از میانگین. این روش به ویژه در صنعت مالی (finance) محبوب است زیرا از نظریه بازیها (game theory) به عنوان پایه نظری خود مشتق شده و الزامات قانونی برای ارائه توضیحات کامل را برآورده میکند: مجموع مقادیر شاپلی برای تمام ویژگیها معادل کل انحراف پیشبینی از میانگین است. تابع شاپلی مقادیر شاپلی را برای یک نقطه مورد نظر محاسبه میکند.
ارزیابی تمام ترکیبهای ویژگیها معمولاً زمانبر است. بنابراین، مقادیر شاپلی معمولاً با استفاده از شبیهسازی مونت کارلو (Monte Carlo simulation) در عمل تقریب زده میشوند.
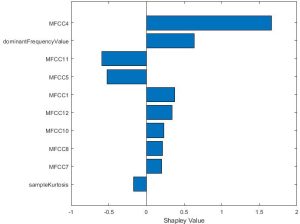
شکل ۶ نشان میدهد که در زمینه پیشبینی آریتمی قلب (heart arrhythmia) نزدیک به نمونه مورد نظر، MFCC4 تأثیر مثبت قوی بر پیشبینی “غیرطبیعی” (abnormal) داشت، در حالی که MFCC11 و MFCC5 به سمت آن پیشبینی تمایل داشتند، یعنی به سمت یک قلب “طبیعی” (normal).
- برآورد اهمیت پیشبینها با استفاده از جابجایی (Permutation): متلب همچنین از اهمیت پیشبینهای جابجا شده برای جنگلهای تصادفی (random forests) پشتیبانی میکند. این رویکرد تأثیر تغییرات در مقادیر پیشبین بر خطای پیشبینی مدل را به عنوان نشانهای از اهمیت پیشبین در نظر میگیرد. این تابع مقادیر یک پیشبین را در دادههای آزمایشی یا آموزشی جابجا میکند و اندازه تغییرات ناشی در خطا را مشاهده میکند.
تقسیر پذیری در شبکه های عصبی گرافی
شبکههای عصبی گرافی (Graph Neural Networks – GNNs) ابزاری قدرتمند برای یادگیری ماشین بر روی گرافها هستند. GNNها اطلاعات ویژگیهای گرهها را با ساختار گراف ترکیب میکنند و با ارسال پیامهای عصبی بهصورت بازگشتی در امتداد لبههای گراف ورودی، این ترکیب را انجام میدهند. با این حال، ترکیب همزمان ساختار گراف و اطلاعات ویژگیها منجر به مدلهای پیچیدهای میشود و توضیح پیشبینیهای انجام شده توسط GNNها همچنان یک چالش حلنشده باقی مانده است.
GNN Explainer یک ابزار عمومی برای توضیح پیشبینیهای انجام شده توسط شبکههای عصبی گراف (Graph Neural Networks – GNNs) است. این ابزار بهویژه برای درک و تفسیر نحوه عملکرد GNNs طراحی شده است، که به دلیل پیچیدگی ساختار گراف و ویژگیهای متغیر، توضیح پیشبینیهای آنها میتواند چالشبرانگیز باشد.
ویژگیها و عملکرد GNN Explainer
-
توضیحات مبتنی بر زیرگراف: GNN Explainer توضیحات را بهصورت یک زیرگراف غنی از کل گرافی که GNN روی آن آموزش دیده است، ارائه میدهد. این زیرگراف بهگونهای انتخاب میشود که حداکثر اطلاعات مشترک با پیشبینی GNN را داشته باشد.
- ماسک ویژگیها: علاوه بر زیرگراف، GNN Explainer همچنین یک ماسک ویژگی (feature mask) یاد میگیرد که ویژگیهای غیرمهم گرهها را فیلتر میکند. این به این معناست که میتوان فهمید کدام ویژگیها در پیشبینی نهایی تأثیرگذار بودهاند.
- روشهای مختلف GNN: GNN Explainer میتواند بر روی انواع مختلف مدلهای GNN، از جمله GCN (Graph Convolutional Networks)، GraphSAGE، GAT (Graph Attention Networks) و SGC (Simplified Graph Convolution) اعمال شود.
- کاربردهای متنوع: این ابزار میتواند برای انواع مختلف وظایف یادگیری ماشین، از جمله طبقهبندی گرهها، طبقهبندی گراف و پیشبینی لینک، مورد استفاده قرار گیرد.
- تحلیل و بررسی: GNN Explainer به محققان و مهندسان کمک میکند تا درک بهتری از نحوه عملکرد مدلهای GNN داشته باشند و بتوانند نقاط قوت و ضعف آنها را شناسایی کنند. این ابزار به ویژه در زمینههایی که شفافیت و قابلیت توضیح پیشبینیها مهم است، مانند بهداشت عمومی، مالی و سیستمهای خودران، کاربرد دارد.
در کل میتوان گفت GNN Explainer بهعنوان یک ابزار تفسیرپذیری برای شبکههای عصبی گراف، به محققان و مهندسان کمک میکند تا پیشبینیهای GNN را بهتر درک کنند و به آنها امکان میدهد تا بهطور مؤثرتری با دادههای پیچیده کار کنند. با استفاده از این ابزار، میتوان به شفافیت بیشتری در تصمیمگیریهای مبتنی بر داده دست یافت و به شناسایی تعصبات (biases) و نقاط ضعف مدلها پرداخت.
برای اطلاعات بیشتر و دسترسی به کد و مستندات، میتوانید به وبسایت GNN Explainer مراجعه کنید.
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

دیدگاهتان را بنویسید