۴۰ معیار برتر مدلهای زبان بزرگ (LLM) با پشتوانه تحقیقاتی و موارد استفاده آنها

با توسعه روزافزون هوش مصنوعی مولد (GenAI)، تمرکز ویژهای بر آزمایش و ارزیابی آن وجود دارد که منجر به انتشار چندین معیار (بنچمارک) برای مدلهای زبان بزرگ (LLM) شده است. هر یک از این معیارها، قابلیتهای متفاوتی از LLM را میسنجند – اما آیا برای ارزیابی کامل عملکرد در دنیای واقعی کافی هستند؟
این وبلاگ به بررسی برخی از محبوبترین بنچمارکهای LLM برای ارزیابی مدلهای زبانی برتر مانند GPT 4o، Gemma 3 میپردازد. علاوه بر این، ما در مورد استفاده از LLMها در سناریوهای عملی و اینکه آیا این معیارها برای پیادهسازیهای پیچیده مانند سیستمهای عاملمحور (agentic systems) کافی هستند، بحث خواهیم کرد.
فهرست مطالب
- معیارهای ارزیابی: هوش مصنوعی سنتی در مقابل هوش مصنوعی مولد
- ۴۰ بنچمارک LLM
- درک بنچمارکهای LLM
- آیا بنچمارکهای LLM کافی هستند؟
- ارزیابی عاملمحور: فراتر از LLMها
- جمعبندی نهایی
معیارهای ارزیابی: هوش مصنوعی سنتی در مقابل هوش مصنوعی مولد
الگوریتمهای هوش مصنوعی سنتی، مانند الگوریتمهایی که برای طبقهبندی، رگرسیون و پیشبینی سریهای زمانی استفاده میشوند، معمولاً سیستمهای قطعی (deterministic) هستند. این بدان معناست که برای مجموعهای مشخص از ورودیها، انتظار میرود مدل یک خروجی ثابت تولید کند. در حالی که پیشبینیهای مدل ممکن است بسته به آموزش آن از واقعیت پایه (ground truth) مورد انتظار منحرف شود، خروجی هنگام ارائه با همان ترکیب ورودی، پایدار باقی خواهد ماند. معیارهای ارزیابی استاندارد، مانند دقت (accuracy)، صحت (precision) و ریشه میانگین مربعات خطا (RMSE)، انحراف مدل از برچسبهای واقعیت پایه را برای ارزیابی عملکرد آن کمیسازی میکنند. این معیارها یک سنجش ساده، ساختاریافته و عینی از اثربخشی هوش مصنوعی ارائه میدهند.
با این حال، این مورد برای مدلهای هوش مصنوعی مولد صادق نیست. این مدلهای مولد غیرقطعی هستند، یعنی یک خروجی متوالی تولید میکنند و هر عنصر در توالی به صورت احتمالی تعیین میشود. هیچ واقعیت پایه ملموسی برای مقایسه خروجی مدل وجود ندارد، که ارزیابی آنها را دشوار میکند. مدلهای هوش مصنوعی مولد در سناریوهای مختلفی مانند مکالمه عمومی، حل مسئله منطقی و چتباتهای آموزنده استفاده میشوند. عملکرد آنها بر اساس تواناییشان در پردازش ورودی و هرگونه زمینه (context) موجود و تولید پاسخی مرتبط با سناریو ارزیابی میشود. چندین معیار استاندارد برای این منظور ایجاد شده است. هر یک از اینها جنبه منحصربهفردی از مدل را هدف قرار داده و یک امتیاز ارزیابی ارائه میدهد که برای قضاوت در مورد عملکرد مدل استفاده میشود. بیایید این معیارها را با جزئیات بیشتری بررسی کنیم.
۴۰ بنچمارک LLM
در ادامه به ۴۰ معیار رایج LLM و هدف هر یکپرداخته شده است.
| بنچمارک | خلاصه | دسته |
|---|---|---|
| MMLU (درک زبان چندوظیفهای عظیم) | یک آزمون پرسش و پاسخ چندگزینهای شامل ۵۷ موضوع که دانش عمومی گسترده و استدلال را ارزیابی میکند و موضوعاتی از ریاضی و تاریخ گرفته تا حقوق را پوشش میدهد. | استدلال (دانش) |
| ARC-AGI (مجموعه دادههای انتزاع و استدلال) | مجموعهای از پازلهای بصری انتزاعی (ARC فرانسوا شوله) که برای اندازهگیری پیشرفت به سوی هوش مصنوعی عمومی (AGI) با آزمایش تشخیص الگو و استدلال قیاسی فراتر از یادگیری brute-force در نظر گرفته شده است. | استدلال (قیاس) |
| تعمیم موضوعی (Thematic Generalization) | آزمایش میکند که آیا یک LLM میتواند یک «تم» یا قانون پنهان را از چند اعلان نمونه و نمونه نقض استنباط کند، که نیازمند تعمیم از دادههای محدود است. | استدلال (یادگیری مفهوم) |
| توجه گمراهکننده (Misguided Attention) | مجموعهای از مسائل استدلالی که با اطلاعات گمراهکننده یا نامربوط طراحی شدهاند تا توانایی LLM را در تمرکز بر سرنخهای صحیح و جلوگیری از فریب خوردن به چالش بکشند. | استدلال (استحکام) |
| WeirdML | وظایف نامتعارف به سبک یادگیری ماشین (مانند شناسایی تصاویر درهمریخته، مسائل عجیب ML) را ارائه میدهد که نیازمند استدلال دقیق و مبتنی بر درک واقعی از سوی LLMها است. | استدلال (نامتعارف) |
| GPQA-Diamond | یک معیار پرسش و پاسخ «ضد گوگل» در سطح تحصیلات تکمیلی شامل حدود ۲۰۰ سوال نوشته شده توسط متخصصان در فیزیک، زیستشناسی و شیمی – مسائل علمی بسیار چالشبرانگیز که برای مقاومت در برابر حفظ کردن طراحی شدهاند. | استدلال (علمی) |
| SimpleQA | یک معیار پرسش و پاسخ واقعی از OpenAI با سوالات کوتاه و حقیقتجو، که توانایی LLM را در ارائه پاسخهای دقیق و مختصر به پرسشهای سرراست آزمایش میکند. | استدلال (واقعی) |
| TrackingAI – IQ Bench | یک آزمون هوش برای هوش مصنوعی با استفاده از سوالات هوش انسانی بیان شده به صورت کلامی (مانند پازلهای منسا) برای تخمین توانایی شناختی مدلها؛ نحوه مدیریت مدلها با منطق، تطبیق الگو و حل مسئله معمول در آزمونهای هوش را اندازهگیری میکند. | استدلال (شناختی) |
| آخرین آزمون بشریت (Humanity’s Last Exam – HLE) | یک معیار فوقالعاده دشوار جدید که توسط متخصصان حوزه («آخرین آزمون» برای هوش مصنوعی) با سوالات دقیق در ریاضیات، علوم و غیره تنظیم شده است، جایی که مدلهای برتر فعلی نمرهای کمتر از ۱۰٪ کسب میکنند – به عنوان یک مانع نهایی در نظر گرفته شده که عبور از آن نشاندهنده نزدیک شدن به AGI است. | استدلال (پیشرفته) |
| MathArena | پلتفرمی که از مسائل جدید مسابقات ریاضی و المپیادها برای ارزیابی دقیق استدلال ریاضی LLMها استفاده میکند؛ برای جلوگیری از آلودگی دادهها (contamination) با آزمایش مدلها بلافاصله پس از انتشار مسائل مسابقه طراحی شده است. | استدلال (ریاضی) |
| MGSM (ریاضیات دبستان چندزبانه) | نسخهای چندزبانه از مسائل کلمهای ریاضیات دبستان (GSM8K ترجمه شده به ۱۰ زبان) برای آزمایش استدلال ریاضی در زبانهای مختلف. (توجه: این معیار اشباع شده در نظر گرفته میشود زیرا بسیاری از مدلها در حال حاضر به عملکرد بالایی در زنجیره تفکر دست یافتهاند) | استدلال (ریاضی) |
| BBH (Big-Bench Hard) | زیرمجموعهای از ۲۳ وظیفه بهخصوص چالشبرانگیز از مجموعه BIG-Bench که مدلهای قبلی (مانند GPT-3) در آنها شکست خوردند، برای ارزیابی استدلال ترکیبی پیشرفته و تعمیم خارج از توزیع استفاده میشود. (اشباع شده در نظر گرفته میشود.) | استدلال (وظایف سخت مختلط) |
| DROP (استدلال گسسته روی پاراگرافها) | یک معیار درک مطلب شامل ۹۶ هزار سوال خصمانه (adversarial) که نیازمند استدلال گسسته (مانند محاسبات، مرتبسازی تاریخ) روی متون است – مدلها باید خواندن را با استدلال نمادین ترکیب کنند. | استدلال (خواندن و ریاضی) |
| Context-Arena | یک جدول امتیازات (leaderboard) متمرکز بر درک زمینه طولانی: عملکرد LLM را در وظایفی مانند پاسخ به سوالات از اسناد طولانی و تفکیک ارجاع چندنوبتی (multi-turn reference resolution) (مانند آزمون MRCR OpenAI برای یادآوری زمینه طولانی) به تصویر میکشد. | استدلال (زمینه طولانی) |
| Fiction-Live Bench (نوشتن خلاقانه داستان کوتاه) | یک معیار نوشتن خلاقانه که از مدلها میخواهد داستانهای کوتاهی بنویسند که حدود ۱۰ عنصر مشخص مورد نیاز (شخصیتها، اشیاء، مضامین و غیره) را در خود جای دهند و ارزیابی میکند که یک LLM چقدر انسجام روایی را حفظ کرده و در عین حال به محدودیتهای محتوایی پایبند است. | نوشتن طولانی (خلاقانه) |
| AidanBench | یک معیار تولید ایده با پایان باز که در آن مدلها به سوالات خلاقانه با بیشترین تعداد ایدههای منحصربهفرد و منسجم ممکن پاسخ میدهند – فروپاشی مُد (mode collapse) و پاسخهای تکراری را جریمه میکند، و عملاً هیچ سقفی برای امتیاز خروجیهای واقعاً بدیع وجود ندارد. | تفکر خلاق |
| EQ-Bench (معیار هوش هیجانی) | درک LLM از استدلال هیجانی و اجتماعی را از طریق وظایفی مانند گفتگوی همدلانه یا نوشتن خلاقانه با ظرافت هیجانی ارزیابی میکند، که توسط یک داور LLM بر اساس جنبههای هوش هیجانی امتیازدهی میشود. | نوشتن طولانی (IQ هیجانی) |
| HumanEval | معیار کدنویسی OpenAI شامل ۱۶۴ مسئله پایتون دستنویس که در آن مدل باید کد صحیح را برای یک مشخصات معین تولید کند، برای اندازهگیری صحت عملکردی در برنامهنویسی پایه استفاده میشود. | کدنویسی |
| Aider Polyglot Coding | یک معیار ویرایش کد از Aider: شامل ۲۲۵ چالش کدنویسی از Exercism در زبانهای C++، Go، Java، JavaScript، Python و Rust، که توانایی LLM را در دنبال کردن دستورالعملها برای تغییر یا نوشتن کد به چندین زبان اندازهگیری میکند. | کدنویسی (چندزبانه) |
| BigCodeBench | یک معیار بزرگ شامل ۱۱۴۰ وظیفه برنامهنویسی متنوع و واقعگرایانه (با فراخوانی توابع پیچیده و مشخصات) برای ارزیابی قابلیتهای واقعی کدنویسی فراتر از مسائل الگوریتمی ساده. | کدنویسی |
| WebDev Arena | یک چالش کدنویسی به سبک آرنا که در آن دو LLM برای ساخت یک برنامه وب کاربردی از روی همان اعلان (prompt) با یکدیگر رقابت میکنند و امکان ارزیابی مهارتهای عملی توسعه وب از طریق مقایسههای زوجی انسانی را فراهم میکند. | کدنویسی (توسعه وب) |
| SciCode | یک معیار کدنویسی پژوهشمحور با ۳۳۸ مسئله کدنویسی برگرفته از حوزههای علمی (ریاضیات، فیزیک، شیمی، زیستشناسی) – آزمایش میکند که آیا مدلها میتوانند برای حل مسائل علمی چالشبرانگیز در سطح دکترا کد بنویسند. | کدنویسی (علمی) |
| METR (وظایف طولانی) | یک چارچوب ارزیابی که پیشنهاد میکند عملکرد هوش مصنوعی را بر اساس طول وظیفه اندازهگیری کند: طولانیترین و پیچیدهترین وظایفی را که یک عامل هوش مصنوعی میتواند به طور مستقل تکمیل کند، به عنوان نمایندهای از رشد قابلیت کلی بررسی میکند. | رفتار عاملمحور (افق طولانی) |
| RE-Bench (مهندسی پژوهش) | معیاری از METR که عاملهای هوش مصنوعی پیشرفته را در مقابل مهندسان یادگیری ماشین انسانی در وظایف پیچیده پژوهش و مهندسی ML (مانند بازتولید آزمایشها) قرار میدهد و ارزیابی میکند که هوش مصنوعی چقدر به خودکارسازی کارهای تحقیق و توسعه ML نزدیک است. | رفتار عاملمحور (وظایف تحقیق و توسعه) |
| PaperBench | معیار OpenAI که ارزیابی میکند آیا عاملهای هوش مصنوعی میتوانند تحقیقات پیشرفته هوش مصنوعی را تکرار کنند – به عاملها مقالات ML اخیر (مانند ICML 2024) داده میشود و وظیفه دارند نتایج را از ابتدا مجدداً پیادهسازی و بازتولید کنند، که برنامهریزی، کدنویسی و اجرای آزمایش را آزمایش میکند. | رفتار عاملمحور (اتوماسیون پژوهش) |
| SWE-Lancer | معیاری شامل ۱۴۰۳ وظیفه واقعی مهندسی نرمافزار فریلنسری (از Upwork، به ارزش کل ۱ میلیون دلار) برای ارزیابی اینکه آیا LLMهای پیشرفته میتوانند کارهای کدنویسی سرتاسری را تکمیل کنند – عملکرد هوش مصنوعی را مستقیماً به درآمدهای بالقوه نگاشت میکند. | رفتار عاملمحور (کدنویسی در دنیای واقعی) |
| MLE-Bench | معیار مهندس یادگیری ماشین OpenAI با ۷۵ وظیفه ML در دنیای واقعی (مانند مسابقات Kaggle) – ارزیابی میکند که یک عامل هوش مصنوعی چقدر میتواند گردش کار سرتاسری مسائل ML، از جمله مدیریت داده، آموزش و تحلیل را انجام دهد. | رفتار عاملمحور (AutoML) |
| SWE-Bench | معیاری از پرینستون/OpenAI شامل ۲۲۹۴ مسئله GitHub (با پایگاههای کد مرتبط) – مدلها باید به عنوان عاملهای نرمافزاری عمل کنند که یک مخزن (repo) را میخوانند، سپس برای حل مسئله وصلههایی (patches) مینویسند و تمام تستها را با موفقیت پشت سر میگذارند؛ این معیار به دقت گردش کار توسعهدهندگان واقعی را تقلید میکند. | رفتار عاملمحور (نگهداری کد) |
| Tau-Bench (ابزار-عامل-کاربر) | معیار Sierra AI برای عاملهای تعاملی در سناریوهای واقعگرایانه – عامل با یک کاربر شبیهسازی شده گفتگو میکند و از ابزارها برای انجام وظایف در حوزههایی مانند خردهفروشی (لغو سفارشها و غیره) یا خطوط هوایی استفاده میکند، که استفاده چندنوبتی از ابزار و برنامهریزی پویا را آزمایش میکند. | رفتار عاملمحور (استفاده از ابزار) |
| XLANG Agent | یک چارچوب باز و جدول امتیازات (HKU) برای عاملهای چندزبانه – توانایی عاملها را در انجام وظایفی که شامل چندین زبان هستند ارزیابی میکند و تطبیقپذیری و استدلال عامل را در موانع زبانی منعکس میکند. | رفتار عاملمحور (عاملهای چندزبانه) |
| Balrog-AI | معیاری برای استدلال عاملمحور در بازیها: LLMها (و VLMها) را با بازی یک ماجراجویی متنی یا تکمیل اهداف بازی با افق طولانی به چالش میکشد و برنامهریزی، حافظه و تصمیمگیری را در یک محیط تعاملی ارزیابی میکند. | رفتار عاملمحور (بازی) |
| Snake-Bench | یک چالش LLM-به-عنوان-بازیکن-مار که در آن مدلها یک مار را در یک بازی شبیهسازی شده مار کنترل میکنند؛ چندین «مار» LLM با هم رقابت میکنند و توانایی مدل را در استراتژیپردازی و واکنش در یک محیط نوبتی با پیامدهای بلندمدت آزمایش میکنند. | رفتار عاملمحور (بازی) |
| SmolAgents LLM | یک جدول امتیازات HuggingFace که وظایف عامل خودمختار در مقیاس کوچک (زیرمجموعهای کوچک از معیار عامل GAIA و برخی وظایف ریاضی) را ارزیابی میکند – رتبهبندی میکند که چگونه مدلهای متنباز و بسته هنگام استقرار به عنوان عاملهای حداقلی عمل میکنند. | رفتار عاملمحور (عاملها) |
| MMMU (درک چندوجهی چندرشتهای عظیم) | یک معیار چندوجهی جامع با مسائل سطح دانشگاهی که شامل متن و تصویر (نمودارها، چارتها و غیره) است و از مدلها میخواهد اطلاعات بصری را با دانش موضوعی پیشرفته و استدلال ادغام کنند. | چندوجهی (استدلال) |
| MC-Bench (معیار Minecraft) | یک معیار تعاملی که در آن LLMها ساختارهای Minecraft یا راهحلهایی تولید میکنند که از طریق مقایسههای انسانی (مانند Minecraft Arena) ارزیابی میشوند؛ استدلال فضایی و خلاقیت را در یک جعبه شنی (sandbox) بصری آزمایش میکند و ارزیابی را پویاتر و با پایان بازتر میکند. | چندوجهی (تعاملی) |
| SEAL by Scale (جدول امتیازات چندچالشی) | جدول امتیازات ارزیابی چندچالشی Scale AI که طیف گستردهای از وظایف را در یک رتبهبندی واحد جمعآوری میکند – مقایسهای جامع از مدلها در چالشهای متنوع ارائه میدهد (بخش «MultiChallenge» قابلیت کلی را به نمایش میگذارد). | فرامعیارسنجی (چندوظیفهای) |
| LMArena (Chatbot Arena) | یک جدول امتیازات به سبک Elo با جمعسپاری که در آن مدلها در مکالمات چت زوجی (که توسط کاربران قضاوت میشود) دوئل میکنند؛ کیفیت/ترجیحات عمومی را با رقابت مدلها در گفتگوی با پایان باز آشکار میکند. | فرامعیارسنجی (ترجیح انسانی) |
| LiveBench | یک مجموعه ارزیابی همیشهسبز که ماهانه با دادههای آزمایشی تازه و بدون آلودگی در ۱۸ وظیفه (ریاضی، کدنویسی، استدلال، زبان، پیروی از دستورالعمل، تحلیل داده) بهروز میشود. یک معیار بهروز برای پیگیری پیشرفت مدل در طول زمان ارائه میدهد. | فرامعیارسنجی (چندوظیفهای) |
| OpenCompass | یک پلتفرم ارزیابی LLM متنباز که از بیش از ۱۰۰ مجموعه داده پشتیبانی میکند. به عنوان یک چارچوب و جدول امتیازات یکپارچه برای محک زدن طیف گستردهای از مدلها (GPT-4، Llama، Mistral و غیره) در بسیاری از وظایف عمل میکند و امکان مقایسه سیببهسیب مدلها را فراهم میآورد. | فرامعیارسنجی (پلتفرم) |
| Dubesor LLM | یک جمعآورنده بنچمارک شخصی اما گسترده (به نام «rosebud» به صورت معکوس): مقایسه مداوم یک فرد از مدلهای مختلف در دهها وظیفه سفارشی، که در یک امتیاز وزنی واحد برای هر مدل ترکیب شده است. | فرامعیارسنجی (جمعآورنده) |
درک بنچمارکهای LLM
برای درک بهتر برخی از این معیارها، در ادامه جزئیات بیشتری در مورد چند مورد از محبوبترین آنها که برای ارزیابی LLM استفاده میشوند، ارائه شده است.
بنچمارکهای درک دانش عمومی و زبان
معیارهای رایج طراحی شده برای آزمایش درک زبان طبیعی یک مدل عبارتند از:
۱. بنچمارک MMLU
بنچمارک درک زبان چندوظیفهای عظیم (MMLU) یک بنچمارک همهمنظوره است که برای ارزیابی مدل در برابر موضوعات متنوع طراحی شده است. این بنچمارک شامل سوالات چندگزینهای است که ۵۷ موضوع از جمله علوم، فناوری، مهندسی و ریاضیات (STEM)، علوم اجتماعی، علوم انسانی و غیره را پوشش میدهد. دشواری سوالات از سطح ابتدایی تا پیشرفته حرفهای متغیر است.
در اینجا یک نمونه سوال از مجموعه داده مربوط به اخلاق تجاری آورده شده است:
_______ مانند بیتکوین به طور فزایندهای در حال تبدیل شدن به جریان اصلی هستند و مجموعهای کامل از پیامدهای اخلاقی مرتبط را به همراه دارند، به عنوان مثال، آنها ______ و ______تر هستند. با این حال، از آنها برای مشارکت در _______ نیز استفاده شده است.
- الف. رمزارزها، گران، امن، جرایم مالی
- ب. ارز سنتی، ارزان، ناامن، کمکهای خیریه
- ج. رمزارزها، ارزان، امن، جرایم مالی
- د. ارز سنتی، گران، ناامن، کمکهای خیریه
توجه: MMLU به طور گستردهای اشباع شده در نظر گرفته میشود و معمولاً معیار مناسبی برای مقایسه مدلهای امروزی نیست. با این حال، با توجه به کاربرد رایج و تاریخی آن، هنوز هم ارزش آشنایی دارد.
۲. چالش استدلال AI2 (ARC)
چالش استدلال AI2 (ARC) مجموعهای از ۷۷۸۷ سوال علوم در سطح دبستان است. این مجموعه داده به دو بخش آسان و چالشی تقسیم شده است، که بخش چالشی شامل سوالاتی است که هم توسط یک الگوریتم مبتنی بر بازیابی و هم یک الگوریتم وقوع کلمه به اشتباه پاسخ داده شدهاند.
در اینجا یک نمونه سوال از مجموعه داده آورده شده است:
سوال: جورج میخواهد با مالیدن دستانش به سرعت آنها را گرم کند. کدام سطح پوست بیشترین گرما را تولید میکند؟
- الف. کف دست خشک
- ب. کف دست خیس
- ج. کف دست پوشیده از روغن
- د. کف دست پوشیده از لوسیون
۳. SuperGLUE
SuperGLUE یک نسخه پیشرفته از بنچمارک اصلی درک عمومی زبان (GLU) است. این بنچمارک شامل ۸ وظیفه درک زبان است. SuperGLUE شامل وظایف متنوعی مانند درک مطلب، پیامد متنی (textual entailment)، پاسخ به پرسش و تفکیک ضمیر (pronoun resolution) است که آن را به یک معیار جامعتر از GLUE اصلی تبدیل میکند.
یک نمونه وظیفه از این مجموعه داده:
- فرض اولیه (Premise): سگ گربه را تعقیب کرد.
- فرضیه (Hypothesis): گربه از دست سگ فرار میکرد.
- برچسب (Label): پیامد (Entailment)
بنچمارکهای کدنویسی
۴. HumanEval
معیار ارزیابی دستی (Hand-written Evaluation Benchmark) مجموعهای از چالشهای برنامهنویسی است که برای سنجش تواناییهای کدنویسی یک مدل طراحی شدهاند. این مجموعه برای نخستینبار در مقالهی «Evaluating Large Language Model Trained on Code» معرفی شد و شامل 164 چالش برنامهنویسی بهصورت دستی نوشتهشده است.
این چالشها بهصورت دستی تهیه شدهاند زیرا اکثر مدلهای زبانی بزرگ (LLMها) پیشتر با دادههایی که از مخازن GitHub جمعآوری شدهاند آموزش دیدهاند. هر مسئله شامل امضای تابع (function signature)، توضیح عملکرد (docstring)، بدنهی تابع (body)، و چندین تست واحد (unit test) است؛ بهطور میانگین ۷٫۷ تست برای هر مسئله در نظر گرفته شده است.
در ادامه یک نمونه از مسائل موجود در این مجموعه ارائه شده است:
def solution(lst):
"""Given a non-empty list of integers, return the sum of all of the odd elements
that are in even positions.
Examples
solution([5, 8, 7, 1])=12
solution([3, 3, 3,3, 3]) =9
solution([30, 13, 24, 321]) =0
"""
LLMs output: return sum(lst[i] for i in range(0,len(lst)) if i % 2 == 0 and lst[i] % 2 == 1)
۵. CodeXGLUE
مجموعه داده بنچمارک CodeXGLUE برای آزمایش درک و تولید کد توسط LLMها ساخته شده است. این مجموعه شامل ۱۰ وظیفه در ۱۴ مجموعه داده و یک پلتفرم برای ارزیابی و مقایسه مدلها است. وظایف را میتوان به ۴ دسته بالاتر تقسیم کرد:
- کد به کد: این شامل ترجمه کد، تکمیل کد، اشکالزدایی و تعمیر کد است.
- متن به کد: این شامل تولید کد از توضیحات زبان طبیعی و تجزیه و تحلیل معنایی بین کد و توضیحات متنی است.
- کد به متن: این شامل خلاصهسازی و توضیح کد است.
- متن به متن: این شامل ترجمه مستندات کد از یک زبان طبیعی به زبان دیگر است.
در اینجا مثالی از وظیفه ترجمه کد آورده شده است:

یک مثال در مجموعه داده ترجمه کد، وظیفه ترجمه کد از بنچمارک CodeXGLUE – منبع
۶. SWE-Bench
بنچمارک SWE-Bench شامل ۲۲۹۴ مسئله واقعی مهندسی نرمافزار است که از GitHub استخراج شدهاند. وظایف شامل درک نظرات از درخواستهای pull در GitHub و ایجاد تغییرات مرتبط در پایگاه کد است. LLM وظیفه دارد مسئله را شناسایی و حل کرده و تستها را اجرا کند تا از صحت عملکرد همه چیز اطمینان حاصل شود.
بنچمارکهای استدلال
در اینجا چند معیار آورده شده است که توانایی مدل را در انجام استدلال منطقی برای رسیدن به نتیجه آزمایش میکنند.
۷. GSM8k
GSM8k شامل ۸.۵ هزار مسئله ریاضی در سطح دبستان و از نظر زبانی متنوع است. این مسائل به زبان طبیعی بیان شدهاند، که درک آنها را برای مدلهای هوش مصنوعی چالشبرانگیز میکند. این معیار توانایی LLMها را در تجزیه مسئله به زبان طبیعی، تشکیل یک زنجیره تفکر و رسیدن به راهحل آزمایش میکند.
در اینجا یک نمونه مسئله از مجموعه داده آورده شده است:
مسئله: بث در یک هفته ۴ دسته ۲ دوجینی کلوچه میپزد. اگر این کلوچهها به طور مساوی بین ۱۶ نفر تقسیم شوند، هر نفر چند کلوچه مصرف میکند؟
راهحل: بث ۴ * ۲ = ۸ دوجین کلوچه میپزد. در هر دوجین ۱۲ کلوچه وجود دارد، بنابراین او ۱۲ * ۸ = ۹۶ کلوچه درست میکند. او ۹۶ کلوچه را به طور مساوی بین ۱۶ نفر تقسیم میکند، بنابراین هر نفر ۹۶ / ۱۶ = ۶ کلوچه میخورد.
پاسخ نهایی: ۶
۸. ارزیابی استدلال خلاف واقع (CRASS)
CRASS یک طرح آزمایشی جدید با استفاده از به اصطلاح شرطیهای خلاف واقع و به طور دقیقتر، شرطیهای خلاف واقع سوالی ارائه میدهد. یک گزاره خلاف واقع، عبارتی است که سناریویی را ارائه میدهد که ممکن بود اتفاق بیفتد اما نیفتاده است. اینها همچنین معمولاً به عنوان سناریوهای «چه میشد اگر» شناخته میشوند. معیارهای CRASS شامل چندین سناریو از این دست با واقعیتهای جایگزین هستند و درک مدل را در برابر اینها آزمایش میکنند.
یک نمونه سناریو از مجموعه داده این است:
زنی آتشی را میبیند. چه اتفاقی میافتاد اگر زن به آتش سوخت میرساند؟
آتش بزرگتر میشد.
آتش کوچکتر میشد.
این امکانپذیر نیست.
۹. Big-Bench Hard (BBH)
معیار اصلی Big-Bench شامل ۲۰۰ وظیفه در حوزههایی مانند محاسبات عددی و استدلال منطقی، دانش عمومی (commonsense) و برنامهنویسی است. با این حال، بیشتر مدلهای زبانی بزرگ امروزی در بسیاری از این وظایف عملکردی بهتر از ارزیابهای انسانی دارند. «Big-Bench Hard» زیرمجموعهای از نسخه اصلی است که شامل ۲۳ وظیفه چالشبرانگیز میشود که در آنها هیچ مدل زبانی عملکردی بهتر از انسان نداشته است. این وظایف تواناییهای استدلالی مدلها و توسعهی زنجیره استدلال (chain-of-thought) را به چالش میکشند.
یک نمونه سؤال از این بنچمارک به شکل زیر است:
سؤال: امروز، «هانا» به زمین فوتبال رفت. در چه بازهی زمانی ممکن است او رفته باشد؟
ما میدانیم که:
هانا ساعت ۵ صبح بیدار شد. […] زمین فوتبال بعد از ساعت ۶ عصر بسته شد. […]
گزینهها:
A. از ۳ بعدازظهر تا ۵ بعدازظهر
B. از ۵ بعدازظهر تا ۶ بعدازظهر
C. از ۱۱ صبح تا ۱ بعدازظهر
D. از ۱ بعدازظهر تا ۳ بعدازظهر
آیا بنچمارکهای LLM کافی هستند؟
بنچمارکهای مربوط به مدلهای زبانی بزرگ (LLM) ابزار بسیار خوبی برای ارزیابی عملکرد این مدلها در سناریوهای دنیای واقعی هستند، اما سؤال اصلی همچنان باقیست: آیا این بنچمارکها برای یک ارزیابی جامع کافی هستند؟ بنچمارکهایی که تاکنون به آنها اشاره شد، تنها بخش کوچکی از مجموعهی موجود هستند و چارچوبهای دیگری نیز برای وظایف متنوعتری وجود دارد.
علاوه بر این، هیچ مدل زبانی خاصی در تمام ارزیابیها برتری ندارد، چرا که هر مدل با هدف خاصی آموزش دیده است. به عنوان مثال، مدل GPT-4.5 که بهتازگی عرضه شده، در درک پایهای زبان عملکردی بهتر از مدل قدیمیتر o3-mini دارد، اما در وظایف استدلال پیچیده ضعیفتر عمل میکند، چرا که بهصورت اختصاصی برای استدلال زنجیرهوار (Chain-of-Thought یا CoT) آموزش ندیده است.
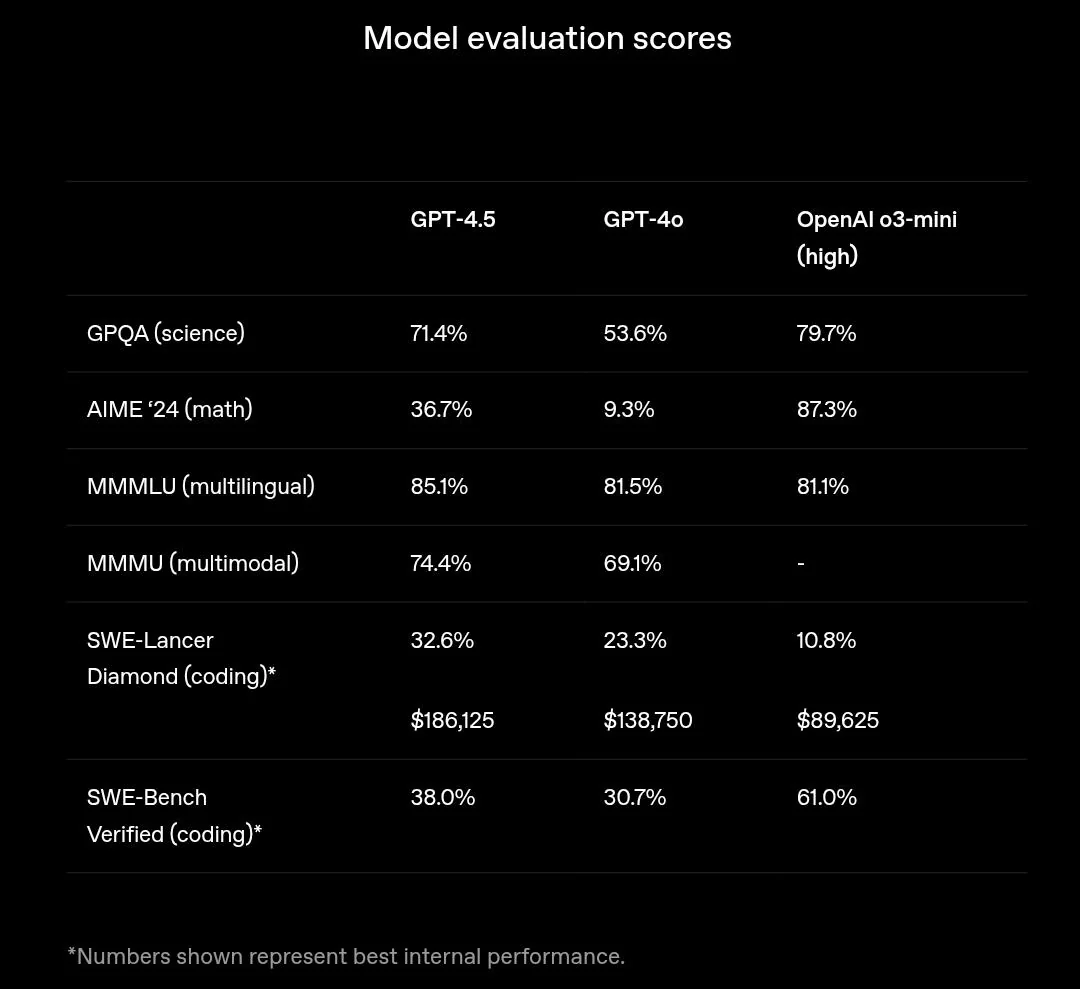
نمرات ارزیابی برای GPT-4.5 در مقایسه با GPT-4o و o3-mini – منبع
با اینکه هر بنچمارک عملکرد مدلهای زبانی بزرگ (LLM) را در چند سناریوی خاص اندازهگیری میکند، اما این اعداد تصویر کاملی از عملکرد کلی مدل ارائه نمیدهند. یک مدل ممکن است در بنچمارکهای مختلف—even در یک حوزه خاص—عملکرد متفاوتی داشته باشد، چرا که هر بنچمارک مجموعهای متفاوت از وظایف را شامل میشود.
این موضوع نشان میدهد که بیشتر بنچمارکها برای ارزیابیهایی خاص و نسبتاً آسان طراحی شدهاند. نمونهای شاخص از یک چارچوب ارزیابی جامع، بنچمارک Humanity’s Last Exam (HLE) است که یکی از معدود چارچوبهایی است که بهمنظور ایجاد یک معیار واحد برای سنجش عملکرد مدل طراحی شده است. HLE شامل ۲۷۰۰ وظیفه بسیار چالشبرانگیز و چندوجهی در حوزههای مختلف دانشگاهی است.
نتایج بهدستآمده از ارزیابی مدلهای پیشرفته بر اساس HLE نشان میدهد که مدلهای فعلی LLM هنوز با کاستیهای جدی مواجهاند و همچنین بنچمارکهای متداول برای ارزیابی دقیق و همهجانبه در دنیای امروز کافی نیستند.
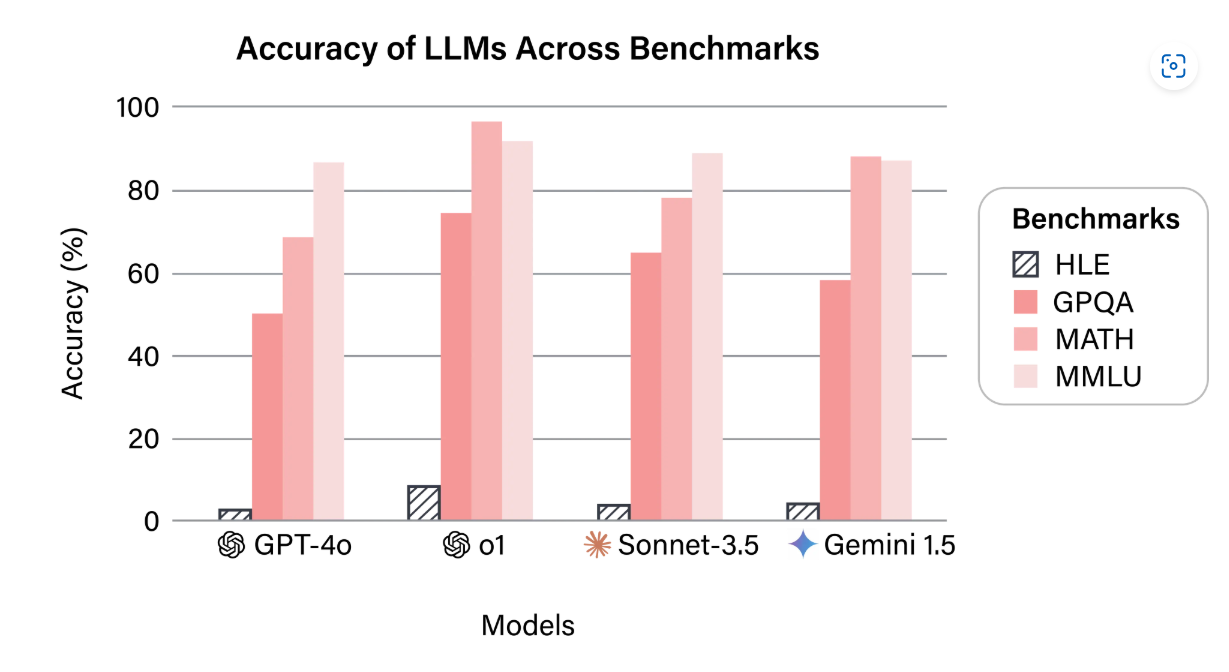
بنچمارکهایی که عملکرد ضعیف مدلهای زبانی بزرگ (LLMها) را در آزمون HLE نشان میدهند – منبع
یکی دیگر از عوامل مهمی که باید در نظر گرفت این است که سیستمهای مدرن اکنون به سمت پیادهسازیهای عاملمحور (agentic) حرکت میکنند.
بنچمارکهای سنتی ممکن است پاسخ تولیدی مدل را ارزیابی کنند، اما عملکرد آن را در چارچوب یک سیستم خودکار و عاملمحور مورد سنجش قرار نمیدهند.
ارزیابی عاملمحور: فراتر از LLMها
یک سیستم عاملمحور (agentic system) فراتر از درک زبان و تولید داده عمل میکند. چنین سیستمی شامل خواندن جریانهای داده در زمان واقعی، تعامل با محیط، و تجزیهی وظایف برای رسیدن به یک هدف مشخص است.
عاملهای هوش مصنوعی (AI agents) بهسرعت در حال محبوب شدن هستند و موارد استفادهی جالب و کاربردی زیادی از آنها در صنایعی مانند پشتیبانی مشتری، تجارت الکترونیک و امور مالی پیدا شده است. این عاملها حتی در موقعیتهای غیرمعمول ولی سرگرمکنندهای هم به کار رفتهاند—برای مثال، مدل Claude Sonnet 3.7 از شرکت Anthropic بازی Pokemon Red را روی کنسول قدیمی Game Boy انجام داده است!
نمرات بنچمارکهای سنتی، عملکرد مدلها را در سناریوهای واقعی و قابل اجرا در دنیای واقعی نشان نمیدهند. سیستمهای عاملمحور عملیاتی نیاز به بنچمارکهای تخصصیتری مانند AgentBench و t-bench دارند تا بتوانند توانمندیهای عامل را بهدرستی بسنجند.
این بنچمارکها تعامل مدلهای زبانی با ماژولهایی مانند پایگاهدادهها و گرافهای دانش را ارزیابی کرده و عملکرد آنها را در پلتفرمها و سیستمعاملهای مختلف بررسی میکنند.
علاوه بر این، عاملهای هوش مصنوعی باید از نظر زمان انجام وظیفه نسبت به انسانها نیز مورد سنجش قرار گیرند.
مطالعات نشان میدهد که هرچند افق زمانی برای انجام خودکار وظایف در حال رشد نمایی است، سیستمهای عاملمحور هنوز از نیروی انسانی عقبتر هستند و برای خودکارسازی کامل کارهای روزمره به زمان بیشتری نیاز دارند.
جمعبندی نهایی
عصر هوش مصنوعی مولد (GenAI) فرارسیده، و بهنظر میرسد که ماندگار خواهد بود. مدلهای مولد بهسرعت در حال ادغام در جریانهای کاری روزمره هستند، کارهای تکراری را خودکار کرده و بهرهوری را بهبود میبخشند. اما با افزایش این میزان از پذیرش، ارزیابی دقیق سیستمهای مبتنی بر مدلهای زبانی بزرگ (LLM) و عملکرد آنها در سناریوهای واقعی و چالشبرانگیز، امری حیاتی است.
بنچمارکهای مختلفی برای ارزیابی LLMها طراحی شدهاند که هر یک عملکرد مدل را در سناریوهای متفاوتی میسنجند. برخی بر توانایی مدل در استدلال منطقی تمرکز دارند، در حالی که برخی دیگر بر توانایی حل مسائل برنامهنویسی و تولید کد تأکید میکنند.
با این حال، با عرضه مدلهای جدیدتر و هوشمندتر، حتی محبوبترین بنچمارکها نیز برای ارزیابی کامل مدلها ناکافی بهنظر میرسند.
بنچمارکهایی مانند HLE نشان میدهند که حتی مدلهای پیشرفتهی امروزی نیز در شرایط دشوار میتوانند ضعفهایی از خود نشان دهند.
علاوه بر این، با افزایش استقبال از هوش مصنوعی عاملمحور (agentic AI)، نیاز به روشهای ارزیابی جدیدتر و مقاومتری برای سیستمهای سرتاسری (end-to-end) داریم. بنچمارکهای سنتی توانایی مدل در درک محیط یا رسیدن به یک هدف مشخص را مورد ارزیابی قرار نمیدهند.
با پیشرفت GenAI، معیارهای ارزیابی نیز باید تکامل یابند تا پاسخگوی نیازهای عملی و فزاینده باشند. استانداردهای جدیدی باید تعریف شوند تا اطمینان حاصل شود که پذیرش هوش مصنوعی با ایمنی و کارایی همراه باشد.
بیشتر بخوانیم:
شورتکاتها در مدلهای زبانی بزرگ (LLM): چالشی پنهان در ارزیابی هوش مصنوعی
منبع: https://arize.com/blog/llm-benchmarks-mmlu-codexglue-gsm8k
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

دیدگاهتان را بنویسید