هرس مدل یا Model Pruning در یادگیری عمیق

مقدمه ای بر هرس مدل در هوش مصنوعی
در دنیای پرشتاب هوش مصنوعی، مدلهای یادگیری عمیق به طور فزایندهای پیچیده و حجیم میشوند. این مدلها، اگرچه دقت بالایی دارند، اما اغلب به منابع محاسباتی زیادی برای آموزش و استقرار نیاز دارند. هرس مدل (Model Pruning) یک تکنیک بهینهسازی است که با حذف اتصالات غیرضروری در شبکه عصبی، اندازه مدل را کاهش داده و سرعت استنتاج را افزایش میدهد. در این مقاله، به بررسی جامع هرس مدل، انواع آن، مزایا و نحوه پیادهسازی آن با استفاده از TensorFlow و Keras میپردازیم.
این پست به بخشهای زیر تقسیم شده است:
- مفهوم “عدم اهمیت” در توابع و شبکههای عصبی
- هرس یک شبکه عصبی آموزشدیده
- قطعه کدهای نمونه و مقایسه عملکرد بین مدلهای مختلف
- تکنیکهای نوین هرس
هرس مدل چیست؟
هرس مدل فرایندی است که در آن اتصالات (وزنها) یا نورونهای کماهمیت در یک شبکه عصبی حذف میشوند. این فرایند باعث کاهش پیچیدگی مدل و افزایش کارایی آن میشود. در واقع، هرس مدل به دنبال حذف بخشهایی از مدل است که کمترین تأثیر را بر عملکرد کلی دارند.
مفهوم “عدم اهمیت” (non-significant) در توابع
شبکههای عصبی، تقریبزنندههای توابع هستند. ما آنها را آموزش میدهیم تا توابعی را یاد بگیرند که بازنماییهای زیربنایی دادههای ورودی را به دست آورند. وزنها و بایاسهای یک شبکه عصبی به عنوان پارامترهای (قابل یادگیری) آن شناخته میشوند. اغلب، وزنها به عنوان ضرایب تابعی که در حال یادگیری است، در نظر گرفته میشوند.
تابع زیر را در نظر بگیرید:
f(x) = x + 5x
در تابع بالا، دو عبارت در سمت راست داریم: x و x
در اینجا، ضرایب در نسخههای مختلف تابع اصلی را میتوان به عنوان ضرایب غیر مهم در نظر گرفت. حذف این ضرایب واقعاً رفتار تابع را تغییر نخواهد داد.
توسعه مفهوم به شبکههای عصبی
مفهوم بالا را میتوان به شبکههای عصبی نیز تعمیم داد. برای این کار، نیاز به جزئیات بیشتری است. وزنهای یک شبکه آموزشدیده را در نظر بگیرید. چگونه میتوان وزنهای غیرمهم را تفسیر کرد؟ پیشفرض این موضوع چیست؟
برای پاسخ به این سوال، فرآیند بهینهسازی با گرادیان کاهشی را در نظر بگیرید. همه وزنها با استفاده از مقادیر گرادیان یکسان بهروز نمیشوند. گرادیانهای یک تابع زیان معین نسبت به وزنها (و بایاسها) محاسبه میشوند.
در طول فرآیند بهینهسازی، برخی از وزنها با مقادیر گرادیان بزرگتری (هم مثبت و هم منفی) نسبت به سایر وزنها بهروز میشوند. این وزنها توسط بهینهساز برای کمینهسازی هدف آموزش، مهم در نظر گرفته میشوند. وزنهایی که گرادیانهای نسبتاً کوچکتری دریافت میکنند، میتوانند غیرمهم در نظر گرفته شوند.
پس از اتمام آموزش، میتوانیم مقادیر وزنهای یک لایه شبکه را لایه به لایه بررسی کرده و وزنهای مهم را شناسایی کنیم. این تصمیم را میتوان با استفاده از چندین روش اکتشافی اتخاذ کرد:
- میتوانیم مقادیر وزنها را به صورت نزولی مرتب کرده و آنهایی را که زودتر در صف ظاهر میشوند، انتخاب کنیم. این روش معمولاً با سطح پراکندگی (درصد وزنهایی که باید هرس شوند) که میخواهیم به آن برسیم، ترکیب میشود.
- میتوانیم یک آستانه مشخص کنیم و تمام وزنهایی که مقادیر آنها بالاتر از آن آستانه باشد، مهم در نظر گرفته میشوند. این طرح میتواند چندین نوع داشته باشد:
- آستانه میتواند کمترین مقدار وزن در کل شبکه باشد.
- آستانه میتواند مقدار وزن محلی برای لایههای داخل شبکه باشد. در این حالت، وزنهای مهم به صورت لایه به لایه فیلتر میشوند.
اگر درک همه این موارد دشوار است، نگران نباشید. در بخش بعدی، همه چیز روشنتر خواهد شد.
هرس کردن یک شبکه عصبی آموزشدیده
اکنون که درک نسبتاً خوبی از آنچه که میتوان وزنهای مهم نامید، داریم، میتوانیم در مورد هرس مبتنی بر مقدار صحبت کنیم. در هرس مبتنی بر مقدار، مقدار وزن را به عنوان معیار هرس در نظر میگیریم. منظور از هرس، صفر کردن وزنهای غیرمهم است. قطعه کد زیر ممکن است برای درک این موضوع مفید باشد:
# Copy the kernel weights and get ranked indices of the
# column-wise L2 Norms
kernel_weights = np.copy(k_weights)
ind = np.argsort(np.linalg.norm(kernel_weights, axis=0))
# Number of indices to be set to 0
sparsity_percentage = 0.7
cutoff = int(len(ind)*sparsity_percentage)
# The indices in the 2D kernel weight matrix to be set to 0
sparse_cutoff_inds = ind[0:cutoff]
kernel_weights[:,sparse_cutoff_inds] = 0.
در اینجا یک نمایش تصویری از تغییراتی که پس از یادگیری وزنها رخ میدهد، آورده شده است:

این فرآیند میتواند برای بایاسها نیز اعمال شود. توجه به این نکته مهم است که در اینجا یک لایه کامل را در نظر میگیریم که ورودی با شکل (1,2) دریافت میکند و شامل 3 نورون است. اغلب توصیه میشود پس از هرس کردن، شبکه را مجدداً آموزش دهید تا افت احتمالی در عملکرد آن جبران شود. هنگام انجام چنین آموزش مجددی، توجه به این نکته مهم است که وزنهایی که هرس شدهاند، در طول آموزش مجدد بهروز نمیشوند.
مشاهده عملکرد در عمل
بیایید این مفاهیم را در عمل ببینیم. برای ساده نگه داشتن مسائل، این مفاهیم را روی مجموعه داده MNIST آزمایش خواهیم کرد، اما شما باید بتوانید آنها را به مجموعه دادههای پیچیدهتر نیز گسترش دهید. ما از یک شبکه کاملاً متصل کم عمق با توپولوژی زیر استفاده خواهیم کرد:
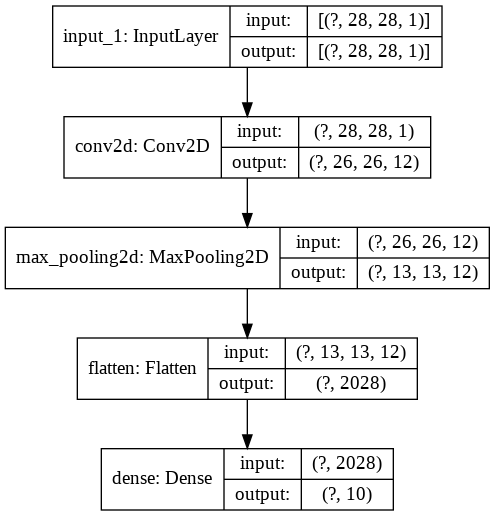
این شبکه در مجموع 20410 پارامتر قابل آموزش دارد. آموزش این شبکه برای 10 ایپاک، یک پایه خوب به ما میدهد.
اکنون هرس میکنیم!
اکنون بیایید شبکه را هرس کنیم! ما از کتابخانه tensorflow_model_optimization (با نام مستعار tfmot) استفاده خواهیم کرد. tfmot دو روش برای هرس کردن ارائه میدهد:
- هرس شبکه آموزش دیده: یک شبکه آموزش دیده را بگیرید و با آموزش بیشتر آن را هرس کنید.
- هرس از ابتدا: یک شبکه با مقداردهی اولیه تصادفی را آموزش دهید و هرس کردن را از ابتدا اعمال کنید.
ما هر دو روش را آزمایش خواهیم کرد. هر دو روش باید شامل یک برنامه هرس باشند که در ادامه در مورد آن بحث خواهیم کرد. منطق پشت هرس کردن یک شبکه در قالب آموزش، هدایت بهتر هدف آموزش است به طوری که بهروزرسانیهای گرادیان بتوانند به طور متناسب برای تنظیم وزنهای هرس نشده به شیوهای مؤثر انجام شوند.
توجه داشته باشید که امکان هرس کردن لایههای خاص در مدل شما نیز وجود دارد و tfmot به شما این امکان را میدهد. برای کسب اطلاعات بیشتر در مورد آن، این
راهنما را بررسی کنید.
روش اول: هرس کردن یک شبکه آموزش دیده با آموزش بیشتر
توصیه میشود از این نقطه به بعد، نوتبوک Colab ذکر شده در بالا را دنبال کنید.
ما قصد داریم شبکهای را که قبلاً آموزش دادهایم، بگیریم و از آنجا هرس کنیم. ما یک برنامه هرس اعمال خواهیم کرد که سطح پراکندگی را در طول آموزش ثابت نگه میدارد (که توسط توسعه دهنده مشخص میشود). کد برای بیان این موضوع به شرح زیر است:
pruning_schedule = tfmot.sparsity.keras.ConstantSparsity(
target_sparsity=target_sparsity,
begin_step=begin_step,
end_step=end_step,
frequency=frequency
)
pruned_model = tfmot.sparsity.keras.prune_low_magnitude(
trained_model, pruning_schedule=pruning_schedule
)
یک مدل هرس شده قبل از شروع آموزش نیاز به کامپایل مجدد دارد. ما آن را به همان روش کامپایل میکنیم و خلاصه آن را چاپ میکنیم:
pruned_model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
pruned_model.summary()
Layer (type) Output Shape Param #
=================================================================
prune_low_magnitude_conv2d ( (None, 26, 26, 12) 230
_________________________________________________________________
prune_low_magnitude_max_pool (None, 13, 13, 12) 1
_________________________________________________________________
prune_low_magnitude_flatten (None, 2028) 1
_________________________________________________________________
prune_low_magnitude_dense (P (None, 10) 40572
=================================================================
Total params: 40,804
Trainable params: 20,410
Non-trainable params: 20,394
_________________________________________________________________
میبینیم که تعداد پارامترها اکنون تغییر کرده است. این به این دلیل است که tfmot ماسکهای غیرقابل آموزش را برای هر یک از وزنهای شبکه اضافه میکند تا مشخص کند که آیا یک وزن مشخص باید هرس شود یا خیر. ماسکها یا 0 یا 1 هستند.
اگر در کولب آموزش دهید، میتوانید ببینید که هرس کردن مدل به عملکرد آن آسیبی نمیرساند. خطوط قرمز مربوط به آزمایشهای هرس کردن هستند.
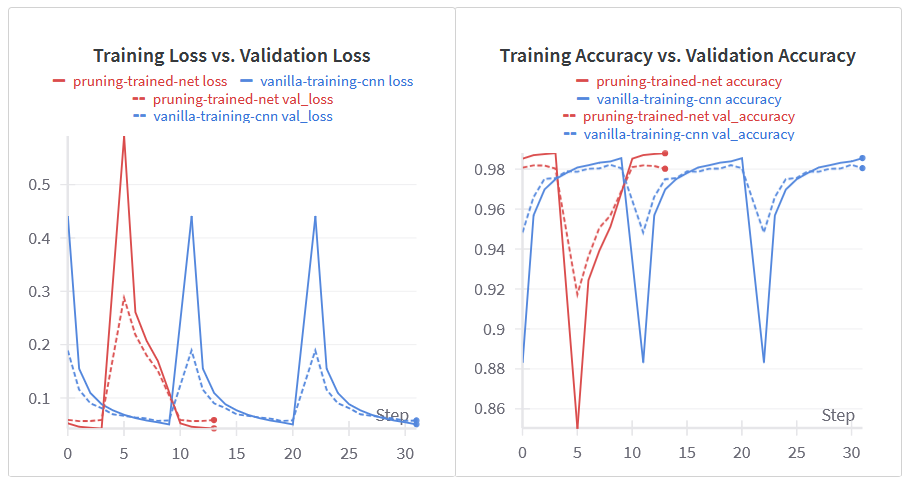
توجه:
- برنامه هرس برای هرس کردن واقعی مدل در حین آموزش، باید حتماً مشخص شود. همچنین، ما از callback
UpdatePruningStepاستفاده میکنیم تا بهروزرسانیهای هرس را در طول آموزش انجام دهد. PruningSummariesخلاصهای از نحوه حفظ پراکندگی و آستانه بزرگی در طول آموزش ارائه میدهد. میتوانید یک نمونه از آن را در اینجا ببینید.- برنامه هرس را به عنوان یک ابرپارامتر در نظر بگیرید.
tfmotیک برنامه هرس دیگر به نامPolynomialDecayرا نیز ارائه میدهد. - شما باید آرگومان
end_stepرا در برنامههای هرس کمتر یا مساوی با تعداد epochهایی که یک مدل را برای آن آموزش میدهید، تنظیم کنید. همچنین، ممکن است لازم باشد با آرگومانfrequency(که نشان دهنده فراوانی اعمال هرس است) آزمایش کنید تا به عملکرد خوب همراه با پراکندگی مطلوب برسید.
همچنین میتوانیم با نوشتن تستهایی مانند موارد زیر، بررسی کنیم که آیا tfmot به پراکندگی هدف رسیده است یا خیر:
for layer in model.layers:
if isinstance(layer, pruning_wrapper.PruneLowMagnitude):
for weight in layer.layer.get_prunable_weights():
print(np.allclose(
target_sparsity, get_sparsity(tf.keras.backend.get_value(weight)),
rtol=1e-6, atol=1e-6)
)
def get_sparsity(weights):
return 1.0 - np.count_nonzero(weights) / float(weights.size)
اجرای بررسی بر روی مدل هرس شده باید مقدار True را برای تمام لایههایی که هرس شدهاند، برگرداند.
دستورالعمل 2: مقداردهی اولیه تصادفی شبکه، هرس آن با آموزش از ابتدا
در این حالت، همه چیز مشابه دستورالعمل قبلی است، با این تفاوت که به جای شروع با یک شبکه از قبل آموزش دیده، با یک شبکه با مقداردهی اولیه تصادفی شروع خواهیم کرد.
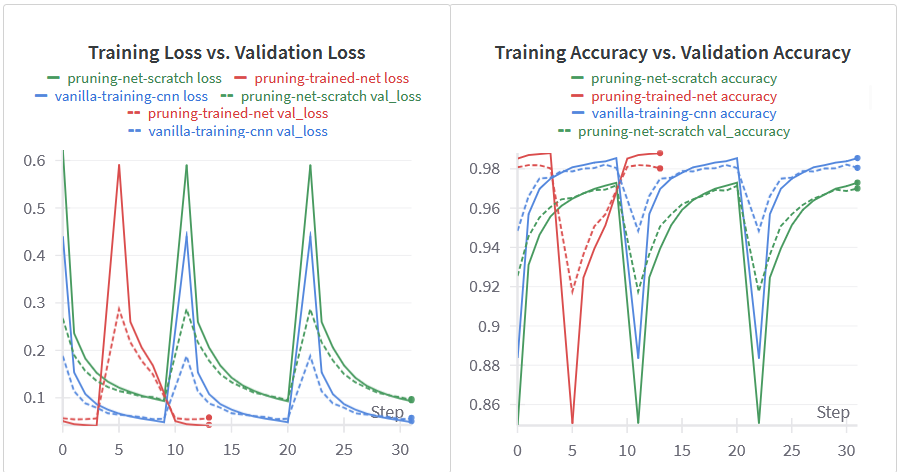
خطوط سبز مربوط به آزمایش هرس از ابتدا هستند. میتوان مشاهده کرد که در مقایسه با دو مدل دیگر، عملکرد تا حدودی کاهش یافته است، اما این امر قابل انتظار است زیرا ما با یک مدل از قبل آموزش دیده شروع نکردهایم.
وقتی شبکه را با آموزش دادن آن از ابتدا هرس میکنیم، معمولاً بیشترین زمان را میبرد. این هم قابل انتظار است زیرا شبکه در حال فهمیدن این است که چگونه پارامترها را به بهترین شکل بهروزرسانی کند تا به سطح پراکندگی هدف برسد.
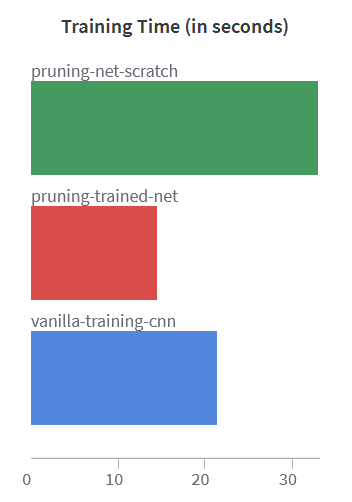
همه اینها خوب است، اما برای اینکه واقعاً از قدرت هرس قدردانی کنیم، باید کمی عمیقتر کاوش کنیم:
- انواع هرسشده و هرسنشده یک شبکه را صادر کنید، آنها را فشرده کرده و اندازههای آنها را یادداشت کنید.
- هر دوی آنها را کوانتیزه کنید، نسخههای کوانتیزه شده آنها را فشرده کنید، اندازههای آنها را یادداشت کرده و عملکرد آنها را ارزیابی کنید.
بیایید در بخش بعدی به آن بپردازیم.
ارزیابی عملکرد
ما از کتابخانه استاندارد zipfile برای فشرده سازی مدل ها به فرمت zip. استفاده خواهیم کرد. هنگام serialize کردن های هرس شده، باید از tfmot.sparsity.keras.strip_pruning استفاده کنیم. این کار pruning wrapper های هرس را که توسط tfmot به مدل ها اضافه شده است، حذف می کند. در غیر این صورت، نمی توانیم هیچ مزیت فشرده سازی در مدل های هرس شده مشاهده کنیم.
با این حال، فشرده سازی مدل های معمولی Keras به همان شکل باقی می ماند.
def get_gzipped_model_size(file):
_, zipped_file = tempfile.mkstemp('.zip')
with zipfile.ZipFile(zipped_file, 'w', compression=zipfile.ZIP_DEFLATED) as f:
f.write(file)
return os.path.getsize(zipped_file)
مسیر file باید به یک مدل Keras از قبل سریال شده باشد (هم مدل هرس شده و هم مدل معمولی).
در شکل زیر، میتوان مشاهده کرد که مدلهای فشردهشده وزن کمتری نسبت به مدل معمولی Keras دارند و همچنان عملکرد بسیار خوبی ارائه میدهند.
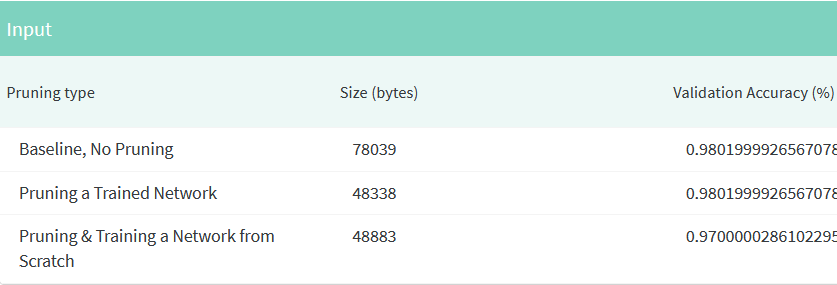
میتوانیم مدلهای خود را با استفاده از TensorFlow Lite کوانتیزه کنیم تا اندازه آنها را بدون افت عملکرد بیشتر کاهش دهیم. توجه داشته باشید که هنگام انتقال مدلهای هرسشده به مبدل TensorFlow Lite، باید آنها را پس از حذف پوششهای هرس منتقل کنید. این گزارش جزئیات بیشتری در مورد کوانتیزاسیون ارائه می دهد.
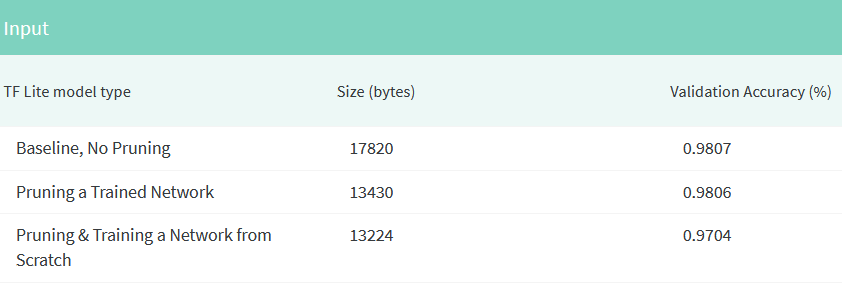
علاوه بر اندازهگیری دقت، نسبت فشردهسازی یکی دیگر از تکنیکهای پرکاربرد برای اندازهگیری کارایی یک الگوریتم هرس خاص است. نسبت فشردهسازی، معکوس کسری از پارامترهای باقیمانده در یک شبکه هرسشده است.
این نوع کوانتیزاسیون نیز به عنوان کوانتیزاسیون پس از آموزش شناخته می شود. بنابراین، در اینجا یک دستورالعمل ساده برای شما وجود دارد تا برای بهینه سازی مدل های خود برای استقرار دنبال کنید:
- آموزش مدل: یک مدل Keras را با استفاده از مجموعه داده آموزشی خود آموزش دهید.
- هرس کردن: از یک الگوریتم هرس برای حذف پارامترهای غیرضروری از مدل آموزش دیده استفاده کنید.
- کوانتیزاسیون: مدل هرس شده را با استفاده از TensorFlow Lite کوانتیزه کنید.
- ارزیابی: دقت و نسبت فشردهسازی مدل کوانتیزه شده را ارزیابی کنید.
- تکرار: در صورت لزوم مراحل 2-4 را تکرار کنید تا به تعادل مطلوب بین دقت و اندازه مدل برسید.
اگر می خواهید زمینه بهینه سازی مدل را بیشتر دنبال کنید، میتوانید ادامه ی این مطلب را از پست انگلیسی اصلی که این بلاگ پست یک ترجمه از بخشی ازآن بوده را دنبال کنید
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

دیدگاهتان را بنویسید