بیشبرازش (Over-fitting) در و راهکارهای جلوگیری از آن
بیشبرازش یک رفتار نامطلوب در یادگیری ماشین است که زمانی رخ میدهد که مدل یادگیری ماشین پیشبینیهای دقیقی برای دادههای آموزشی ارائه میدهد، اما برای دادههای جدید، پیشبینیهای نادرستی ارائه میدهد.
دلایل بیشبرازش:
- اندازه دادههای آموزشی خیلی کوچک است و شامل نمونههای کافی برای نمایندگی دقیق همه مقادیر دادههای ورودی نیست.
- دادههای آموزشی شامل اطلاعات نامربوط زیادی است که به عنوان دادههای نویز شناخته میشود.
- مدل برای مدت طولانی بر روی یک مجموعه داده آموزش میدهد.
- پیچیدگی مدل زیاد است، بنابراین مدل نویز موجود در دادههای آموزشی را یاد میگیرد.
مثالهای بیشبرازش:
مثال اول: یک مدل یادگیری ماشین که باید عکسها را تجزیه و تحلیل کند و عکسهایی که شامل سگ هستند را شناسایی کند.
مثال دوم: یک الگوریتم یادگیری ماشین که عملکرد تحصیلی و نتیجه فارغالتحصیلی یک دانشجو را با تجزیه و تحلیل عوامل مختلف پیشبینی میکند.
چگونه میتوان بیشبرازش را تشخیص داد؟
بهترین روش برای تشخیص مدلهای بیشبرازش، آزمایش مدلهای یادگیری ماشین بر روی دادههای بیشتر با نمایندگی جامع از همه مقادیر و انواع دادههای ورودی است.
اعتبارسنجی متقابل (K-fold cross-validation)
اعتبارسنجی متقابل یکی از روشهای آزمایشی است که در عمل استفاده میشود.
راهکارها و استراتژیها برای جلوگیری از بیشبرازش:
- افزایش دادههای آموزشی
- استفاده از مدلهای سادهتر
- کاهش پارامترهای مدل
- استفاده از Regularization
- استفاده از Dropout
- استفاده از Early Stopping
- استفاده از Cross-Validation
- داده افزایی در مدلهای یادگیری عمیق
کمبرازش (Underfitting) چیست؟
کمبرازش یک نوع خطای دیگر است که زمانی رخ میدهد که مدل نمیتواند رابطه معنیداری بین دادههای ورودی و خروجی برقرار کند.
مطالب زیر را حتما مطالعه کنید

مدل هوش مصنوعی چیست؟
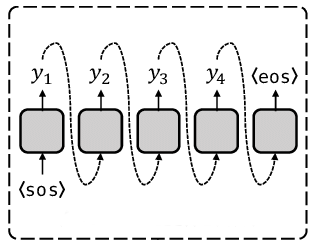
مدلهای خودهمبسته یا Autoregressive
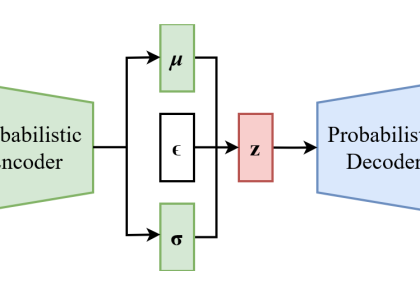
خودرمزگذار متغیر یا VAE چیست و چگونه کار میکند؟

یادگیری عمیق (دیپ لرنینگ) چیست؟

دیدگاهتان را بنویسید