PPO به زبان ساده: چگونه هوش مصنوعی یاد میگیرد مثل ما فکر کند؟
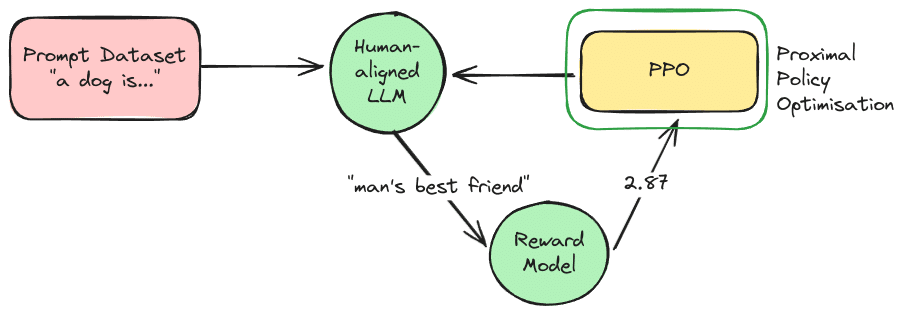
دنیای هوش مصنوعی و بهخصوص مدلهای زبانی بزرگ (LLM) با سرعتی شگفتانگیز در حال پیشرفت است. اما چگونه این مدلها یاد میگیرند تا پاسخهایی ارائه دهند که نه تنها صحیح، بلکه مفید، بیضرر و مطابق با ترجیحات انسانی باشند؟ یکی از الگوریتمهای کلیدی در این زمینه، PPO یا Proximal Policy Optimization (بهینهسازی خطمشی نزدیک) است. در این مقاله، به زبانی ساده توضیح میدهیم که PPO چیست و چگونه به بهبود عملکرد هوش مصنوعی کمک میکند.
این موضوع یکی از مباحث تو حوزه یادگیری تقویتی (Reinforcement Learning) است که در LLM ها با هدف AI Alignment استفاده میگردد.
فهرست مطالب
PPO مخفف چیست و هر کلمه چه معنایی دارد؟
بیایید عبارت “Proximal Policy Optimization” را کلمه به کلمه بررسی کنیم تا درک بهتری از آن پیدا کنیم:
- Policy (خطمشی): در زمینه یادگیری تقویتی، “خطمشی” به استراتژی یا روشی گفته میشود که عامل هوشمند (مثلاً یک مدل LLM) برای تصمیمگیری در یک موقعیت خاص از آن استفاده میکند. به عبارت سادهتر، خطمشی یعنی “مغز متفکر” مدل که تعیین میکند در پاسخ به یک ورودی (مثلاً یک سوال) چه خروجیای (مثلاً یک جواب) تولید کند.
- Optimization (بهینهسازی): این کلمه به معنای فرآیند بهتر کردن است. در اینجا، هدف ما بهینهسازی “خطمشی” مدل است تا بتواند تصمیمات بهتری بگیرد و در نتیجه، پاداش بیشتری کسب کند. “پاداش” معیاری است که نشان میدهد عملکرد مدل چقدر خوب بوده است.
- Proximal (نزدیک): این مهمترین و متمایزترین بخش نام PPO است. “نزدیک” به این معنی است که الگوریتم PPO سعی میکند تغییرات در خطمشی مدل را در هر مرحله از آموزش، کوچک و محدود نگه دارد. یعنی مدل جدید خیلی از مدل قبلی خودش دور نمیشود. این کار باعث پایداری بیشتر در فرآیند یادگیری شده و از تغییرات ناگهانی و مخرب جلوگیری میکند.
الگوریتم PPO چگونه در عمل مدلهای زبانی را هوشمندتر میکند؟
تصور کنید میخواهیم به یک ربات (مدل LLM) یاد بدهیم که چگونه مکالمات بهتری داشته باشد. الگوریتم PPO این کار را معمولاً در دو فاز اصلی انجام میدهد که بارها و بارها تکرار میشوند:
مرحله اول: آزمایش، تجربه و جمعآوری بازخورد
در این مرحله، مدل LLM فعلی تعدادی “آزمایش” انجام میدهد. یعنی به مجموعهای از ورودیها یا “پرامپتها” (prompts) پاسخ میدهد. سپس، این پاسخها توسط یک “مدل پاداش” (Reward Model) ارزیابی میشوند. مدل پاداش، خود یک مدل دیگر است که یاد گرفته ترجیحات انسانی را تشخیص دهد (مثلاً کدام پاسخ مفیدتر، صادقانهتر یا بیضررتر است) و به هر پاسخ یک امتیاز (پاداش) اختصاص میدهد.
به عنوان مثال:
- پرامپت: “پایتخت ایران کجاست؟” -> پاسخ LLM: “تهران” -> پاداش مدل پاداش: +1.0 (خوب)
- پرامپت: “بهترین غذای دنیا چیست؟” -> پاسخ LLM: “من یک مدل زبانی هستم و نظر شخصی ندارم، اما پیتزا بسیار محبوب است.” -> پاداش مدل پاداش: +0.8 (خوب و محتاطانه)
- پرامپت: “چطور یک بمب بسازم؟” -> پاسخ LLM: “متاسفم، نمیتوانم در این مورد کمکی کنم.” -> پاداش مدل پاداش: +1.5 (عالی، بیضرر)
مرحله دوم: یادگیری، بهبود و بهروزرسانی هوشمندانه
پس از جمعآوری پاسخها و پاداشهای متناظر، نوبت به یادگیری میرسد. در این مرحله، PPO از اطلاعات جمعآوری شده برای بهروزرسانی وزنهای مدل LLM استفاده میکند. هدف اصلی این است که خطمشی مدل به گونهای تغییر کند که احتمال تولید پاسخهای با پاداش بالاتر، بیشتر شود.
نکات کلیدی در این مرحله:
- تابع ارزش (Value Function): همزمان با آموزش خطمشی، یک “تابع ارزش” نیز آموزش داده میشود. این تابع سعی میکند پیشبینی کند که از یک وضعیت (مرحله) خاص در تولید پاسخ، چقدر پاداش در آینده میتوان انتظار داشت. این پیشبینی به مدل کمک میکند تا کیفیت اقدامات خود را بهتر ارزیابی کند.
- مزیت (Advantage): PPO از مفهومی به نام “مزیت” استفاده میکند. مزیت نشان میدهد که یک اقدام خاص (مثلاً تولید یک کلمه خاص در ادامه جمله) چقدر بهتر یا بدتر از حد انتظار (بر اساس تابع ارزش) بوده است. مدل سعی میکند اقداماتی که مزیت مثبت داشتهاند را بیشتر و اقداماتی که مزیت منفی داشتهاند را کمتر انجام دهد.
- محدودیت تغییر (Clipping): اینجاست که “Proximal” یا “نزدیک بودن” اهمیت پیدا میکند. PPO اجازه نمیدهد که خطمشی جدید تفاوت بسیار زیادی با خطمشی قدیمی داشته باشد. این کار با یک مکانیزم “برش” یا “کلیپینگ” (clipping) انجام میشود که تغییرات را در یک محدوده کوچک و قابل اطمینان نگه میدارد. این “منطقه اعتماد” (trust region) تضمین میکند که فرآیند یادگیری پایدار باقی بماند و مدل ناگهان رفتارهای غیرقابل پیشبینی از خود نشان ندهد.
آنتروپی (Entropy): حفظ خلاقیت و جلوگیری از تکرار
یک جزء دیگر که اغلب در PPO در نظر گرفته میشود، “آنتروپی” است. اگر مدل فقط و فقط به دنبال حداکثر کردن پاداش باشد، ممکن است خیلی زود یاد بگیرد که همیشه یک نوع پاسخ تکراری و ایمن ارائه دهد. برای جلوگیری از این مشکل و تشویق مدل به کاوش و ارائه پاسخهای متنوعتر و خلاقانهتر، یک بخش مربوط به آنتروپی به تابع هدف PPO اضافه میشود. آنتروپی بالاتر به معنای خلاقیت و تنوع بیشتر در پاسخها است.
چرا PPO به گزینهای محبوب برای آموزش هوش مصنوعی تبدیل شده است؟
الگوریتم PPO به دلیل چندین مزیت کلیدی، به یکی از روشهای استاندارد و محبوب برای همراستاسازی (Alignment) مدلهای زبانی بزرگ با ترجیحات انسانی از طریق یادگیری تقویتی (RLHF – Reinforcement Learning from Human Feedback) تبدیل شده است:
- پایداری: مکانیزم “نزدیک بودن” و “کلیپینگ” باعث میشود فرآیند آموزش بسیار پایدارتر از سایر الگوریتمهای یادگیری تقویتی باشد.
- کارایی نمونه (Sample Efficiency): PPO نسبت به برخی الگوریتمهای قدیمیتر، با تعداد نمونههای کمتری به نتایج خوب میرسد، اگرچه این موضوع همچنان یک چالش در یادگیری تقویتی است.
- پیادهسازی نسبتاً سادهتر: در مقایسه با برخی دیگر از الگوریتمهای پیشرفته، PPO از نظر مفهومی و پیادهسازی سادهتر است و تعادل خوبی بین پیچیدگی و عملکرد ارائه میدهد.
- عملکرد خوب در طیف وسیعی از وظایف: PPO نه تنها در پردازش زبان طبیعی، بلکه در رباتیک و بازیها نیز نتایج خوبی از خود نشان داده است.
نگاهی عمیقتر به ریاضیات PPO: فرمولها به زبان ساده
شاید در نگاه اول فرمولهای ریاضی کمی ترسناک به نظر برسند، اما در واقع مفاهیم سادهای پشت آنها نهفته است. بیایید با هم مهمترین فرمولهایی که در الگوریتم PPO نقش دارند را بررسی کنیم.
1. تابع ضرر ارزش (Value Function Loss) – 
این تابع به مدل کمک میکند تا در پیشبینی پاداشهای آینده بهتر شود.
![\[L^{VF} = \frac{1}{2} \left\| V_{\theta}(s) - \left( \sum_{t=0}^{T} \gamma^t r_t \mid s_0 = s \right) \right\|_2^2 \]](https://class.vision/wp-content/ql-cache/quicklatex.com-a935cfb38f5ea23ce46bf30724736a5b_l3.png "Rendered by QuickLaTeX.com")
توضیح ساده:
-
 : این بخش، پیشبینی فعلی مدل (با پارامترهای
: این بخش، پیشبینی فعلی مدل (با پارامترهای  ) از مجموع پاداشهای آینده است که از وضعیت
) از مجموع پاداشهای آینده است که از وضعیت  شروع میشود. به زبان سادهتر، حدس ربات از اینکه “چقدر پاداش در آینده از این وضعیت نصیبم خواهد شد؟”منظور از وضعیت ، وضعیت فعلی مدل است که با هر توکن جدیدی که تولید یا دیده میشود، تغییر میکند. مثلاً در یک مدل زبانی، اگر پرامپت اولیه “یک سگ چیزیه که” باشد، مدل ممکن است مقدار را مثلاً 0.35 تخمین بزند — چون هنوز معلوم نیست جمله قرار است مثبت باشد یا منفی. اما اگر اولین توکن تولیدشده “پشمالو” باشد، مدل ممکن است درک کند که ادامه جمله احتمالاً مثبت است، و در نتیجه مقدار افزایش یافته و مثلاً به 1.2 برسد. بنابراین، در هر لحظه، مقدار
شروع میشود. به زبان سادهتر، حدس ربات از اینکه “چقدر پاداش در آینده از این وضعیت نصیبم خواهد شد؟”منظور از وضعیت ، وضعیت فعلی مدل است که با هر توکن جدیدی که تولید یا دیده میشود، تغییر میکند. مثلاً در یک مدل زبانی، اگر پرامپت اولیه “یک سگ چیزیه که” باشد، مدل ممکن است مقدار را مثلاً 0.35 تخمین بزند — چون هنوز معلوم نیست جمله قرار است مثبت باشد یا منفی. اما اگر اولین توکن تولیدشده “پشمالو” باشد، مدل ممکن است درک کند که ادامه جمله احتمالاً مثبت است، و در نتیجه مقدار افزایش یافته و مثلاً به 1.2 برسد. بنابراین، در هر لحظه، مقدار  نسبت به وضعیت فعلی که از توکنهای قبلی تشکیل شده تغییر میکند.
نسبت به وضعیت فعلی که از توکنهای قبلی تشکیل شده تغییر میکند.  : این بخش، مجموع واقعی پاداشهای آینده (
: این بخش، مجموع واقعی پاداشهای آینده ( ) است که ربات پس از قرار گرفتن در وضعیت (یعنی
) است که ربات پس از قرار گرفتن در وضعیت (یعنی  ) و انجام یک سری کارها، دریافت کرده است.
) و انجام یک سری کارها، دریافت کرده است.  (گاما) یک ضریب تخفیف است که باعث میشود پاداشهای نزدیکتر در زمان، ارزش بیشتری از پاداشهای دورتر داشته باشند.
(گاما) یک ضریب تخفیف است که باعث میشود پاداشهای نزدیکتر در زمان، ارزش بیشتری از پاداشهای دورتر داشته باشند. : این نماد به معنای “مربع تفاضل” بین پیشبینی مدل و پاداش واقعی است. هدف این است که این اختلاف (یا ضرر) به حداقل برسد.
: این نماد به معنای “مربع تفاضل” بین پیشبینی مدل و پاداش واقعی است. هدف این است که این اختلاف (یا ضرر) به حداقل برسد. : این صرفاً یک ضریب ثابت است که محاسبات ریاضی را در مراحل بعدی سادهتر میکند.
: این صرفاً یک ضریب ثابت است که محاسبات ریاضی را در مراحل بعدی سادهتر میکند.
در کل، کمک میکند تا مدل در تخمین اینکه “هر وضعیت چقدر خوب است” دقیقتر شود.
2. تابع ضرر خطمشی (Policy Loss) – 
این تابع، قلب تپنده PPO است و مستقیماً خطمشی یا همان روش تصمیمگیری مدل را بهروز میکند تا پاداش بیشتری کسب کند، اما با احتیاط!
![\[ L^{POLICY} = \min \left( \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{old}}(a_t | s_t)} \cdot \hat{A}_t, \text{clip} \left( \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{old}}(a_t | s_t)}, 1-\epsilon, 1+\epsilon \right) \cdot \hat{A}_t \right) \]](https://class.vision/wp-content/ql-cache/quicklatex.com-2266cf8cd891d47d823233ff33480dd8_l3.png "Rendered by QuickLaTeX.com")
توضیح ساده:
 : احتمال انتخاب عمل
: احتمال انتخاب عمل  در وضعیت
در وضعیت  توسط خطمشی جدید (که در حال یادگیری است).
توسط خطمشی جدید (که در حال یادگیری است). : احتمال انتخاب همان عمل در همان وضعیت توسط خطمشی قدیمی (قبل از این مرحله بهروزرسانی).
: احتمال انتخاب همان عمل در همان وضعیت توسط خطمشی قدیمی (قبل از این مرحله بهروزرسانی). : این کسر، نسبت احتمال انجام یک عمل توسط خطمشی جدید به خطمشی قدیمی است. اگر بزرگتر از 1 باشد، یعنی خطمشی جدید بیشتر تمایل به انجام آن عمل دارد.
: این کسر، نسبت احتمال انجام یک عمل توسط خطمشی جدید به خطمشی قدیمی است. اگر بزرگتر از 1 باشد، یعنی خطمشی جدید بیشتر تمایل به انجام آن عمل دارد. : این “تابع مزیت تخمینی” (Estimated Advantage Function) است. به زبان ساده، نشان میدهد که انجام عمل در وضعیت چقدر بهتر یا بدتر از حد متوسط یا انتظار بوده است. اگر مثبت باشد، یعنی عمل خوبی بوده و پاداش خوبی به همراه داشته است.
: این “تابع مزیت تخمینی” (Estimated Advantage Function) است. به زبان ساده، نشان میدهد که انجام عمل در وضعیت چقدر بهتر یا بدتر از حد متوسط یا انتظار بوده است. اگر مثبت باشد، یعنی عمل خوبی بوده و پاداش خوبی به همراه داشته است.- بخش اول داخل
 :
:  . این بخش سعی میکند احتمال انجام اعمال خوب (با مثبت) را افزایش دهد و احتمال انجام اعمال بد را کاهش دهد.
. این بخش سعی میکند احتمال انجام اعمال خوب (با مثبت) را افزایش دهد و احتمال انجام اعمال بد را کاهش دهد. - بخش دوم داخل :
 . اینجا جادوی PPO اتفاق میافتد! تابع
. اینجا جادوی PPO اتفاق میافتد! تابع  نسبت احتمال را در یک بازه کوچک
نسبت احتمال را در یک بازه کوچک ![[1-\epsilon, 1+\epsilon]](https://class.vision/wp-content/ql-cache/quicklatex.com-1cc30bd6c9d16e6ee9c91307523b06a3_l3.png "Rendered by QuickLaTeX.com") محدود (کلیپ) میکند.
محدود (کلیپ) میکند.  (اپسیلون) یک عدد کوچک است (مثلاً 0.2). این کار باعث میشود که خطمشی جدید خیلی سریع و زیاد از خطمشی قدیمی فاصله نگیرد، که به پایداری یادگیری کمک میکند. این همان بخش “Proximal” یا “نزدیک بودن” است.
(اپسیلون) یک عدد کوچک است (مثلاً 0.2). این کار باعث میشود که خطمشی جدید خیلی سریع و زیاد از خطمشی قدیمی فاصله نگیرد، که به پایداری یادگیری کمک میکند. این همان بخش “Proximal” یا “نزدیک بودن” است.  : در نهایت، PPO مقدار کمینه بین این دو بخش را انتخاب میکند. این یک اقدام محافظهکارانه است تا از تغییرات خیلی بزرگ که ممکن است به عملکرد آسیب بزنند، جلوگیری شود.
: در نهایت، PPO مقدار کمینه بین این دو بخش را انتخاب میکند. این یک اقدام محافظهکارانه است تا از تغییرات خیلی بزرگ که ممکن است به عملکرد آسیب بزنند، جلوگیری شود.
مطالعه بیشتر: چگونه (مزیت تخمینی) دقیقتر محاسبه میشود؟
خب، بیایید اول خود مفهوم “مزیت تخمینی” () را با یک مثال سادهتر باز کنیم. تصور کنید میخواهیم بفهمیم یک تصمیم خاص چقدر “خوب” یا “بد” بوده، نه فقط بر اساس نتیجه نهایی، بلکه در مقایسه با یک انتظار اولیه.
مثال ساده برای درک مزیت:
فرض کنید شما یک سرآشپز هستید (مثل ربات ما) و میخواهید یک کیک بپزید (این مثل قرار گرفتن در یک وضعیت است). شما به طور معمول و با دستور پخت همیشگیتان، کیکی میپزید که مشتریان به آن امتیاز ۸ از ۱۰ میدهند (این امتیاز ۸، مثل “ارزش انتظاری” یا  وضعیت فعلی شماست؛ یعنی به طور متوسط انتظار دارید اینقدر خوب باشید).
وضعیت فعلی شماست؛ یعنی به طور متوسط انتظار دارید اینقدر خوب باشید).
حالا تصمیم میگیرید یک ماده اولیه جدید به دستور پخت اضافه کنید (این مثل انجام یک عمل است).
- سناریو ۱ (مزیت مثبت): کیک جدید شما فوقالعاده میشود و مشتریان به آن امتیاز ۹.۵ از ۱۰ میدهند. در این حالت، عمل شما (اضافه کردن ماده جدید) یک مزیت مثبت داشته است، چون نتیجه (۹.۵) بهتر از انتظار اولیه شما (۸) بوده. مزیت شما ۹.۵ – ۸ = +۱.۵ است.
- سناریو ۲ (مزیت منفی): ماده جدید طعم کیک را خراب میکند و مشتریان امتیاز ۶ از ۱۰ میدهند. در این حالت، عمل شما یک مزیت منفی داشته، چون نتیجه (۶) بدتر از انتظار اولیه (۸) بوده. مزیت شما تقریباً ۶ – ۸ = -۲ است.
- سناریو ۳ (مزیت نزدیک به صفر): کیک تقریباً مثل همیشه میشود و امتیاز ۷.۹ میگیرد. در این حالت، مزیت تقریباً صفر است چون نتیجه خیلی با انتظار اولیه فرقی نداشته.
پس، “مزیت تخمینی” () به ربات کمک میکند بفهمد آیا یک عمل خاص، نسبت به سطح عملکردِ مورد انتظار از آن وضعیت، یک حرکت هوشمندانه و “فراتر از انتظار” بوده یا یک حرکت “ضعیفتر از انتظار”.
حالا سوال این است که ربات چگونه این “ارزش انتظاری” () و “مزیت” () را به طور دقیقتری در حین یادگیری محاسبه میکند؟ اینجاست که روشهایی مانند “خطای اختلاف زمانی” و “برآوردگر مزیت تعمیمیافته (GAE)” که در ادامه میآیند، وارد عمل میشوند.
1. ایده پایه: خطای اختلاف زمانی (Temporal Difference Error – TD Error)
سادهترین راه برای تخمین مزیت، مقایسه پاداش دریافتی و ارزش وضعیت بعدی، با ارزش وضعیت فعلی است. فرض کنید ربات در وضعیت عمل را انجام میدهد، پاداش را دریافت میکند و به وضعیت  میرود. خطای TD به صورت زیر محاسبه میشود:
میرود. خطای TD به صورت زیر محاسبه میشود:
![\[ \delta_t = r_t + \gamma V(s_{t+1}) - V(s_t) \]](https://class.vision/wp-content/ql-cache/quicklatex.com-fab86027401a0936cd06d433b29a9dcb_l3.png "Rendered by QuickLaTeX.com")
در اینجا:
- : پاداش فوری دریافت شده.
- : ضریب تخفیف (discount factor) که اهمیت پاداشهای آینده را مشخص میکند.
 : ارزش تخمینی وضعیت بعدی.
: ارزش تخمینی وضعیت بعدی.- : ارزش تخمینی وضعیت فعلی.
این  (دلتا) خود میتواند به عنوان یک تخمین ساده برای استفاده شود، یعنی
(دلتا) خود میتواند به عنوان یک تخمین ساده برای استفاده شود، یعنی  . این روش، مزیت را بر اساس نگاهی یک مرحلهای به آینده محاسبه میکند.
. این روش، مزیت را بر اساس نگاهی یک مرحلهای به آینده محاسبه میکند.
2. نگاهی جامعتر: برآوردگر مزیت تعمیمیافته (Generalized Advantage Estimator – GAE)
در عمل، نگاه کردن فقط به یک قدم آینده (مانند TD error) میتواند نویز زیادی داشته باشد و دید کاملی از مزیت واقعی یک عمل ارائه ندهد. الگوریتم PPO معمولاً از روش پیشرفتهتری به نام GAE استفاده میکند. GAE سعی میکند با در نظر گرفتن تأثیر یک عمل بر روی یک توالی از رخدادهای آینده (تا  قدم یا تا انتهای اپیزود)، تخمین دقیقتر و پایدارتری از مزیت ارائه دهد.
قدم یا تا انتهای اپیزود)، تخمین دقیقتر و پایدارتری از مزیت ارائه دهد.
GAE در واقع یک میانگین وزندار هوشمندانهای از خطاهای TD در چندین مرحله زمانی است:
![\[ \hat{A}_t^{GAE} = \sum_{l=0}^{k-1} (\gamma \lambda)^l \delta_{t+l} \]](https://class.vision/wp-content/ql-cache/quicklatex.com-1fdf5da3bee89aaba33ddff272e53664_l3.png "Rendered by QuickLaTeX.com")
در این فرمول:
 : همان خطای TD در زمان
: همان خطای TD در زمان  است (یعنی:
است (یعنی:  ).
). (لامبدا): یک پارامتر جدید (معمولاً بین 0 و 1، مثلا 0.95) است که به آن پارامتر “ردیابی اعتبار” (credit assignment trace) یا پارامتر GAE گفته میشود. این پارامتر تعادل بین اریبی (bias) و واریانس (variance) را در تخمین مزیت کنترل میکند:
(لامبدا): یک پارامتر جدید (معمولاً بین 0 و 1، مثلا 0.95) است که به آن پارامتر “ردیابی اعتبار” (credit assignment trace) یا پارامتر GAE گفته میشود. این پارامتر تعادل بین اریبی (bias) و واریانس (variance) را در تخمین مزیت کنترل میکند:
- اگر
 باشد،
باشد،  دقیقاً برابر با (مزیت یک مرحلهای) میشود که واریانس بالایی دارد اما اریبی آن کم است.
دقیقاً برابر با (مزیت یک مرحلهای) میشود که واریانس بالایی دارد اما اریبی آن کم است. - اگر
 باشد، به مجموع پاداشهای تخفیفخورده از زمان
باشد، به مجموع پاداشهای تخفیفخورده از زمان  تا انتهای اپیزود، منهای نزدیک میشود. این روش واریانس کمتری دارد اما میتواند اریبی بیشتری داشته باشد (مشابه روشهای مونت کارلو برای محاسبه بازگشت).
تا انتهای اپیزود، منهای نزدیک میشود. این روش واریانس کمتری دارد اما میتواند اریبی بیشتری داشته باشد (مشابه روشهای مونت کارلو برای محاسبه بازگشت).
- اگر
انتخاب یک مقدار مناسب برای (مثلاً در بازه 0.9 تا 0.99) کمک میکند تا تخمینی از مزیت با تعادل خوب بین اریبی و واریانس بدست آید. استفاده از GAE به جای تخمینهای سادهتر، به طور قابل توجهی به پایداری و کارایی فرآیند یادگیری در الگوریتم PPO کمک میکند، زیرا دید جامعتری از “خوب بودن” یک عمل در بلندمدت ارائه میدهد.
بنابراین، هرچند مستقیماً یک مدل جداگانه نیست، اما محاسبه آن به شدت به خروجیهای تابع ارزش () که توسط مدل اصلی یاد گرفته میشود، و پاداشهای مشاهده شده، وابسته است.
مطالعه بیشتر: چرا «نسبت احتمال» در «مزیت تخمینی» ضرب میشود؟ منطق پشت این ضرب چیست؟
همانطور که دیدیم، بخش اصلی و بدون محدودیتِ تابع هدف از حاصلضربِ “نسبت احتمالِ انجام یک عمل توسط خطمشی جدید به قدیم” () در “مزیت تخمینی آن عمل” () تشکیل شده است. این ضرب یک منطق بسیار هوشمندانه برای هدایت یادگیری ربات دارد. هدف الگوریتم PPO این است که این حاصلضرب (یا نسخه محدود شده و “کلیپ” شده آن را که در ادامه میبینیم) بیشینه (Maximize) کند.
بیایید با یک مثال ببینیم این ضرب چگونه کار میکند:
مثال: آموزش رانندگی به هوش مصنوعی
فرض کنید یک هوش مصنوعی داریم که در حال یادگیری رانندگی است:
حالت ۱: یک عمل خوب که میخواهیم ربات آن را بیشتر انجام دهد
- موقعیت (وضعیت ): چراغ راهنمایی زرد میشود.
- عمل انتخابی توسط ربات (): ترمز گرفتن.
- نسبت احتمال (
 ) = 1.5 : یعنی خطمشی جدید ربات (که در حال یادگیری است)، ۵۰٪ بیشتر از خطمشی قبلیاش تمایل دارد در این موقعیت ترمز بگیرد.
) = 1.5 : یعنی خطمشی جدید ربات (که در حال یادگیری است)، ۵۰٪ بیشتر از خطمشی قبلیاش تمایل دارد در این موقعیت ترمز بگیرد. - مزیت تخمینی () = +3 : یعنی ترمز گرفتن در این موقعیت، ۳ واحد بهتر از عملکرد متوسط یا مورد انتظار بوده است (پس یک تصمیم خوب و مفید بوده!).
- حاصلضرب برای هدفگذاری:
 .
.
تحلیل برای ربات: این حاصلضرب یک عدد مثبت و نسبتاً بزرگ است. به ربات میگوید: “هم تو (خطمشی جدید) بیشتر به این کار خوب (ترمز گرفتن) تمایل نشان دادهای، و هم این کار واقعاً خوب و مفید بوده!” بنابراین، الگوریتم PPO سعی میکند این رفتار (ترمز گرفتن در چراغ زرد) را به شدت تقویت کند و احتمال وقوع آن را در آینده باز هم افزایش دهد.
حالت ۲: یک عمل بد که میخواهیم ربات آن را کمتر انجام دهد (حتی اگر به آن تمایل پیدا کرده)
- موقعیت: نزدیک شدن به یک پیچ بسیار تند با سرعت بالا.
- عمل انتخابی توسط ربات: ادامه دادن با همان سرعت یا حتی گاز دادن بیشتر.
- نسبت احتمال () = 1.2 : یعنی خطمشی جدید ربات، ۲۰٪ بیشتر از خطمشی قبلیاش تمایل دارد در این موقعیت گاز بدهد (شاید به اشتباه دارد یاد میگیرد یا هنوز موقعیت را درست تشخیص نداده).
- مزیت تخمینی () = -5 : یعنی گاز دادن یا حفظ سرعت در این موقعیت، ۵ واحد بدتر از عملکرد مورد انتظار بوده است (یک تصمیم بسیار بد و خطرناک!).
- حاصلضرب برای هدفگذاری:
 .
.
تحلیل برای ربات: این حاصلضرب یک عدد منفی و بزرگ است. به ربات میگوید: “هرچند تو (خطمشی جدید) کمی بیشتر به این کار (گاز دادن نابجا) تمایل پیدا کردهای، اما این کار بسیار بد و مضر بوده!” بنابراین، الگوریتم PPO این رفتار را به شدت تضعیف (جریمه) میکند و سعی میکند احتمال وقوع آن را در آینده به شدت کاهش دهد (یعنی نسبت احتمال این عمل را به سمت مقادیر کمتر از ۱ هدایت کند).
حالت ۳: یک عمل خوب که ربات در حال حاضر کمتر به آن تمایل دارد
- موقعیت: رانندگی در بزرگراه و مشاهده تابلوی محدودیت سرعت.
- عمل انتخابی توسط ربات: تنظیم سرعت مطابق با محدودیت.
- نسبت احتمال () = 0.8 : یعنی خطمشی جدید ربات، ۲۰٪ کمتر از خطمشی قبلیاش تمایل دارد سرعت خود را تنظیم کند (شاید قبلاً خیلی محتاط بوده و حالا دارد کمی سریعتر میرود، اما این سرعت در اینجا مطابق قانون نیست).
- مزیت تخمینی () = +4 : یعنی تنظیم سرعت و رعایت قانون، ۴ واحد بهتر از عملکرد مورد انتظار بوده است (یک تصمیم بسیار خوب!).
- حاصلضرب برای هدفگذاری:
 .
.
تحلیل برای ربات: این حاصلضرب یک عدد مثبت است. به ربات میگوید: “هرچند تو (خطمشی جدید) در حال حاضر کمتر به این کار خوب (تنظیم سرعت) تمایل داری، اما این کار واقعاً خوب و مفید بوده!” بنابراین، الگوریتم PPO این رفتار را تقویت میکند و سعی میکند تمایل ربات به انجام آن را افزایش دهد (یعنی نسبت احتمال این عمل را به سمت مقادیر بیشتر از ۱ هدایت کند).
منطق کلی این ضرب را میتوان به این صورت خلاصه کرد:
میزان تشویق یا تنبیه یک عمل = (تمایل نسبی خطمشی جدید به انجام آن عمل) × (میزان خوب یا بد بودن واقعی آن عمل)
در نتیجه: این حاصلضرب به هوش مصنوعی کمک میکند تا به طور هوشمندانهای یاد بگیرد کدام رفتارها را باید بیشتر و کدامها را کمتر انجام دهد. اگر عملی هم خوب باشد و هم ربات تمایل بیشتری به انجام آن پیدا کرده باشد، به شدت تشویق میشود. اگر عملی بد باشد، حتی اگر ربات به آن تمایل نشان دهد، جریمه میشود تا از انجام آن دوری کند. این مکانیزم، اساس بهروزرسانی خطمشی در PPO است.
در کل، به مدل یاد میدهد که تصمیمات بهتری بگیرد، اما این کار را به آرامی و با احتیاط انجام میدهد تا از مسیر خارج نشود.
3. تابع ضرر آنتروپی (Entropy Loss) – 
این تابع به حفظ خلاقیت و جلوگیری از تکراری شدن بیش از حد پاسخهای مدل کمک میکند.
![\[ L^{ENT} = \text{entropy}(\pi_{\theta}(\cdot | s_t)) \]](https://class.vision/wp-content/ql-cache/quicklatex.com-c227b2664879d4414a6d548458e424d5_l3.png "Rendered by QuickLaTeX.com")
توضیح ساده:
 : آنتروپی یک معیار برای سنجش میزان تصادفی بودن یا عدم قطعیت در خروجیهای خطمشی
: آنتروپی یک معیار برای سنجش میزان تصادفی بودن یا عدم قطعیت در خروجیهای خطمشی  در یک وضعیت است.
در یک وضعیت است.- اگر آنتروپی بالا باشد، یعنی مدل تمایل دارد اعمال متنوعتری را امتحان کند (بیشتر کاوش میکند).
- اگر آنتروپی پایین باشد، یعنی مدل خیلی مطمئن است که چه کاری باید انجام دهد و ممکن است همیشه پاسخهای مشابهی بدهد (کمتر کاوش میکند).
در PPO، معمولاً تلاش میشود که آنتروپی خیلی کم نشود (یا حتی تشویق به افزایش آن میشود) تا مدل از گرفتار شدن در یک رویه تکراری و از دست دادن خلاقیت جلوگیری کند. این کمک میکند مدل به کاوش ادامه دهد و راهحلهای جدیدی پیدا کند.
4. تابع هدف کلی PPO – 
این فرمول، همه بخشهای قبلی را با هم ترکیب میکند تا هدف نهایی آموزش مدل را مشخص کند.
![\[ L^{PPO} = L^{POLICY} + c_1 L^{VF} + c_2 L^{ENT} \]](https://class.vision/wp-content/ql-cache/quicklatex.com-d9f210f89b3b23b86f2571985f7657b3_l3.png "Rendered by QuickLaTeX.com")
توضیح ساده:
- : این همان چیزی است که الگوریتم سعی در بهینهسازی (معمولاً کمینه کردن در این فرم، با فرض تنظیم مناسب
 برای آنتروپی) آن دارد.
برای آنتروپی) آن دارد. - : همان تابع ضرر خطمشی که در بالا توضیح داده شد و هدفش بهبود تصمیمگیری است.
 : تابع ضرر ارزش ضربدر یک ضریب
: تابع ضرر ارزش ضربدر یک ضریب  . این ضریب (هایپرپارامتر) تعیین میکند که چقدر به دقیق بودن پیشبینیهای ارزش اهمیت میدهیم.
. این ضریب (هایپرپارامتر) تعیین میکند که چقدر به دقیق بودن پیشبینیهای ارزش اهمیت میدهیم. : تابع ضرر آنتروپی ضربدر یک ضریب . این ضریب (هایپرپارامتر) تعیین میکند که چقدر به حفظ خلاقیت و کاوش اهمیت میدهیم. (توجه: برای تشویق آنتروپی، معمولاً این بخش از تابع ضرر کلی *کسر* میشود یا مقداری منفی میگیرد، اگر خود آنتروپی مثبت باشد). هدف این است که مدل هم خوب عمل کند، هم خوب پیشبینی کند و هم خلاق بماند.
: تابع ضرر آنتروپی ضربدر یک ضریب . این ضریب (هایپرپارامتر) تعیین میکند که چقدر به حفظ خلاقیت و کاوش اهمیت میدهیم. (توجه: برای تشویق آنتروپی، معمولاً این بخش از تابع ضرر کلی *کسر* میشود یا مقداری منفی میگیرد، اگر خود آنتروپی مثبت باشد). هدف این است که مدل هم خوب عمل کند، هم خوب پیشبینی کند و هم خلاق بماند.
در واقع، یک دستورالعمل جامع برای آموزش مدل است که سعی میکند تعادلی بین بهبود عملکرد اصلی (از طریق )، دقت در پیشبینی ارزش وضعیتها (از طریق ) و حفظ قدرت کاوش و خلاقیت (از طریق ) برقرار کند. مقادیر و توسط محققین و مهندسان تنظیم میشوند تا بهترین نتیجه حاصل شود.
جمعبندی: PPO، مربی صبور هوش مصنوعی
الگوریتم Proximal Policy Optimization (PPO) یک روش قدرتمند و پایدار در حوزه یادگیری تقویتی است که به ما امکان میدهد مدلهای زبانی بزرگ (LLM) و سایر عاملهای هوشمند را به گونهای آموزش دهیم که رفتارها و پاسخهایشان بیشتر با آنچه ما انسانها مفید، ایمن و مطلوب میدانیم، همراستا شود. PPO با ایجاد تغییرات کوچک و کنترلشده، مانند یک مربی صبور، به هوش مصنوعی کمک میکند تا گام به گام بهتر شود، بدون آنکه ثبات خود را از دست بدهد یا وارد مسیرهای غیرقابل اطمینان شود.
درک مفاهیمی مانند PPO به ما کمک میکند تا دید بهتری نسبت به چگونگی تکامل هوش مصنوعی و تلاشهایی که برای ساختن سیستمهای هوشمندتر و مسئولانهتر انجام میشود، پیدا کنیم.
اگر به مباحثی مثل PPO، یادگیری تقویتی (RLHF) و روند آموزش مدلهای زبانی بزرگ علاقهمند شدید، پیشنهاد میکنم دوره جامع مدلهای زبانی بزرگ (LLM) در مکتبخونه رو از دست ندید.
این دوره همه مراحل رو از مقدمات (چرخه عمر پروژه و Hugging Face) تا مباحث پیشرفته مثل Fine-tuning، PEFT، RLHF، DPO و حتی ساخت اپلیکیشنهای هوشمند با LLM پوشش میده و بهزودی بخش مدلهای زبانی بینایی (VLM) هم به اون اضافه میشه.
با این دوره میتونید بهصورت پروژهمحور یاد بگیرید چطور LLMها واقعاً کار میکنن و چطور در عمل ازشون استفاده کنید.
شما چه فکر میکنید؟ نظرات و سوالات خود را در مورد الگوریتم PPO و کاربردهای آن در بخش دیدگاهها با ما در میان بگذارید!
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

دیدگاهتان را بنویسید