یادگیری نظارتشده و بدون ناظر(Supervised Learning و Unsupervised Learning)
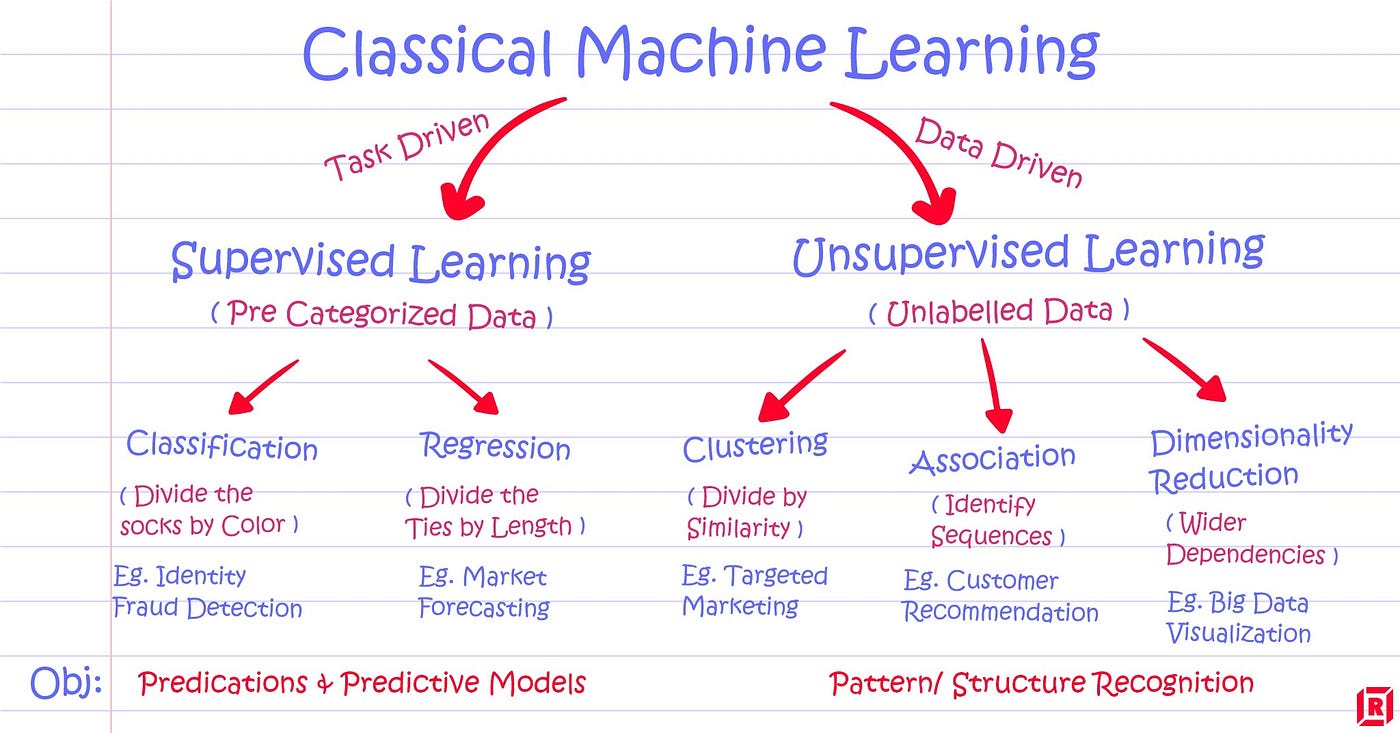
در الگوریتمهای یادگیری ماشینی، الگوریتم ها معمولا به سه دسته تقسیم بندی میشوند، نظارت شده، بدون ناظر و یادگیری تقویتی. در این پست دو رویکرد یادگیری نظارتشده یا Supervised Learning و یادگیری بدون نظارت یا Unsupervised Learning را بررسی خواهیم کرد. (در برخی از ترجمه ها ممکن است از لفظ یادگیری با نظارت و بدون نظارت استفاده گردد)
یادگیری نظارتشده (Supervised) چیست؟
- مسائل طبقهبندی از یک الگوریتم برای قراردادن دادههای آزمایش در دستههای خاص، مانند جدا کردن سیب از پرتقال استفاده میکنند. یا در دنیای واقعی، میتوان از این الگوریتمهای یادگیری تحت نظارت برای طبقهبندی هرزنامهها و قرار دادن آنها در یک پوشه جداگانه از صندوق ورودی ایمیل استفاده کرد. طبقهبندیکنندههای خطی (Linear Classifiers)، ماشینهای بردار پشتیبان(Support Vector Machines) ، درختهای تصمیمگیری (Decision Trees) و جنگلهای تصادفی (Random Forest) همه انواع رایجی از الگوریتمهای طبقهبندی هستند.
-
رگرسیون نوع دیگری از روشهای یادگیری تحت نظارت است که از الگوریتمی برای درک رابطهی بین متغیرهای وابسته و مستقل استفاده میکند. مدلهای رگرسیون برای پیشبینی مقادیر عددی بر اساس دادههای مختلف، مانند پیشبینی درآمد فروش برای یک کسبوکار معین، مفید هستند. برخی از الگوریتمهای رگرسیون رایج عبارتند از رگرسیون خطی (Linear Regression)، رگرسیون لجستیک (Logistic Regression) و رگرسیون چند جمله ای (Polynomial Regression).
یادگیری بدون ناظر (Unsupervised) چیست؟
یادگیری بدون ناظر از الگوریتمهای یادگیری ماشین برای تجزیه و تحلیل و خوشهبندی مجموعهدادههای بدون برچسب استفاده میکند. این الگوریتمها بدون نیاز به دخالت انسان، الگوهای پنهان در دادهها را کشف میکنند (به همین دلیل، آنها “بدون ناظر” خوانده میشوند).
به طور کلی، مدلهای یادگیری بدون ناظر برای سه کار اصلی استفاده میشوند: خوشهبندی (Clustering)، ارتباط (Association) و کاهش بعد (Dimensionality Reduction):
- خوشهبندی یک تکنیک یادگیری ماشین و دادهکاوی برای گروهبندی دادههای بدون برچسب بر اساس شباهتها یا تفاوتهای آنهاست. برای مثال، الگوریتم خوشهبندی K-means، نقاط دادهی مشابه را به گروههای یکسان اختصاص میدهد، و مقدار K نشاندهندهی تعداد گروه و دانهبندی است. این تکنیک برای تقسیمبندی بازار، فشردهسازی تصویر و غیره مفید است.
- ارتباط نوع دیگری از روشهای یادگیری بدون نظارت است که از قوانین مختلفی برای یافتن روابط بین متغیرها در یک مجموعه دادهی معین استفاده میکند. این روشها اغلب برای تحلیل سبد بازار و سیستمهای توصیهگر، در راستای توصیههایی نظیر «مشتریانی که این کالا را خریدند، آن کالا را هم خریدهاند» استفاده میشوند.
- کاهش بعد یک تکنیک یادگیری است که زمانی استفاده میشود که تعداد ویژگیها (یا ابعاد) در یک مجموعهی داده بسیار بالا است. این روشها تعداد ویژگیهای ورودی داده را به اندازهای قابل مدیریت کاهش می دهند و در عین حال یکپارچگی دادهها را نیز حفظ میکنند. اغلب، این تکنیک در مرحلهی پیشپردازش دادهها استفاده می شود، مانند زمانی که رمزگذارهای خودکار نویز را از دادههای تصویری به جهت بهبود کیفیت تصویر حذف میکنند.
صد البته که الگوریتم های بدون ناظر به این سه محدود نمیشوند و انواع دیگری نیز وجود دارد.
تفاوت اصلی در یادگیری نظارت شده و بدون ناظر: دادهی برچسبخورده
تمایز اصلی بین این دو رویکرد استفاده از مجموعه دادههای برچسبگذاریشده است. به بیان ساده، یادگیری تحت نظارت از دادههای ورودی و خروجی برچسبخورده استفاده میکند، در حالی که الگوریتم یادگیری بدون نظارت این کار را نمیکند.
سایر تفاوتهای کلیدی بین روشهای یادگیری تحت نظارت و بدون نظارت
- اهداف: در یادگیری نظارتشده، هدف پیشبینی نتایج برای دادههای جدید است. شما از قبل از نوع نتایجی که باید انتظار آنها را داشته باشید خبر دارید. در مقابل هدف استفاده از الگوریتمهای بدون ناظر این است که بینشی با استفاده از حجم قابل توجه دادهی دردسترس بدست بیاوریم. روشهای یادگیری ماشین، خود مشخص میکنند که چه چیزی در بین دادهها جالب و یا متفاوت است.
- کاربرد: مدل های یادگیری نظارتشده برای تشخیص هرزنامه، تجزیه و تحلیل احساسات، پیشبینی آبو هوا و پیشبینی قیمت و موارد دیگر ایده آل هستند. در مقابل، یادگیری بدون ناظر برای تشخیص ناهنجاریها، سیستمهای توصیهگر، شخصیسازی مشتریان و تصویربرداری پزشکی مناسب است.
- پیچیدگی: یادگیری تحت نظارت روشی ساده برای یادگیری ماشین است که معمولاً از طریق استفاده از زبانهایی مانند R یا Python قابل توسعه هستند. در یادگیری بدون نظارت، به ابزارهای قدرتمندی برای کار با مقادیر زیادی از دادههای طبقهبندی نشده نیاز دارید. مدلهای یادگیری بدون نظارت از نظر محاسباتی پیچیدهتر هستند؛ چرا که به دادههای آموزشی زیادی برای تولید نتایج مورد نظر نیاز خواهند داشت.
- مشکلات: آموزش مدلهای یادگیری تحت نظارت ممکن است زمانبر باشد؛ همچنین تولید دادههای برچسبخورده نیازمند تخصص در حوزهی مدنظر است. در همین حال، روشهای یادگیری بدون نظارت میتوانند نتایج بسیار نادرستی داشته باشند، مگر اینکه مداخله انسانیای برای اعتبارسنجی متغیرهای خروجی وجود داشته باشد.
یادگیری با نظارت و بدون نظارت: کدام برای شما مناسب است؟
- دادهی ورودی را ارزیابی کنید: آیا دادههای شما برچسبگذاری شده است یا خیر؟ آیا افراد متخصص برای برچسبگذاری دادهها را در اختیار دارید؟
- اهداف خود را تعیین کنید: آیا مسئلهی شما یک مسئلهی پرتکرار و خوشتعریف است؟ یا اینکه الگوریتم نیاز به حل مسائل جدیدی دارد؟
- گزینههای الگوریتمی خود را دوره کنید: آیا الگوریتمهایی با همان ابعاد مورد نیاز شما (تعداد ویژگیهای ورودی) وجود دارد؟ آیا آنها میتوانند حجم و ساختار دادهی شما را پشتیبانی کنند؟
یادگیری نیمهنظارتی (Semi-Supervised): بهترینهای هر دو رویکرد
بیشتر در خصوص یادگیری تحت نظارت و بدون نظارت بیاموزید
- یادگیری بدون نظارت چیست؟
- هوش مصنوعی، یادگیری ماشین، یادگیری عمیق، شبکههای عصبی: تفاوت آنها در چیست؟
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 1

راهنمای قدم به قدم کرایه کارت گرافیک (GPU) با Vast.ai برای پروژههای هوش مصنوعی

دیدگاهتان را بنویسید