ترنسفورمر در کراس و تنسرفلو
(توجه: این مطلب هنوز نیاز به ویرایش نهایی دارد، با این حال قابل خواند است…)
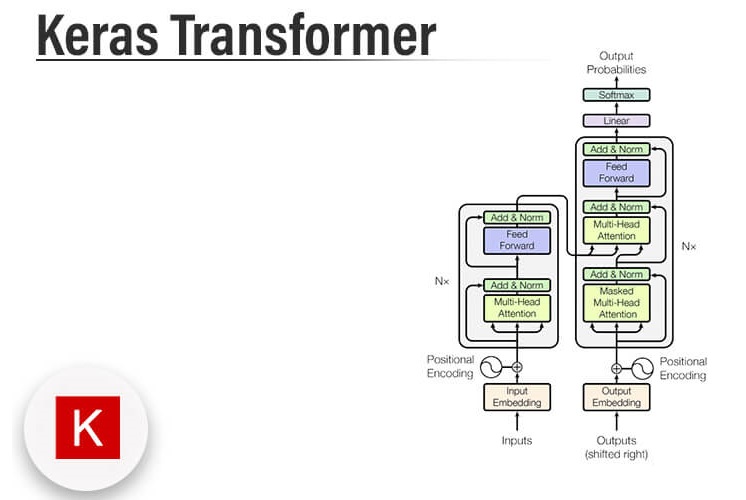
معماری ترنسفورمر
از سال ۲۰۱۷، یک معماری مدل جدید شروع به پیشی گرفتن از recurrent neural networks در اکثر وظایف NLP کرد، آن معماری ترنسفورمر بود!
ترنسفورمرها در مقالهای مهم به نام “Attention is all you need” توسط Vaswani و همکارانش معرفی شدند. اصل مطلب مقاله در همان عنوان قرار دارد: همانطور که مشخص شد، یک مکانیزم ساده به نام “neural attention” میتواند برای ساخت مدلهای توالی قدرتمندی استفاده شود که هیچ recurrent layers یا convolution layers ندارند.
این کشف باعث شروع یک انقلاب در NLP و فراتر از آن شد. neural attention به سرعت به یکی از ایدههای تاثیرگذار در deep learning تبدیل شده است. در این بخش، توضیح عمیقی از نحوه عملکرد آن و دلیل موثر بودن آن برای sequence data ارائه خواهد شد. سپس از self-attention (توجه-به-خود) برای ایجاد یک Transformer encoder، یکی از اجزای پایه معماری ترنسفورمر، استفاده خواهیم کرد و آن را به کار IMDB movie review classification task اعمال خواهیم کرد.
درک self-attention (توجه-به-خود)
همانطور که این متن را مطالعه میکنید، ممکن است برخی بخشها را سطحی مرور کنید و برخی دیگر را با دقت بخوانید، که بسته به اهداف یا علایق شما است. تصور کنید مدلهای شما هم همین کار را انجام دهند! این ایدهای ساده اما قدرتمند است: همه اطلاعات ورودی که یک مدل مشاهده میکند به یک اندازه برای وظیفهای که در دست است مهم نیستند، بنابراین مدلها باید به برخی ویژگیها بیشتر “توجه” کنند و به برخی دیگر کمتر “توجه” کنند. آیا این برایتان آشنا به نظر میرسد؟ دو مفهوم مشابه در یادگیری ماشینی و یادگیری عمیق وجود دارد:
- Max pooling (ادغام بیشینه) در convnets (شبکههای عصبی کانولوشنالی) به مجموعهای از ویژگیها در یک ناحیه فضایی نگاه میکند و فقط یک ویژگی را برای نگهداشتن انتخاب میکند. این نوعی از توجه all or nothing یا “همه یا هیچ” است: مهمترین ویژگی را نگه میدارد و بقیه را دور میاندازد.
- TF-IDF normalization (نرمالسازی TF-IDF) به توکنها بر اساس میزان اطلاعاتی که احتمالاً حمل میکنند، امتیاز اهمیت میدهد. توکنهای مهم تقویت میشوند در حالی که توکنهای بیاهمیت کمرنگ میشوند. این یک شکل پیوسته از توجه است.
انواع مختلفی از توجه وجود دارد که میتوانید تصور کنید، اما همه آنها با محاسبه امتیازات اهمیت برای مجموعهای از ویژگیها شروع میشوند، با امتیازات بالاتر برای ویژگیهای مرتبطتر و امتیازات پایینتر برای ویژگیهای کمتر مرتبط (شکل زیر را ببینید). اینکه این امتیازات چگونه باید محاسبه شوند و چه کاری باید با آنها انجام دهید، از یک روش به روش دیگر متفاوت خواهد بود.
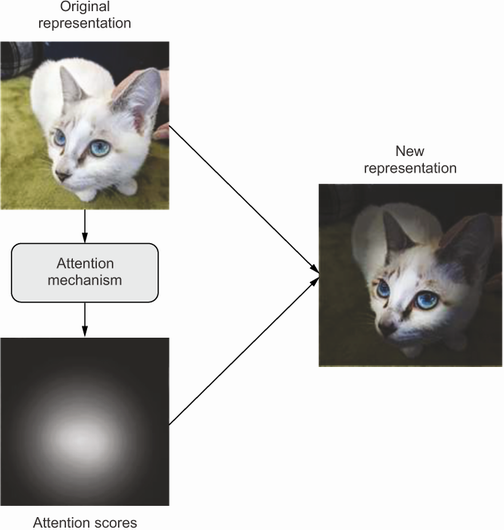
مفهوم کلی “توجه” در یادگیری عمیق: ویژگیهای ورودی امتیازات توجهی دریافت میکنند که میتوان از آنها برای اطلاعرسانی به نمایش بعدی ورودی استفاده کرد.
نکته مهم این است که این نوع مکانیزم توجه میتواند برای مواردی بیشتر از برجسته کردن یا پاک کردن برخی ویژگیها استفاده شود. میتوان از آن برای آگاهسازی ویژگیها نسبت به زمینه نیز استفاده کرد. مثلا درباره تعبیههای کلمات (word embeddings) —فضاهای برداری که “شکل” روابط معنایی بین کلمات مختلف را به تصویر میکشند. در یک فضای تعبیه، یک کلمه یک موقعیت ثابت دارد—یک مجموعه روابط ثابت با هر کلمه دیگر در فضا. اما این دقیقاً نحوه کار زبان نیست: معنای یک کلمه معمولاً وابسته به زمینه است. وقتی شیر را مینوشید، در مورد همان “شیر” صحبت نمیکنید که وقتی به باغ وحش میروید و شیر میبینید!، یا حتی وقتی شیر آب را باز میکنید و صورتتان را آب میزنید!
به وضوح، یک فضای تعبیه هوشمند برای یک کلمه نمایشی برداری متفاوتی ارائه میدهد بسته به کلمات دیگر اطراف آن. اینجاست که self-attention (توجه-به-خود) وارد میشود. هدف self-attention این است که نمایشی از یک توکن را با استفاده از نمایشهای توکنهای مرتبط در توالی تعدیل کند. این تولید نمایشیهای توکن آگاه از زمینه میکند. به یک جمله مثال توجه کنید: “قطار به موقع ایستگاه را ترک کرد.” حالا، به یک کلمه در جمله توجه کنید: ایستگاه (station). در مورد چه نوع ایستگاهی صحبت میکنیم؟ میتواند یک ایستگاه رادیویی باشد؟ شاید ایستگاه فضایی بینالمللی؟ بیایید به صورت الگوریتمی با استفاده از self-attention آن را مشخص کنیم (شکل زیر را ببینید).
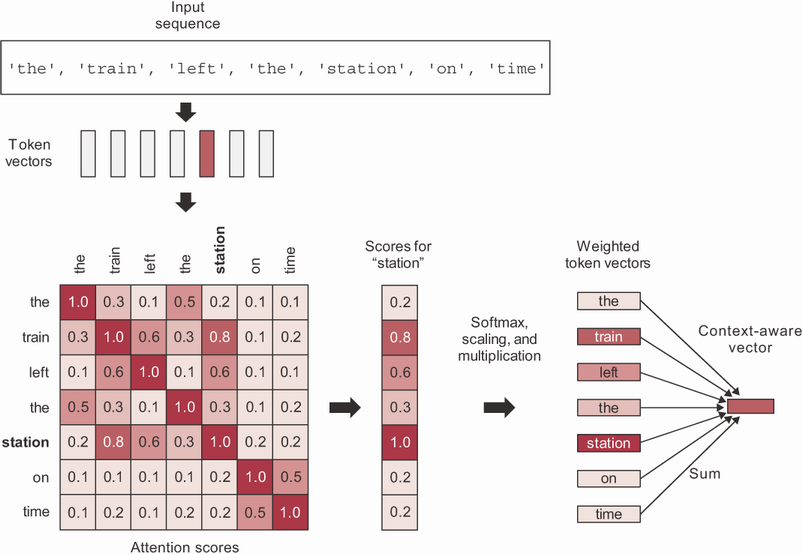
مرحله ۱ محاسبه امتیازات ارتباطی (relevancy scores) بین بردار “station” و هر کلمه دیگر در جمله است. اینها امتیازات توجه (attention scores) ما هستند. ما به سادگی از حاصل ضرب نقطهای بین دو بردار کلمه به عنوان معیاری برای قدرت رابطه آنها استفاده خواهیم کرد. این یک تابع فاصلهای بسیار کارآمد از نظر محاسباتی است و مدتها قبل از ترنسفورمرها به عنوان روش استاندارد برای ارتباط دو تعبیه کلمه به کار میرفت. در عمل، این امتیازات همچنین از یک تابع مقیاسبندی و یک softmax عبور میکنند، اما فعلاً این فقط یک جزئیات پیادهسازی است.
مرحله ۲ محاسبه مجموع همه بردارهای کلمات در جمله، وزندهی شده با امتیازات ارتباطی ما است. کلمات نزدیک به “station” بیشتر به مجموع کمک میکنند (از جمله کلمه “station” خودش)، در حالی که کلمات بیربط تقریباً هیچ کمکی نخواهند کرد. بردار حاصل نمایشی جدید ما برای “station” است: نمایشی که زمینه اطراف را دربرمیگیرد. به طور خاص، شامل بخشی از بردار “train” است که مشخص میکند که در واقع یک “ایستگاه قطار” است.
شما این فرآیند را برای هر کلمه در جمله تکرار میکنید و یک توالی جدید از بردارها که جمله را رمزگذاری میکنند، تولید میکنید. بیایید آن را به صورت شبه کد مشابه NumPy ببینیم:
def self_attention(input_sequence): output = np.zeros(shape=input_sequence.shape) for i, pivot_vector in enumerate(input_sequence):# ❶ scores = np.zeros(shape=(len(input_sequence),)) for j, vector in enumerate(input_sequence): scores[j] = np.dot(pivot_vector, vector.T)# ❷ scores /= np.sqrt(input_sequence.shape[1])# ❸ scores = softmax(scores)# ❸ new_pivot_representation = np.zeros(shape=pivot_vector.shape) for j, vector in enumerate(input_sequence): new_pivot_representation += vector * scores[j]# ❹ output[i] = new_pivot_representation# ❺ return output
❶ تکرار بر روی هر توکن در توالی ورودی.
❷ محاسبه حاصل ضرب نقطهای (امتیاز توجه) بین توکن و هر توکن دیگر.
❸ مقیاسدهی با یک فاکتور نرمالسازی و اعمال softmax.
❹ گرفتن مجموع همه توکنها وزندهی شده با امتیازات توجه.
❺ آن مجموع خروجی ماست.

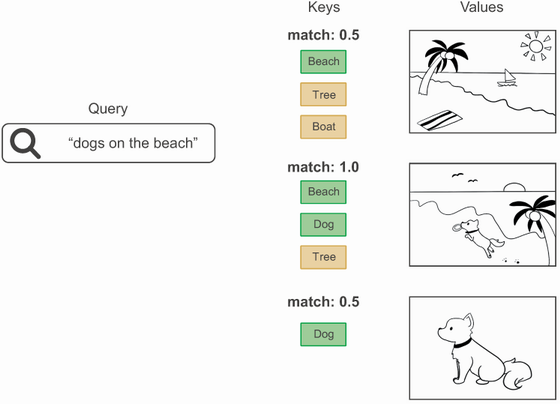
مفهومی، این همان کاری است که توجه به سبک ترنسفورمر انجام میدهد. شما یک توالی مرجع دارید که چیزی را که به دنبال آن هستید توصیف میکند: query (پرسش). شما یک مجموعه دانش دارید که سعی میکنید از آن اطلاعات استخراج کنید: values (مقادیر). به هر value (مقدار) یک key (کلید) اختصاص داده شده است که مقدار را به صورتی توصیف میکند که به راحتی قابل مقایسه با query (پرسش) باشد. شما به سادگی query (پرسش) را با keys (کلیدها) مطابقت میدهید. سپس یک مجموع وزندار از values (مقادیر) را برمیگردانید.
در عمل، keys (کلیدها) و values (مقادیر) اغلب همان توالی هستند. در ترجمه ماشینی، به عنوان مثال، query (پرسش) توالی هدف خواهد بود، و توالی منبع نقشهای هر دو keys (کلیدها) و values (مقادیر) را ایفا خواهد کرد: برای هر عنصر از هدف (مانند “tiempo”)، شما میخواهید به منبع (“How’s the weather today?”) برگردید و قسمتهای مختلفی را که به آن مرتبط هستند شناسایی کنید (“tiempo” و “weather” باید تطابق قوی داشته باشند). و طبیعی است که اگر شما فقط در حال انجام طبقهبندی توالی باشید، در آن صورت query (پرسش)، keys (کلیدها) و values (مقادیر) همه یکسان هستند: شما در حال مقایسه یک توالی با خودش هستید تا هر توکن را با زمینهای از کل توالی غنی کنید.
این توضیح میدهد که چرا ما نیاز داشتیم ورودیها را سه بار به لایهMultiHeadAttention خود ارسال کنیم. اما چرا توجه “چند-سر” (multi-head)؟
توجه چند-سر (Multi-head attention)
“توجه چند-سر” یک بهبود اضافی برای مکانیزم توجه-به-خود است که در مقاله “Attention is all you need” معرفی شده است. عنوان “چند-سر” به این واقعیت اشاره دارد که فضای خروجی لایه توجه-به-خود به مجموعهای از زیرفضاهای مستقل تفکیک میشود که به طور جداگانه آموزش داده میشوند: query (پرسش)، key (کلید) و value (مقدار) اولیه از طریق سه مجموعه مستقل از dense projection ارسال میشوند که منجر به سه بردار جداگانه میشود. هر بردار از طریق توجه عصبی پردازش میشود و سه خروجی به یک توالی خروجی واحد ترکیب میشوند. هر یک از این زیرفضاها “سر” نامیده میشود. تصویر کامل در شکل زیر نشان داده شده است.
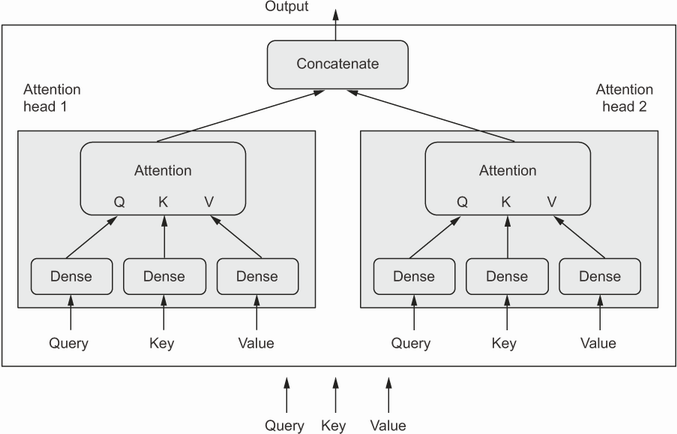
یک لایهیMultiHeadAttention
حضور dense projection قابل یادگیری به لایه اجازه میدهد که واقعاً چیزی یاد بگیرد، به جای اینکه یک تبدیل کاملاً stateless (بدون وضعیت) باشد که برای مفید بودن به لایههای اضافی قبل یا بعد از آن نیاز داشته باشد. علاوه بر این، داشتن سرهای مستقل به لایه کمک میکند تا گروههای مختلفی از ویژگیها را برای هر توکن یاد بگیرد، جایی که ویژگیها در یک گروه با یکدیگر همبسته هستند اما عمدتاً از ویژگیهای یک گروه دیگر مستقل هستند.
این اصل مشابه آن چیزی است که باعث میشود کانولوشنهای جداپذیر عمیق (depthwise separable convolutions) کار کنند: در یک کانولوشن جداپذیر عمیق، فضای خروجی کانولوشن به بسیاری از زیرفضاها تفکیک میشود (یکی برای هر کانال ورودی) که به طور مستقل یاد گرفته میشوند. مقاله “Attention is all you need” در زمانی نوشته شده بود که ایده تفکیک فضاهای ویژگی به زیرفضاهای مستقل نشان داده بود که برای مدلهای بینایی کامپیوتری بسیار مفید است – هم در مورد کانولوشنهای جداپذیر عمیق و هم در مورد یک رویکرد نزدیک به آن، کانولوشنهای گروهی (grouped convolutions). توجه چند-سر به سادگی کاربرد همین ایده برای توجه-به-خود است.
ترنسفورمر انکودر
این تقریباً فرآیند فکری است که من تصور میکنم در ذهن مخترعان معماری ترنسفورمر در آن زمان شکل گرفته است. فاکتور کردن خروجیها به چند فضای مستقل، اضافه کردن اتصالات باقیمانده، اضافه کردن لایههای نرمالسازی—همه اینها الگوهای معماری استانداردی هستند که بهتر است در هر مدل پیچیدهای به کار گرفته شوند. اینها با هم،انکودر ترنسفورمر را تشکیل میدهند—یکی از دو بخش حیاتی که معماری ترنسفورمر را تشکیل میدهند (به شکل زیر نگاه کنید).
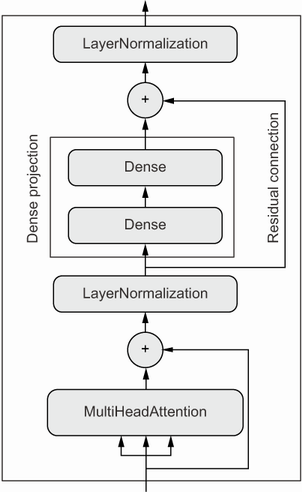
نکته مهم این است که بخش انکودر میتواند برای طبقهبندی متن (text classification) استفاده شود—این یک ماژول بسیار عمومی است که یک دنباله را پذیرفته و یاد میگیرد که آن را به یک بازنمایی مفیدتر تبدیل کند. بیایید یک ترنسفورمر انکودر پیادهسازی کنیم و آن را روی وظیفه طبقهبندی احساسات نقد فیلم امتحان کنیم.
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
class TransformerEncoder(layers.Layer):
def __init__(self, embed_dim, dense_dim, num_heads, **kwargs):
super().__init__(**kwargs)
self.embed_dim = embed_dim #❶
self.dense_dim = dense_dim #❷
self.num_heads = num_heads #❸
self.attention = layers.MultiHeadAttention(
num_heads=num_heads, key_dim=embed_dim)
self.dense_proj = keras.Sequential(
[layers.Dense(dense_dim, activation="relu"),
layers.Dense(embed_dim),]
)
self.layernorm_1 = layers.LayerNormalization()
self.layernorm_2 = layers.LayerNormalization()
def call(self, inputs, mask=None): #❹
if mask is not None: #❺
mask = mask[:, tf.newaxis, :] #❺
attention_output = self.attention(
inputs, inputs, attention_mask=mask)
proj_input = self.layernorm_1(inputs + attention_output)
proj_output = self.dense_proj(proj_input)
return self.layernorm_2(proj_input + proj_output)
def get_config(self): #❻
config = super().get_config()
config.update({
"embed_dim": self.embed_dim,
"num_heads": self.num_heads,
"dense_dim": self.dense_dim,
})
return config
❷ اندازه لایه چگال درونی
❸ تعداد سرهای توجه
❹ محاسبات در call() انجام میشود.
❺ ماسکی که توسط لایه جاسازی (Embedding) تولید میشود دو بعدی خواهد بود، اما لایه توجه انتظار دارد که سه بعدی یا چهار بعدی باشد، بنابراین رتبه آن را افزایش میدهیم.
❻ پیادهسازی سریالسازی (serialization) تا بتوانیم مدل را ذخیره کنیم.
ذخیرهسازی لایههای سفارشی
وقتی که لایههای سفارشی مینویسید، مطمئن شوید که متد get_config را پیادهسازی کنید: این کار امکان بازآفرینی (reinstantiate) لایه از دیکشنری تنظیمات (config dict) آن را فراهم میکند، که در زمان ذخیره و بارگذاری مدل مفید است. این متد باید یک دیکشنری پایتون را برگرداند که مقادیر آرگومانهای سازندهای که برای ایجاد لایه استفاده شدهاند را شامل شود. تمام لایههای Keras میتوانند به صورت زیر سریالسازی و دسیریالسازی شوند:
config = layer.get_config() new_layer = layer.__class__.from_config(config) #1
❶ تنظیمات شامل مقادیر وزنها نیستند، بنابراین تمام وزنهای لایه از ابتدا مقداردهی اولیه میشوند.
برای مثال:
layer = PositionalEmbedding(sequence_length, input_dim, output_dim) config = layer.get_config() new_layer = PositionalEmbedding.from_config(config)
هنگام ذخیره یک مدل که شامل لایههای سفارشی است، فایل ذخیره شامل این دیکشنریهای تنظیمات خواهد بود. هنگام بارگذاری مدل از فایل، باید کلاسهای لایه سفارشی را به فرآیند بارگذاری ارائه دهید تا بتواند تنظیمات اشیاء را تفسیر کند:
model = keras.models.load_model(
filename, custom_objects={"PositionalEmbedding": PositionalEmbedding})
def batch_normalization(batch_of_images): ❶ mean = np.mean(batch_of_images, keepdims=True, axis=(0, 1, 2)) ❷ variance = np.var(batch_of_images, keepdims=True, axis=(0, 1, 2)) ❷ return (batch_of_images - mean) / variance
❶ شکل ورودی: (batch_size، height، width، channels)
❷ تجمیع دادهها بر روی محور batch (محور 0)، که تعاملات بین نمونهها در یک batch را ایجاد میکند.
در حالی که BatchNormalization اطلاعات را از بسیاری از نمونهها جمعآوری میکند تا آمار دقیقی برای میانگینها و واریانسهای ویژگیها به دست آورد، LayerNormalization دادهها را در هر دنباله به صورت جداگانه تجمیع میکند، که برای دادههای ترتیبی مناسبتر است.
حالا که ترنسفورمر انکودر (TransformerEncoder) خود را پیادهسازی کردهایم، میتوانیم از آن برای ساخت یک مدل طبقهبندی متن استفاده کنیم.
vocab_size = 20000 embed_dim = 256 num_heads = 2 dense_dim = 32 inputs = keras.Input(shape=(None,), dtype="int64") x = layers.Embedding(vocab_size, embed_dim)(inputs) x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x) x = layers.GlobalMaxPooling1D()(x) ❶ x = layers.Dropout(0.5)(x) outputs = layers.Dense(1, activation="sigmoid")(x) model = keras.Model(inputs, outputs) model.compile(optimizer="rmsprop", loss="binary_crossentropy", metrics=["accuracy"]) model.summary()
❶ از آنجا که ترنسفورمر انکودر (TransformerEncoder) دنبالههای کامل را برمیگرداند، ما نیاز داریم که هر دنباله را به یک بردار منفرد برای طبقهبندی از طریق یک لایه تجمیع (global pooling layer) کاهش دهیم.
بیایید آن را آموزش دهیم. به دقت 87.5٪ در تست میرسد. (فعلا عالی نیست!)
callbacks = [
keras.callbacks.ModelCheckpoint("transformer_encoder.keras",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20,
callbacks=callbacks)
model = keras.models.load_model(
"transformer_encoder.keras",
custom_objects={"TransformerEncoder": TransformerEncoder}) ❶
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")
❶ کلاس سفارشی ترنسفورمر انکودر (TransformerEncoder) را به فرآیند لود مدل ارائه دهید.
در این نقطه، ممکن است شروع به احساس ناراحتی کنید. چیزی اینجا درست نیست. میتوانید بگویید چیست؟
این بخش ظاهراً درباره “مدلهای ترتیبی” است. من با تاکید بر اهمیت ترتیب کلمات شروع کردم. گفتم که ترنسفورمر یک معماری پردازش دنبالهای است که در اصل برای ترجمه ماشینی توسعه داده شده است. و با این حال… ترنسفورمر انکودری که شما در عمل دیدید اصلاً یک مدل ترتیبی نبود. متوجه شدید؟ این مدل از لایههای چگالی (dense layers) تشکیل شده که توکنهای دنباله را به طور مستقل از یکدیگر پردازش میکنند، و یک لایه توجه (attention layer) که توکنها را به صورت یک مجموعه در نظر میگیرد. شما میتوانید ترتیب توکنها در یک دنباله را تغییر دهید و همچنان همان نمرات توجه زوجی (pairwise attention scores) و همان نمایشهای با زمینه آگاه (context-aware representations) را دریافت کنید. اگر شما کلمات هر نقد فیلم را کاملاً به هم بزنید، مدل متوجه نخواهد شد و همچنان دقیقاً همان دقت را خواهد داشت. خود توجه (Self-attention) یک مکانیزم پردازش مجموعهای است که بر روی روابط بین زوجهای عناصر دنباله تمرکز دارد (به شکل زیر نگاه کنید) —این مکانیزم نسبت به این که این عناصر در ابتدا، انتها یا وسط یک دنباله قرار دارند، بیتوجه است. پس چرا میگوییم که ترنسفورمر یک مدل ترتیبی است؟ و چگونه ممکن است برای ترجمه ماشینی خوب باشد اگر به ترتیب کلمات توجهی ندارد؟
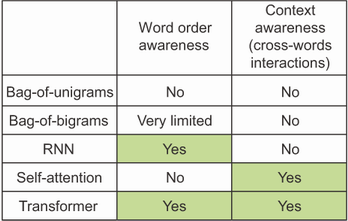
استفاده از کدگذاری موقعیتی برای بازگرداندن اطلاعات ترتیب
سادهترین طرحی که میتوانید ارائه دهید این است که موقعیت کلمه را به بردار جاسازی آن الحاق کنید. شما یک محور “موقعیت” به بردار اضافه میکنید و آن را برای اولین کلمه در دنباله با 0، برای دومین با 1 و به همین ترتیب پر میکنید. با این حال، این ممکن است ایدهآل نباشد، زیرا موقعیتها میتوانند به طور بالقوه اعداد صحیح بسیار بزرگی باشند که دامنه مقادیر در بردار جاسازی را مختل خواهند کرد. همانطور که میدانید، شبکههای عصبی مقادیر ورودی بسیار بزرگ یا توزیعهای ورودی گسسته را دوست ندارند.
مقاله اصلی “Attention is all you need” از یک ترفند جالب برای کدگذاری موقعیت کلمات استفاده کرد: این مقاله به بردارهای جاسازی کلمه، یک بردار حاوی مقادیر در بازه [-1، 1] که به صورت چرخهای بسته به موقعیت تغییر میکرد اضافه کرد (از توابع کسینوسی برای این کار استفاده کرد). این ترفند روشی را ارائه میدهد تا هر عدد صحیح را در یک دامنه بزرگ از طریق یک بردار از مقادیر کوچک به صورت منحصربهفرد مشخص کند. این ترفند هوشمندانه است، اما ما قرار نیست از آن در مورد خودمان استفاده کنیم. ما کاری سادهتر و مؤثرتر انجام خواهیم داد: ما بردارهای جاسازی موقعیت را به همان روشی که یاد میگیریم تا شاخصهای کلمه را جاسازی کنیم، یاد خواهیم گرفت. سپس جاسازیهای موقعیت خود را به جاسازیهای کلمه مربوطه اضافه خواهیم کرد تا یک جاسازی کلمه آگاه از موقعیت به دست آوریم. این تکنیک به عنوان “جاسازی موقعیتی” (positional embedding) شناخته میشود. بیایید آن را پیادهسازی کنیم.
class PositionalEmbedding(layers.Layer):
def __init__(self, sequence_length, input_dim, output_dim, **kwargs): ❶
super().__init__(**kwargs)
self.token_embeddings = layers.Embedding( ❷
input_dim=input_dim, output_dim=output_dim)
self.position_embeddings = layers.Embedding(
input_dim=sequence_length, output_dim=output_dim) ❸
self.sequence_length = sequence_length
self.input_dim = input_dim
self.output_dim = output_dim
def call(self, inputs):
length = tf.shape(inputs)[-1]
positions = tf.range(start=0, limit=length, delta=1)
embedded_tokens = self.token_embeddings(inputs)
embedded_positions = self.position_embeddings(positions)
return embedded_tokens + embedded_positions ❹
def compute_mask(self, inputs, mask=None): ❺
return tf.math.not_equal(inputs, 0) ❺
def get_config(self): ❻
config = super().get_config()
config.update({
"output_dim": self.output_dim,
"sequence_length": self.sequence_length,
"input_dim": self.input_dim,
})
return config
❶ یک نقطه ضعف از جاسازی موقعیتی این است که طول دنباله باید از پیش معلوم باشد.
❷ یک لایه Embedding برای شاخصهای توکن آماده کنید.
❸ و یک لایه دیگر برای موقعیتهای توکنها
❹ هر دو بردار جاسازی را با هم اضافه کنید.
❺ مانند لایه Embedding، این لایه باید قادر باشد تا یک ماسک تولید کند تا بتوانیم صفرهای پر کننده را در ورودیها نادیده بگیریم. متد compute_mask به طور خودکار توسط چارچوب فراخوانی خواهد شد، و ماسک به لایه بعدی منتقل خواهد شد.
❻ سریالسازی را پیادهسازی کنید تا بتوانیم مدل را ذخیره کنیم.
شما از این لایه PositionEmbedding به همان روشی که از یک لایه Embedding معمولی استفاده میکنید. بیایید آن را در عمل ببینیم!
vocab_size = 20000
sequence_length = 600
embed_dim = 256
num_heads = 2
dense_dim = 32
inputs = keras.Input(shape=(None,), dtype="int64")
x = PositionalEmbedding(sequence_length, vocab_size, embed_dim)(inputs) ❶
x = TransformerEncoder(embed_dim, dense_dim, num_heads)(x)
x = layers.GlobalMaxPooling1D()(x)
x = layers.Dropout(0.5)(x)
outputs = layers.Dense(1, activation="sigmoid")(x)
model = keras.Model(inputs, outputs)
model.compile(optimizer="rmsprop",
loss="binary_crossentropy",
metrics=["accuracy"])
model.summary()
callbacks = [
keras.callbacks.ModelCheckpoint("full_transformer_encoder.keras",
save_best_only=True)
]
model.fit(int_train_ds, validation_data=int_val_ds, epochs=20, callbacks=callbacks)
model = keras.models.load_model(
"full_transformer_encoder.keras",
custom_objects={"TransformerEncoder": TransformerEncoder,
"PositionalEmbedding": PositionalEmbedding})
print(f"Test acc: {model.evaluate(int_test_ds)[1]:.3f}")
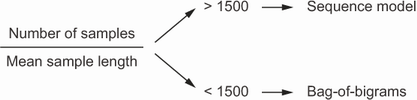
بنابراین اگر شما در حال طبقهبندی اسنادی با ۱۰۰۰ کلمه طولانی هستید و ۱۰۰,۰۰۰ نمونه از آنها دارید (نسبت ۱۰۰)، باید از یک مدل bigram استفاده کنید. اگر در حال طبقهبندی توییتهایی هستید که به طور متوسط ۴۰ کلمه دارند و ۵۰,۰۰۰ نمونه از آنها دارید (نسبت ۱۲۵۰)، باید باز هم از یک مدل bigram استفاده کنید. اما اگر اندازه مجموعه داده خود را به ۵۰۰,۰۰۰ توییت افزایش دهید (نسبت ۱۲۵۰۰)، باید از یک انکودر Transformer استفاده کنید. حالا در مورد وظیفه طبقهبندی نقدهای فیلم IMDB چه میتوان گفت؟ ما ۲۰,۰۰۰ نمونه آموزشی و میانگین تعداد کلمات ۲۳۳ داشتیم، بنابراین قاعده سرانگشتی ما به مدل bigram اشاره میکند، که این موضوع چیزی است که در عمل هم مشاهده کردیم.
این موضوع به صورت شهودی منطقی است: ورودی یک مدل ترتیبی یک فضای غنیتر و پیچیدهتر را نشان میدهد و بنابراین دادههای بیشتری برای ترسیم آن فضا نیاز است؛ در حالی که یک مجموعه ساده از اصطلاحات فضایی بسیار سادهتر است که میتوان با استفاده از چند صد یا چند هزار نمونه یک رگرسیون لجستیک بر روی آن آموزش داد. علاوه بر این، هرچه یک نمونه کوتاهتر باشد، مدل نمیتواند به راحتی هیچ یک از اطلاعات آن را نادیده بگیرد—به ویژه ترتیب کلمات مهمتر میشود و نادیده گرفتن آن میتواند ابهام ایجاد کند. جملات “this movie is the bomb” و “this movie was a bomb” نمایشهای unigram بسیار نزدیکی دارند، که میتواند مدل bag-of-words را گیج کند، اما یک مدل ترتیبی میتواند تشخیص دهد که کدام یک منفی و کدام یک مثبت است. با یک نمونه طولانیتر، آمار کلمات قابل اطمینانتر میشود و موضوع یا احساس از طریق هیستوگرام کلمات به تنهایی واضحتر خواهد بود.
اکنون به خاطر داشته باشید که این قاعده سرانگشتی به طور خاص برای طبقهبندی متن توسعه یافته است. ممکن است برای سایر وظایف پردازش زبان طبیعی به درستی عمل نکند—برای مثال، زمانی که به ترجمه ماشینی میرسیم، Transformer به ویژه برای دنبالههای بسیار طولانی، در مقایسه با RNNها میدرخشد. قاعده ما نیز تنها یک قاعده سرانگشتی است، نه یک قانون علمی، بنابراین انتظار داشته باشید که بیشتر اوقات کار کند، اما نه لزوماً هر بار.
منبع: فصل 11 کتاب Deep Learning with Python, Second Edition نوشتهی François Chollet
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

دیدگاهتان را بنویسید