ترنسفورمر – Fine-tuning مدلهای زبانی
در پستهای قبلی پیرامون ترنسفورمر، بررسی کردیم که مدلهای زبانی چگونه کار میکنند و چگونه میتوان از آنها برای وظایف مختلف مانند تولید متن و طبقهبندی توالی استفاده کرد. مشاهده کردیم که مدلهای زبانی بدون نیاز به آموزش بیشتر میتوانند در بسیاری از وظایف مفید باشند، با استفاده از prompts مناسب و قابلیتهای zero-shot این مدلها. همچنین برخی از صدها هزار مدل از پیش آموزشدیده شده توسط جامعه را بررسی کردیم. در این پست آموزشی، خواهیم دید که چگونه میتوان عملکرد مدلهای زبانی را بر روی وظایف خاص با Fine-Tune آنها روی دادههای خود بهبود بخشید.
اگر سلسله پستهای قبلی پیرامون ترنسفورمر را ندیدید میتوانید از اینجا مطالعه کنید:
در حالی که مدلهای از پیش آموزشدیده شده قابلیتهای شگفتانگیزی را نشان میدهند، آموزش عمومی آنها ممکن است برای برخی وظایف یا حوزهها مناسب نباشد. Fine-Tune برای تطبیق درک مدل با جزئیات دادهها یا وظیفه خاص ضروری است. به عنوان مثال، در زمینه تحقیق پزشکی، یک مدل زبانی که بر روی متنهای عمومی وب آموزش دیده است، بهخوبی کار نخواهد کرد، بنابراین میتوانیم آن را بر روی مجموعهای از ادبیات پزشکی Fine-Tune کنیم تا توانایی آن در تولید متنهای پزشکی مرتبط یا کمک به استخراج اطلاعات از مستندات بهداشتی را افزایش دهیم. مثال دیگری برای ساخت مدلهای مکالمهای است. مدلهای بزرگ از پیش آموزشدیده شده برای پیشبینی توکن بعدی آموزش دیدهاند، و معمولاً برای مکالمات یا کاربرد چتبات از همان ابتدا کار نمیکند. ما میتوانیم این مدل را بر روی یک مجموعه داده شامل مکالمات روزمره و ساختارهای زبانی غیررسمی Fine-Tune کنیم و مدل را به تولید متنی مکالمهای و جذاب، همچون چیزی که در رابطهایی مانند ChatGPT انتظار دارید، تطبیق دهیم.
هدف این آموزش ایجاد پایههای قوی در Fine-Tune مدلهای زبانی بزرگ (LLMها) است و بنابراین موارد زیر را پوشش خواهیم داد:
- طبقهبندی موضوع یک متن با استفاده از یک مدل ترنسفورمر Fine-Tune شده
- تولید متن به سبک خاص با استفاده از مدل دیکودر
- حل وظایف متعدد با یک مدل واحد از طریق Fine-Tune دستورات
- تکنیکهای Fine-Tune کارآمد از نظر پارامتر که به ما امکان میدهند مدلها را با GPUهای کوچکتر آموزش دهیم
- تکنیکهایی که به ما امکان میدهند مدلها را با محاسبات کمتر اجرا کنیم
طبقهبندی متن
قبل از ورود به دنیای مدلهای مولد، ایده خوبی است که جریان کلی Fine-Tune یک مدل از پیش آموزشدیده شده را درک کنیم. برای این منظور، با طبقهبندی توالی(sequence classification) شروع میکنیم. طبقهبندی یک توالی یکی از مسائل کلاسیک یادگیری ماشینی است که در مسائلی نظیر تشخیص اسپم، شناسایی احساسات، طبقهبندی intent و تشخیص محتوای جعلی کاربرد دارد.
ما یک مدل را برای طبقهبندی موضوع خلاصه مقالات خبری کوتاه Fine-Tune خواهیم کرد. همانطور که در دورهی جامع یادگیری عمیق آموختیم، Fine-Tune نیاز به محاسبات و دادههای بسیار کمتری نسبت به آموزش یک مدل از ابتدا دارد. روند معمولا به این صورت است:
- شناسایی یک مجموعه داده برای وظیفه یا مساله
- تعریف نوع مدل مورد نیاز (انکودر، دیکودر یا انکودر-دیکودر)
- شناسایی یک مدل پایه خوب که نیازهای ما را برآورده میکند
- پیشپردازش مجموعه داده
- تعریف معیارهای ارزیابی
- آموزش مدل
1- شناسایی مجموعه داده
بسته به مساله و مورد استفاده خود، میتوانید از یک مجموعه داده عمومی یا خصوصی (مثلاً یک مجموعه داده از شرکت خود) استفاده کنید. هدف تطبیق یک مدل زبانی بزرگ عمومی (که معمولا برای ادامه دادن متن استفاده میشود) برای وظیقهی طبقهبندی متن است که بدین منظور باید دستههایی که مورد نظرمان است را به آن آموزش دهیم. برخی از مکانهای خوب برای یافتن مجموعه دادههای عمومی، مجموعه دادههای Hugging Face، Kaggle، Zenodo و جستجوی مجموعه داده گوگل هستند.
از جمله مجموعه دادههای پر دانلود انگلیسی، مجموعه داده AG News است. این مجموعه داده یک مجموعه داده غیر تجاری شناخته شده که برای ارزیابی مدلهای طبقهبندی متن و تحقیق در زمینههای دادهکاوی، بازیابی اطلاعات و استریمینگ دادهها استفاده میشود.
اولین کار باید بررسی مجموعه داده باشد. همانطور که در زیر نشان داده شده است، مجموعه داده شامل دو ستون است: یک ستون متن و دیگری برچسب یا لیبل. مجموعه داده ذکر شده 120,000 نمونه آموزشی دارد که برای Fine-Tune یک مدل بیش از اندازه هم هست. Fine-Tune به دادههای بسیار کمی در مقایسه با آموزش اولیه مدل نیاز دارد و فقط با استفاده از چند هزار نمونه باید بتوانیم یک مدل پایه خوب را ایجاد کنیم.
from datasets import load_dataset
raw_datasets = load_dataset("ag_news")
raw_datasets
DatasetDict({
test: Dataset({
features: ['text', 'label'],
num_rows: 7600
})
train: Dataset({
features: ['text', 'label'],
num_rows: 120000
})
})
بیایید به یکی از نمونه ها نگاه کنیم:
raw_train_dataset = raw_datasets["train"] raw_train_dataset[0]
{'label': 2,
'text': 'Wall St. Bears Claw Back Into the Black (Reuters) Reuters '
"- Short-sellers, Wall Street's dwindling\\band of "
'ultra-cynics, are seeing green again.'}
اولین نمونه حاوی متن و یک برچسب است که برچسب آن 2 است؟ 2 به کدام کلاس اشاره دارد؟ برای فهمیدن این موضوع، میتوانیم به فیلد برچسب مجموعه داده خود نگاه کنیم:
print(raw_train_dataset.features)
{'label': ClassLabel(names=['World',
'Sports',
'Business',
'Sci/Tech'],
id=None),
'text': Value(dtype='string', id=None)}
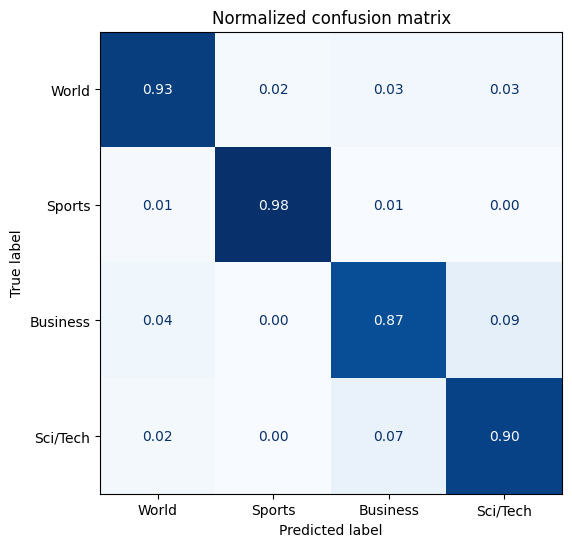
عالی! بنابراین برچسب یا لیبل 0 به معنای خبرهای مربوط به جهان، 1 به معنای خبرهای ورزشی، 2 به معنای خبرهای تجاری، و 3 به معنای خبرهای علمی و فناوری است. حال بیایید تصمیم بگیریم که از کدام مدل استفاده کنیم بهتر است!
{'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]),
'input_ids': tensor([[ 101, 2813, 2358, 1012, 6468, 15020, 2067, 2046,
1996, 2304, 1006, 26665, 1007, 26665, 1011, 2460,
1011, 19041, 1010, 2813, 2395, 1005, 1055, 1040,
11101, 2989, 1032, 2316, 1997, 11087, 1011, 22330,
8713, 2015, 1010, 2024, 3773, 2665, 2153, 1012,
102, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0],
[ 101, 18431, 2571, 3504, 2646, 3293, 13395, 1006,
26665, 1007, 26665, 1011, 2797, 5211, 3813, 18431,
2571, 2177, 1010, 1032, 2029, 2038, 1037, 5891,
2005, 2437, 2092, 1011, 22313, 1998, 5681, 1032,
6801, 3248, 1999, 1996, 3639, 3068, 1010, 2038,
5168, 2872, 1032, 2049, 29475, 2006, 2178, 2112,
1997, 1996, 3006, 1012, 102]])}
در این مثال، تابعtokenize_function() یک دسته یا batch از نمونهها را گرفته، آنها را با استفاده از توکنایزر DistilBERT توکنایز کرده و با استفاده از padding برای جملات کوچیکتر و truncation (برش دادن) برای جملات بزرگتر آنها را به اندازهی یکنواخت میرساند. همانطور که میبینید، عنصر اول کوتاهتر از عنصر دوم بود، بنابراین در انتهای خود چند توکن اضافی با شناسه 0 دارد. این صفرها مربوط به توکن [PAD] هستند که در طول استنتاج نادیده گرفته خواهند شد. توجه کنید که ماسک توجه(attention mask) برای این نمونه نیز در انتها 0 دارد که تضمین میکند که مدل فقط به توکنهای واقعی توجه کند.
حالا که توکنسازی را درک کردیم، میتوانیم از متد map برای توکنایز کردن کل مجموعه داده استفاده کنیم.
tokenized_datasets = raw_datasets.map(tokenize_function, batched=True) tokenized_datasets
DatasetDict({
test: Dataset({
features: ['text', 'label', 'input_ids', 'attention_mask'],
num_rows: 7600
})
train: Dataset({
features: ['text', 'label', 'input_ids', 'attention_mask'],
num_rows: 120000
})
})
5. تعریف معیارهای ارزیابی
علاوه بر نظارت بر کاهش خطا (loss)، معمولاً تعریف برخی از معیارهای پاییندستی که به ما اجازه میدهند فرایند آموزش را نظارت کنیم، ایده خوبی است. ما از کتابخانه evaluate استفاده خواهیم کرد که ابزاری مفید با یک رابط استاندارد برای معیارهای مختلف است. انتخاب معیارها بستگی به وظیفه یا مساله ما دارد. برای طبقهبندی دنبالهها، موارد زیر میتواند مناسب باشد:
- Accuracy: نسبت پیشبینیهای درست را نشان میدهد و یک نمای کلی از عملکرد مدل ارائه میدهد.
- Precision: نسبت نمونههای مثبت درست برچسبخورده به تمام موارد برچسبخورده به عنوان مثبت است. این معیار به ما در فهمیدن دقت پیشبینیهای مثبت کمک میکند.
- Recall: نسبت نمونههای مثبت واقعی که به درستی توسط مدل پیشبینی شدهاند. این معیار توانایی مدل در تشخیص تمام نمونههای مثبت را نشان میدهد و در صورتی که منفیهای کاذب وجود داشته باشند، پایینتر خواهد بود.
- F1 (F1 Score): میانگین Precisionو Recallاست و یک معیار متعادل ارائه میدهد که هم خطاهای مثبت کاذب و هم منفی کاذب را در نظر میگیرد.
معیارهای موجود در evaluate دارای یک ویژگیdescription(توضیحات) و یک متد compute() برای بهدست آوردن معیار با توجه به برچسبها و پیشبینیهای مدل هستند.
import evaluate
accuracy = evaluate.load("accuracy")
print(accuracy.description)
print(accuracy.compute(references=[0, 1, 0, 1], predictions=[1, 0, 0, 1]))
('Accuracy is the proportion of correct predictions among the total '
'number of cases processed. It can be computed with:\n'
'Accuracy = (TP + TN) / (TP + TN + FP + FN)\n'
' Where:\n'
'TP: True positive\n'
'TN: True negative\n'
'FP: False positive\n'
'FN: False negative\n')
f1_score = evaluate.load("f1")
def compute_metrics(pred): #1
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
# Compute F1 score and accuracy
f1 = f1_score.compute(
references=labels, predictions=preds, average="weighted"
)[
"f1"
] #2
acc = accuracy.compute(references=labels, predictions=preds)[
"accuracy"
] #3
return {"accuracy": acc, "f1": f1} #4
در کامنتهای کد بالا 4 جا از شماره 1 تا 4 مشخص شده که در پایین توضیحات آن آمده است:
- تابع
compute_metrics()انتظار دارد که یکEvalPredictionدریافت کند، که شامل برچسب و پیشبینیها است. - از
f1_scoreبارگذاری شده برای محاسبه نمره F1 بین برچسبها و پیشبینیها استفاده کنید. - این کار را برای دقت (accuracy) نیز تکرار کنید.
- در نهایت، هر دو معیار را با ساختن یک دیکشنری برگردانید.
6. آموزش مدل
وقت آن است که مدل را آموزش دهیم! اگر خاطرتان باشد DistilBERT یک مدل مبتنی بر انکودر است. اگر از مدل خام همانطور که هست استفاده کنیم، همانطور که در اینجا انجام دادیم embeddingهایی که به دست خواهیم آورد، بنابراین نمیتوانیم این مدل را به صورت مستقیم استفاده کنیم. برای طبقهبندی دنبالههای متنی، این embeddingها را به یک Head طبقهبندی میدهیم. وقتی fine-tune میکنیم، از embeddingهای ثابت استفاده نمیکنیم: تمام پارامترهای مدل، وزنهای اصلی و سر طبقهبندی قابل آموزش هستند. این سر embeddingها را به عنوان ورودی گرفته و احتمالات کلاسها را خروجی میدهد. چرا همه وزنها را آموزش میدهیم؟ با آموزش تمام پارامترها، کمک میکنیم embeddingها برای این وظیفه طبقهبندی خاص مفیدتر شوند.
اگرچه ما از یک شبکه feed-forward ساده استفاده خواهیم کرد، میتوانیم از شبکههای پیچیدهتر به عنوان سر یا حتی مدلهای کلاسیک مانند Logistic Regression یا Random Forests استفاده کنیم (در این صورت از مدل به عنوان استخراجکننده ویژگی استفاده میکنیم و وزنها را freeze میکنیم). استفاده از یک لایه ساده هم خوب کار میکند، و هم از نظر محاسباتی کارآمد بوده روش رایجی است.
نکته:
اگر در انتقال یادگیری در بینایی کامپیوتر تجربه دارید، ممکن است با مفهوم ثابت نگه داشتن وزنهای مدل پایه که اصطلاحا freeze کردن نیز گفته میشود آشنا باشید. این کار در NLP کمتر انجام میشود، زیرا هدف ما این است که نمایشهای زبان داخلی برای وظیفه پاییندستی مفیدتر شوند. در بینایی کامپیوتر، اغلب برخی لایهها ثابت نگه داشته میشوند زیرا ویژگیهای یادگرفته شده توسط مدل پایه عمومیتر و برای بسیاری از وظایف مفید هستند. برای مثال، برخی لایهها ویژگیهای عمومی مانند لبهها یا بافتها را دریافت میکنند که به طور گستردهای در وظایف بینایی کاربرد دارند. اینکه آیا لایهها freeze باشند یا نه به زمینه یا مساله بستگی دارد، از جمله موارد تاثیر گذار روی این تصمیم گیری میتوان به اندازه مجموعه داده، مقدار محاسبات و شباهت بین وظیفهی مدل پیشآموزش دیده و مساله جدید اشاره کرد. در ادامه، درباره تکنیکی به نام آداپترها (adapters) یاد خواهیم گرفت که به ما اجازه میدهد با LLMهای freeze شده کار کنیم.
برای آموزش مدل با Head طبقهبندی، میتوانیم از AutoModelForSequenceClassification استفاده کنیم، که همچنین نیاز به تعیین تعداد برچسبها دارد (تعداد نورونها در لایه آخر را تغییر میدهد).
import torch
from transformers import AutoModelForSequenceClassification
device = "cuda" if torch.cuda.is_available() else "cpu"
num_labels = 4
model = AutoModelForSequenceClassification.from_pretrained(
checkpoint, num_labels=num_labels
).to(device)
pp.pprint(
"""Some weights of DistilBertForSequenceClassification were not initialized from the model checkpoint at distilbert-base-uncased and are newly initialized: ['classifier.bias', 'classifier.weight', 'pre_classifier.bias', 'pre_classifier.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference."""
)
('Some weights of DistilBertForSequenceClassification were not '
'initialized from the model checkpoint at distilbert-base-uncased '
"and are newly initialized: ['classifier.bias', "
"'classifier.weight', 'pre_classifier.bias', "
"'pre_classifier.weight']\n"
'You should probably TRAIN this model on a down-stream task to be '
'able to use it for predictions and inference.')
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

دیدگاهتان را بنویسید