ترنسفورمر – بخش دوم
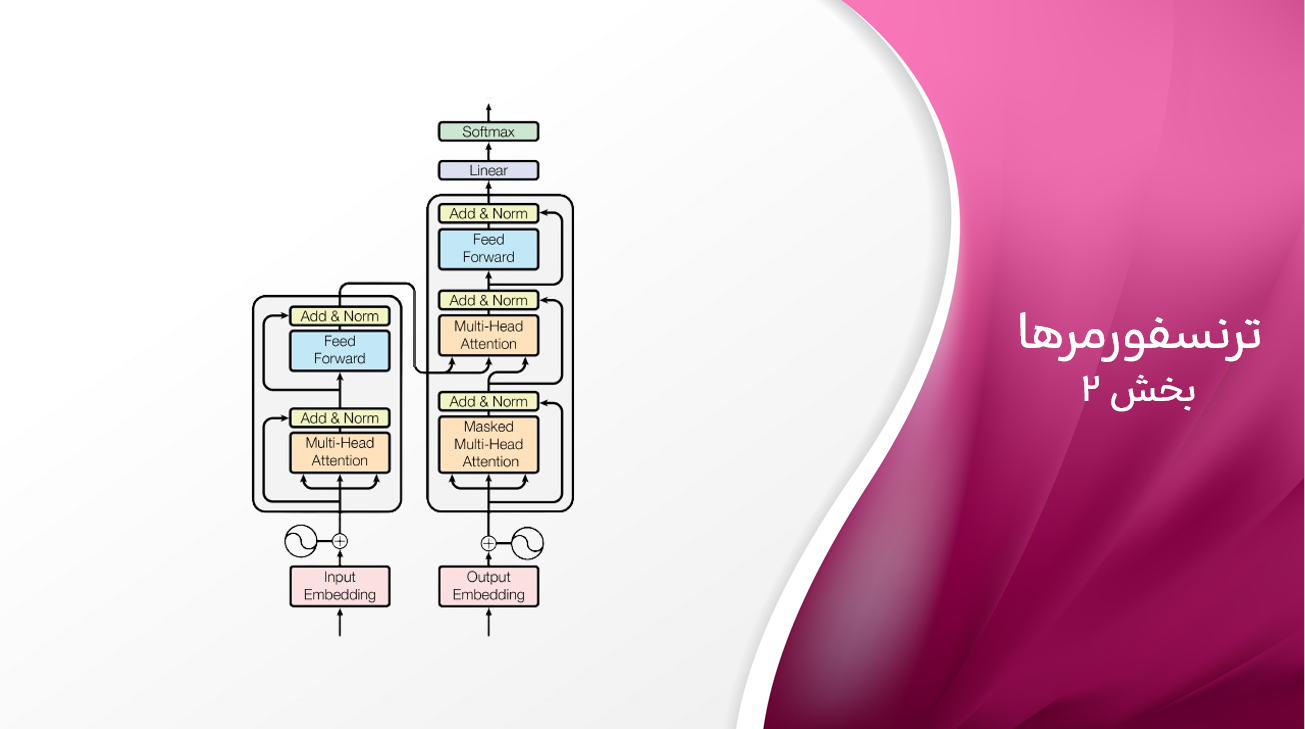
یک بلوک ترنسفورمر
بعد از آزمایشهای مختصر با مدلهای زبانی، آمادهایم تا یک نمودار معماری برای مدلهای تولید زبان مبتنی بر ترانسفورمر معرفی کنیم. اجزای اصلی شامل موارد زیر است:
- توکنسازی: متن ورودی به توکنهای جداگانه (که میتواند کلمات و زیرکلمات باشد) تجزیه میشود. هر توکن دارای یک شناسه متناظر است که برای شاخصگذاری توکنهای امبدینگ استفاده میشود.
- امبدینگ توکن ورودی: توکنها به صورت بردارهایی به نام امبدینگها نمایش داده میشوند. این امبدینگها به عنوان نمایشهای عددی عمل میکنند که معنای معنایی هر توکن را در بر میگیرند. میتوانید بردارها را به عنوان لیستی از اعداد تصور کنید، که هر عدد به جنبه خاصی از معنای توکن مربوط میشود. در طول آموزش، مدل یاد میگیرد که چگونه هر توکن را به امبدینگ متناظر آن نگاشت دهد. امبدینگ برای هر توکن همیشه ثابت است، بدون توجه به موقعیت آن در توالی ورودی.
- رمزگذاری موقعیتی: مدل ترنسفورمر هیچ مفهومی از ترتیب ندارد، بنابراین باید امبدینگهای توکن را با اطلاعات موقعیتی غنی کنیم. این کار با افزودن یک رمزگذاری موقعیتی به امبدینگهای توکن انجام میشود. رمزگذاری موقعیتی مجموعهای از بردارها است که موقعیت هر توکن در توالی ورودی را رمزگذاری میکند. این به مدل اجازه میدهد تا توکنها را بر اساس موقعیت آنها در توالی تشخیص دهد، که میتواند مفید باشد زیرا همان توکن در مکانهای مختلف میتواند معانی متفاوتی داشته باشد.
- بلوکهای ترنسفورمر: هسته مدل ترانسفورمر، بلوک ترانسفورمر است. قدرت ترنسفورمرها از چیدن چندین بلوک به دست میآید که به مدل اجازه میدهد روابط پیچیده و انتزاعی بین توکنهای ورودی را بیاموزد. این شامل دو جزء اصلی است:
- مکانیسم توجه به خود:
این مکانیسم به مدل اجازه میدهد تا اهمیت هر توکن را در زمینه کل توالی وزندهی کند. این به مدل کمک میکند تا روابط بین توکنهای مختلف در ورودی را درک کند. مکانیسم توجه به خود کلید توانایی ترانسفورمر در مدیریت وابستگیهای طولانیمدت و روابط پیچیده بین کلمات است و به تولید متن همگن و متناسب با زمینه کمک میکند. - شبکه عصبی Feed-Forward:
خروجی توجه به خود از طریق یک شبکه عصبی Feed-Forward عبور داده میشود که نمایش توالی ورودی را بیشتر تصحیح میکند.
- مکانیسم توجه به خود:
- امبدینگهای زمینهای (Contextual Embeddings): خروجی بلوک ترنسفورمر مجموعهای از امبدینگهای زمینهای است که روابط بین توکنها در توالی ورودی را در بر میگیرد. برخلاف امبدینگهای ورودی که برای هر توکن ثابت است، امبدینگهای زمینهای در هر لایه از مدل ترانسفورمر بر اساس روابط بین توکنها بهروزرسانی میشوند.
- پیشبینی: یک لایه اضافی نمایش نهایی را به خروجی نهایی وابسته به وظیفه پردازش میکند. در مورد تولید متن، این شامل داشتن یک لایه خطی است که امبدینگهای زمینهای را به فضای واژگانی نگاشت میدهد، و سپس یک عملیات softmax برای پیشبینی توکن بعدی در توالی انجام میدهد.
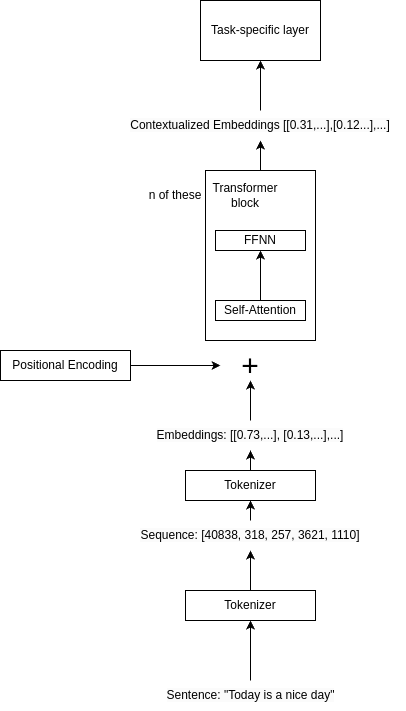
معماری یک مدل زبان مبتنی بر ترنسفورمر
البته، این سادهسازی معماری ترنسفورمر است. بررسی جزئیات نحوه کارکرد توجه-به-خود یا جزئیات بلوک ترنسفورمر در پستی جداگانه بحث خواهد شد. با این حال، درک معماری سطح بالا از یک مدل ترنسفورمر میتواند برای فهم چگونگی کارکرد این مدلها و نحوه استفاده آنها در وظایف مختلف مفید باشد. این معماری به ترنسفورمرها امکان دستیابی به عملکرد بیسابقه در وظایف و حوزههای مختلف را داده است.
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO
مقالهی Enhancing the Reasoning Ability of Multimodal Large Language Models...

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها
Min P، یک روش نمونهبرداری (sampling) جدید برای مدلهای زبانی...

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2
Fine-Tuning همانطور که در بخش قبلی (مدلهای انتشار (Diffusion Models)...

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 1
مدلهای انتشار (Diffusion Models) نسبتاً اخیراً به خانوادهای از الگوریتمها...
دیدگاهتان را بنویسید