ترنسفورمر – بخش سوم
نیاکان مدلهای ترنسفورمر
وظایف Sequence-To-Sequence
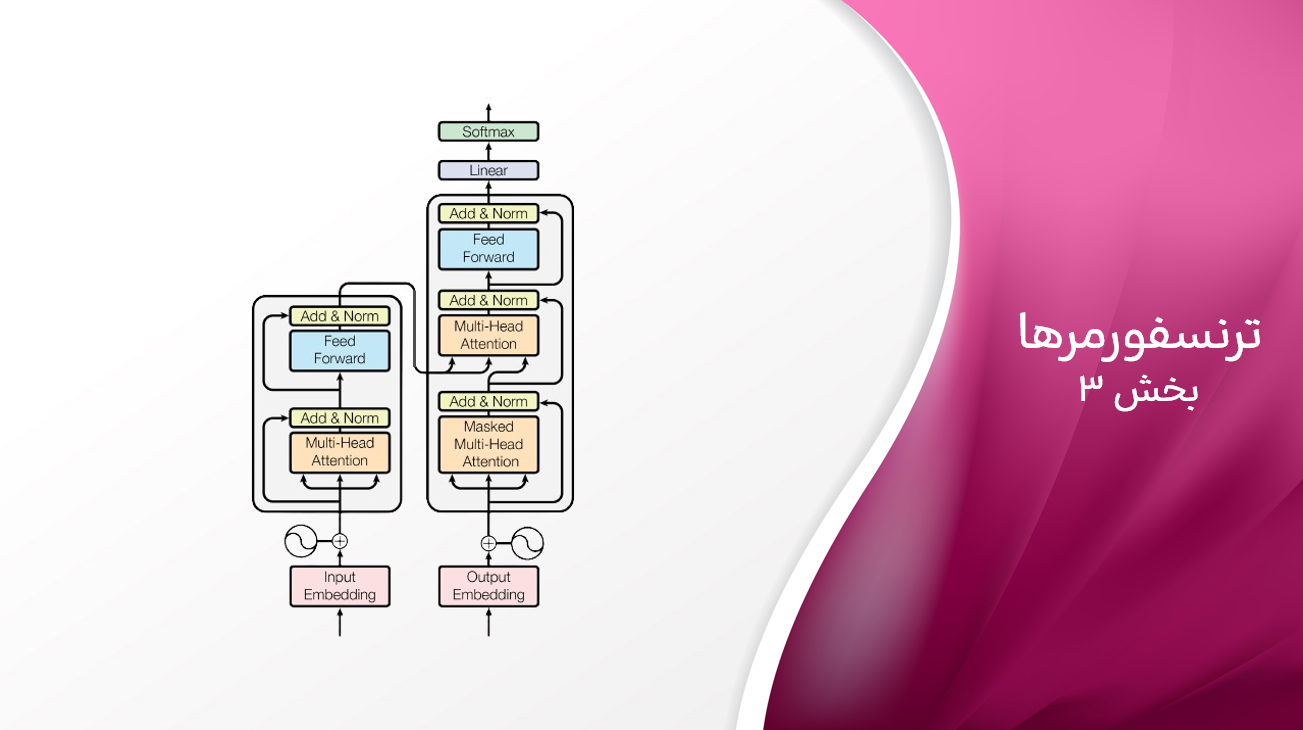
در ابتدای فصل، با GPT-2 برای تولید خودبازگشتی متن آزمایش کردیم. GPT-2، مثالی از یک ترنسفورمر مبتنی بر دیکودر، دارای یک پشته واحد از بلوکهای ترنسفورمر است که یک دنباله ورودی را پردازش میکند. این یک رویکرد محبوب امروزی است، اما مقاله اصلی ترنسفورمر، “توجه تمام چیزی است که نیاز دارید”، از معماری پیچیدهتری به نام معماری انکودر-دیکودر استفاده کرده بود که هنوز هم به طور گسترده مورد استفاده قرار میگیرد.
مقاله ترنسفورمر بر ترجمه ماشینی به عنوان مثال وظیفه Sequence-To-Sequence متمرکز بود. بهترین نتایج در ترجمه ماشینی در آن زمان توسط شبکههای عصبی بازگشتی (RNNs)، مانند LSTM و GRU، به دست آمده بود (نگران نباشید اگر با آنها آشنا نیستید). مقاله نشان داد که با تمرکز صرف بر روش توجه، نتایج بهتری حاصل میشود و نشان داد که مقیاسپذیری و آموزش بسیار آسانتر است. این عوامل – عملکرد عالی، آموزش پایدار و مقیاسپذیری آسان – دلایلی هستند که ترنسفورمرها به سرعت محبوب شدند و برای وظایف متعددی مورد استفاده قرار گرفتند، همانطور که بخش بعدی به طور عمیقتر به آن میپردازد.
در مدلهای انکودر-دیکودر، مانند مدل اصلی ترنسفورمر که در مقاله توصیف شده است، یک پشته از بلوکهای ترنسفورمر، به نام انکودر، یک دنباله ورودی را به مجموعهای از نمایشهای غنی پردازش میکند که سپس به پشته دیگری از بلوکهای ترنسفورمر، به نام دیکودر، منتقل میشوند که آنها را به یک دنباله خروجی دیکود میکند. این رویکرد برای تبدیل یک دنباله به دنباله دیگر به عنوان Sequence-To-Sequence شناخته میشود و به طور طبیعی برای وظایفی مانند ترجمه، خلاصهسازی یا پاسخ به سوال مناسب است.
برای مثال، شما یک جمله انگلیسی را از طریق انکودر یک مدل ترجمه وارد میکنید، که یک امبدینگ غنی تولید میکند که معنای ورودی را به تصویر میکشد. سپس، دیکودر با استفاده از این امبدینگ جمله متناظر فرانسوی را تولید میکند. تولید در دیکودر یک توکن در یک زمان اتفاق میافتد، همانطور که قبلاً در فصل دیدیم. با این حال، پیشبینی برای هر توکن متوالی نه تنها با توکنهای قبلی در دنبالهای که در حال تولید است، بلکه با خروجی انکودر نیز اطلاع داده میشود.
مکانیسمی که از طریق آن خروجی از سمت انکودر در پشته دیکودر وارد میشود، توجه متقاطع نامیده میشود. این شبیه به توجه به خود است، به جز اینکه هر توکن در ورودی (دنبالهای که توسط دیکودر پردازش میشود) به متن از انکودر توجه میکند به جای توکنهای دیگر در دنباله خود. لایههای توجه متقاطع با توجه به خود درهمتنیده شدهاند، که به دیکودر اجازه میدهد هم از متن در دنباله خود و هم از اطلاعات انکودر استفاده کند.
بعد از مقاله ترنسفورمر، مدلهای Sequence-To-Sequence موجود، مانند Marian NMT، این تکنیکها را به عنوان بخشی مرکزی از معماری خود به کار گرفتند. مدلهای جدیدی با استفاده از این ایدهها توسعه یافتند. یک مدل برجسته BART است (مخفف “Bidirectional and Auto-Regressive Transformers”). در طول پیشآموزش، BART دنبالههای ورودی را خراب میکند و تلاش میکند تا آنها را در خروجی دیکودر بازسازی کند. پس از آن، BART برای وظایف تولیدی دیگر، مانند ترجمه یا خلاصهسازی، با استفاده از نمایشهای غنی دنبالهای که در طول پیشآموزش به دست آمده است، بهینهسازی میشود. خراب کردن ورودی، به هر حال، یکی از ایدههای کلیدی پشت مدلهای انتشار است، همانطور که در فصل ۳ خواهیم دید.
یک مدل Sequence-To-Sequence برجسته دیگر T5 است. T5 به صورت عمومی به مجموعهای از وظایف پردازش زبان طبیعی (NLP) میپردازد با فرموله کردن ۶۰ وظیفه به عنوان تبدیلهای متن به متن. هیچ لایه یا کد سفارشی برای وظایف مختلف مورد نیاز نیست، آموزش با استفاده از همان هایپرپارامترها انجام میشود و مدل از یک مجموعه داده بسیار متنوع یاد میگیرد.
ما به تازگی درباره معماریهای انکودر-دیکودر و تنها دیکودر صحبت کردیم. یک سوال رایج این است که چرا برای وظایفی مانند ترجمه به یک مدل انکودر-دیکودر نیاز داریم اگر مدلهای تنها دیکودر مانند GPT-2 میتوانند نتایج خوبی نشان دهند. مدلهای انکودر-دیکودر برای ترجمه یک دنباله ورودی به یک دنباله خروجی طراحی شدهاند و آنها را برای ترجمه مناسب میکند. در مقابل، مدلهای تنها دیکودر بر پیشبینی توکن بعدی در یک دنباله تمرکز دارند. در ابتدا، مدلهای تنها دیکودر مانند GPT-2 در سناریوهای یادگیری بدون شات کمتر توانمند بودند نسبت به مدلهای جدیدتری مانند GPT-3، اما این تنها به دلیل نبود انکودر نبود. بهبود قابلیتهای بدون شات در مدلهای پیشرفتهای مانند GPT-3 نیز به دلیل دادههای آموزشی بزرگتر، تکنیکهای آموزشی بهتر و اندازه مدلهای بزرگتر است. در حالی که انکودرها در مدلهای seq2seq نقش حیاتی در درک متن کامل دنبالههای ورودی ایفا میکنند، پیشرفتها در مدلهای تنها دیکودر آنها را موثرتر و متنوعتر ساخته است، حتی برای وظایفی که به طور سنتی به مدلهای seq2seq وابسته بودند.
مدلهای فقط انکودر
همانطور که دیدیم، مدل اصلی ترنسفورمر بر اساس معماری انکودر-دیکودر بود که در مدلهایی مانند BART یا T5 بیشتر مورد بررسی قرار گرفت. علاوه بر این، انکودر یا دیکودر میتوانند به صورت مستقل آموزش دیده و استفاده شوند، که منجر به ایجاد خانوادههای مختلف ترنسفورمر میشود. بخشهای اول این فصل مدلهای فقط دیکودر یا خودبازگشتی را بررسی کردند. این مدلها در تولید متن با استفاده از تکنیکهایی که توضیح دادیم تخصص دارند و عملکرد چشمگیری نشان دادهاند، همانطور که توسط ChatGPT، Claude، Llama یا Falcon مشاهده شده است.
مدلهای انکودر، از سوی دیگر، در بدست آوردن نمایشهای غنی از دنبالههای متنی تخصص دارند و میتوانند برای وظایفی مانند طبقهبندی یا آمادهسازی امبدینگهای معنایی (معمولاً یک بردار متشکل از چند صد عدد) برای مجموعهای از اسناد که میتوانند در سیستمهای بازیابی استفاده شوند، مورد استفاده قرار گیرند. شناختهشدهترین مدل انکودر ترنسفورمر احتمالاً BERT است که مدل زبانی ماسک (MLM) را معرفی کرد که بعدها توسط BART مورد استفاده و بررسی بیشتر قرار گرفت.
مدلسازی زبان علی پیشبینی توکن بعدی را با توجه به توکنهای قبلی انجام میدهد – این همان چیزی است که ما با GPT-2 انجام دادیم. مدل فقط میتواند به متن در سمت چپ یک توکن داده شده توجه کند. رویکرد متفاوتی که در مدلهای انکودر استفاده میشود مدل زبانی ماسک (MLM) نامیده میشود. مدل زبان ماسک که در مقاله معروف BERT پیشنهاد شد، مدلی را پیشآموزش میدهد تا “جاهای خالی را پر کند”. با توجه به یک متن ورودی، ما به صورت تصادفی برخی توکنها را میپوشانیم و مدل باید توکنهای مخفی را پیشبینی کند. برخلاف مدلسازی زبان علی، MLM از دنباله در سمت چپ و راست توکن ماسک استفاده میکند، به همین دلیل حرف B در نام BERT به معنای bidirectional (“دو جهته”) است. این کمک میکند تا نمایشهای قوی از متن داده شده ایجاد شود. در پشت صحنه، این مدلها از بخش انکودر معماری ترنسفورمر استفاده میکنند.
from transformers import pipeline
fill_masker = pipeline(model="bert-base-uncased")
fill_masker("The [MASK] is made of milk.")
[{'score': 0.19546695053577423,
'token': 9841,
'token_str': 'dish',
'sequence': 'the dish is made of milk.'},
{'score': 0.1290755718946457,
'token': 8808,
'token_str': 'cheese',
'sequence': 'the cheese is made of milk.'},
{'score': 0.10590697824954987,
'token': 6501,
'token_str': 'milk',
'sequence': 'the milk is made of milk.'},
{'score': 0.04112089052796364,
'token': 4392,
'token_str': 'drink',
'sequence': 'the drink is made of milk.'},
{'score': 0.03712352365255356,
'token': 7852,
'token_str': 'bread',
'sequence': 'the bread is made of milk.'}]
چه اتفاقی در پشت صحنه میافتد؟ انکودر دنباله ورودی را دریافت کرده و یک نمایش بافتاری برای هر توکن ایجاد میکند. این نمایش یک بردار از اعداد است که معنای توکن را در بافت کل دنباله به تصویر میکشد. معمولاً بعد از انکودر یک لایه خاص وظیفه وجود دارد که از این نمایشها برای انجام وظایفی مانند طبقهبندی، پاسخ به سوالات یا مدلسازی زبان ماسک شده استفاده میکند. انکودر به گونهای آموزش دیده است که نمایشهایی ایجاد کند که برای وظایف نیازمند فهم عمیق مفید باشند.
بین مدلهای فقط انکودر، فقط دیکودر و انکودر-دیکودر، ما تعداد زیادی مدل زبان جدید باز و بسته را مشاهده کردهایم، مانند GPT-4، Mistral، Falcon، Llama 2، Qwen، Yi، Claude، Bloom، PaLM و صدها مدل دیگر. یان لکان در توییتر (https://twitter.com/i/web/status/1651762787373428736) این نمودار تبارشناسی جذاب را که از یک مقاله مروری گرفته شده، به اشتراک گذاشته است و نشان میدهد که ترنسفورمرها چه تاثیر غنی و ثمربخشی بر چشمانداز پردازش زبان طبیعی تا سال 2024 داشتهاند.
قدرت پیشآموزش
نکات کلیدی ترنسفورمرها
دسترسی به مدلهای موجود بسیار قدرتمند است. در بخشهای قبلی، ما از GPT-2 و GPT-NeoX برای تولید متن و انجام طبقهبندی صفر-شات استفاده کردیم. مدلهای ترنسفورمر در بسیاری از وظایف زبانی دیگر، مانند طبقهبندی متن، ترجمه ماشینی و پاسخ به سوالات بر اساس متن ورودی، عملکرد برتر داشتهاند. چرا ترنسفورمرها اینقدر خوب عمل میکنند؟
نکتهی اول استفاده از مکانیزم توجه (attention) است، همانطور که در مقدمه فصل اشاره شد. روشهای NLP قبلی، مانند شبکههای عصبی بازگشتی (RNN)، در مدیریت جملات طولانی مشکل داشتند. مکانیزمهای توجه به مدل ترنسفورمر اجازه میدهند تا به دنبالههای طولانی توجه کند و روابط بلندمدت را یاد بگیرد. به عبارت دیگر، ترنسفورمرها میتوانند تخمین بزنند که برخی توکنها چقدر به توکنهای دیگر مرتبط هستند.
نکتهی کلیدی دوم قابلیت مقیاسپذیری آنها است. معماری ترنسفورمر به گونهای بهینهسازی شده است که امکان موازیسازی را فراهم میکند و تحقیقات نشان دادهاند که این مدلها میتوانند برای مدیریت دادههای پیچیده و بزرگ مقیاس بگیرند. اگرچه ابتدا برای دادههای متنی طراحی شده بودند، معماری ترنسفورمر به اندازه کافی انعطافپذیر است که از انواع مختلف دادهها پشتیبانی کند و ورودیهای نامنظم را مدیریت کند.
سومین نکتهی کلیدی قابلیت پیشآموزش و تنظیم دقیق (fine-tuning) است. رویکردهای سنتی برای یک وظیفه، مانند طبقهبندی نظرات فیلم، به میزان در دسترس بودن دادههای برچسبگذاری شده محدود بود. یک مدل از ابتدا با یک مجموعه بزرگ از نمونههای برچسبگذاری شده آموزش داده میشد و تلاش میکرد تا برچسب را از متن ورودی به طور مستقیم پیشبینی کند. این رویکرد اغلب به عنوان یادگیری نظارت شده شناخته میشود. اما این رویکرد یک نقص بزرگ دارد: برای آموزش موثر نیاز به مقدار زیادی داده برچسبگذاری شده دارد. این مشکل است زیرا دادههای برچسبگذاری شده گران است و زمان زیادی برای برچسبگذاری نیاز دارد. در بسیاری از حوزهها ممکن است حتی دادههای در دسترس وجود نداشته باشد.
برای حل این مشکل، محققان به دنبال راهی بودند تا مدلها را بر روی دادههای موجود پیشآموزش دهند و سپس آنها را برای یک وظیفه خاص تنظیم دقیق کنند. این رویکرد به عنوان یادگیری انتقالی شناخته میشود و پایه و اساس یادگیری ماشین مدرن در بسیاری از زمینهها مانند پردازش زبان طبیعی و بینایی کامپیوتر است. کارهای اولیه در NLP بر یافتن مجموعه دادههای خاص حوزه برای مرحله پیشآموزش مدل زبان تمرکز داشتند، اما مقالاتی مانند ULMFiT نشان دادند که حتی پیشآموزش بر روی متن عمومی مانند ویکیپدیا میتواند نتایج چشمگیری بدهد هنگامی که مدلها بر روی وظایف پاییندستی مانند تحلیل احساسات یا پاسخ به سوال تنظیم دقیق شوند. این باعث شد که ترنسفورمرها به خوبی برای یادگیری نمایشهای غنی از زبان مناسب شوند.
ایده پیشآموزش این است که یک مدل را بر روی یک مجموعه داده بزرگ و بدون برچسب آموزش دهیم و سپس آن را برای یک وظیفه جدید هدف تنظیم دقیق کنیم که نیاز به دادههای برچسبگذاری شده کمتری خواهد داشت. قبل از فارغالتحصیلی به NLP، یادگیری انتقالی با شبکههای عصبی پیچشی که ستون فقرات بینایی کامپیوتری مدرن هستند بسیار موفق بود. در این سناریو، ابتدا یک مدل بزرگ را با مقدار زیادی از تصاویر برچسبگذاری شده در یک وظیفه طبقهبندی آموزش میدهیم. از طریق این فرآیند، مدل ویژگیهای مشترکی را یاد میگیرد که میتوان آنها را در یک مشکل متفاوت اما مرتبط استفاده کرد. به عنوان مثال، میتوانیم یک مدل را بر روی هزاران کلاس پیشآموزش دهیم و سپس آن را برای طبقهبندی اینکه آیا یک تصویر از یک هات داگ است یا نه تنظیم دقیق کنیم.
با ترنسفورمرها، کارها با پیشآموزش خود-نظارتی پیش میرود. ما میتوانیم یک مدل را بر روی دادههای متنی بزرگ و بدون برچسب پیشآموزش دهیم. چگونه؟ بیایید به مدلهای علّی مانند GPT فکر کنیم. مدل پیشبینی میکند که کلمه بعدی چیست. خوب، ما به هیچ برچسبی برای به دست آوردن دادههای آموزشی نیاز نداریم. با توجه به یک مجموعه متنی، میتوانیم توکنها را بعد از یک دنباله ماسک کنیم و مدل را آموزش دهیم تا یاد بگیرد آنها را پیشبینی کند. مانند حالت بینایی کامپیوتری، پیشآموزش به مدل یک نمایش معنادار از متن زیرین میدهد. سپس میتوانیم مدل را تنظیم دقیق کنیم تا وظیفه دیگری انجام دهد، مانند تولید متن به سبک توییتهای ما یا یک حوزه خاص (مثلاً چت شرکت شما). با توجه به اینکه مدل قبلاً یک نمایش از زبان را یاد گرفته است، تنظیم دقیق به دادههای کمتری نیاز خواهد داشت نسبت به حالتی که از ابتدا آموزش داده شود.
برای بسیاری از وظایف، یک نمایش غنی از ورودی مهمتر از توانایی پیشبینی توکن بعدی است. به عنوان مثال، اگر بخواهید یک مدل را برای پیشبینی احساسات یک نقد فیلم تنظیم دقیق کنید، مدلهای زبان ماسک شده قدرتمندتر خواهند بود. مدلهایی مانند GPT-2 برای بهینهسازی تولید متن طراحی شدهاند نه برای ساختن نمایشهای قدرتمند از متن. از طرف دیگر، مدلهایی مانند BERT برای این وظیفه ایدهآل هستند. همانطور که قبلاً اشاره شد، لایه آخر یک مدل انکودر یک نمایش متراکم از دنباله ورودی به نام امبدینگ خروجی میدهد. این امبدینگ را میتوان با افزودن یک شبکه ساده کوچک روی انکودر و تنظیم دقیق مدل برای وظیفه خاص استفاده کرد. به عنوان یک مثال مشخص، میتوانیم یک لایه خطی ساده روی خروجی انکودر BERT اضافه کنیم تا احساسات یک سند را پیشبینی کنیم. میتوانیم از این رویکرد برای انجام طیف وسیعی از وظایف استفاده کنیم:
– طبقهبندی توکن. شناسایی هر موجودیت در یک جمله، مانند شخص، مکان یا سازمان.
– پاسخدهی به سوال استخراجی. با توجه به یک پاراگراف، به یک سوال خاص پاسخ داده و پاسخ را از ورودی استخراج کنیم.
– جستجوی معنایی. ویژگیهای تولید شده توسط انکودر میتوانند برای ساخت یک سیستم جستجو مفید باشند. با توجه به یک پایگاه داده از صدها سند، میتوانیم امبدینگها را برای هر یک محاسبه کنیم. سپس میتوانیم امبدینگهای ورودی را با امبدینگهای اسناد در زمان استنتاج مقایسه کنیم و بدین ترتیب سندی که بیشترین شباهت را در پایگاه داده دارد شناسایی کنیم.
و بسیاری وظایف دیگر، از جمله شباهت متنی، شناسایی ناهنجاری، لینکدهی موجودیت نامگذاری شده، سیستمهای توصیهگر و طبقهبندی سند.
from transformers import pipeline
classifier = pipeline(model="distilbert-base-uncased-finetuned-sst-2-english")
classifier("This movie is disgustingly good !")
[{'label': 'POSITIVE', 'score': 0.9998536109924316}]
این مدل طبقهبندی میتواند نقدها را تجزیه و تحلیل کرده و همان کاری که در بخش طبقهبندی Zero-Shot انجام داده است را انجام دهد.
جمع بندی ترنسفورمرها
ما سه نوع معماری مختلف را مورد بحث قرار دادهایم.
- معماریهای مبتنی بر انکودر، مانند BERT، DistilBERT، و RoBERTa، برای وظایفی که نیاز به درک کامل ورودی دارند، ایدهآل هستند. این مدلها امبدینگهای متنی را خروجی میدهند که معنای دنباله ورودی را به تصویر میکشند. سپس میتوانیم شبکه کوچکی را بر روی این امبدینگها اضافه کرده و آن را برای وظیفه جدیدی که به اطلاعات معنایی وابسته است (مانند شناسایی موجودیتها در متن یا طبقهبندی دنباله) آموزش دهیم.
- معماریهای مبتنی بر دیکودر، مانند GPT-2، Falcon، و Llama، برای تولید متن جدید ایدهآل هستند.
- معماریهای انکودر-دیکودر، یا seq2seq، مانند BART و T5، برای وظایفی که نیاز به تولید جملات جدید بر اساس ورودی دارند، مانند خلاصهسازی یا ترجمه، بسیار مناسب هستند.
شاید بگویید: “صبر کن. من میتوانم همه این وظایف را با ChatGPT یا Llama انجام دهم”. این درست است – با توجه به مقدار زیاد (و در حال افزایش) دادههای آموزشی، محاسبات، و بهینهسازیهای آموزشی، کیفیت مدلهای تولیدی به طور قابل توجهی افزایش یافته و قابلیتهای zero-shot به طور ملاحظهای نسبت به چند سال پیش بهبود یافتهاند. اگرچه مدلهای فقط دیکودر نتایج خوبی ارائه میدهند، توافق فعلی این است که با داشتن منابع، fine-tuning یک مدل برای وظیفه و دامنه خاص شما بهتر از استفاده از یک مدل از پیش آموزشدیده است. به عنوان مثال، اگر میخواهید از یک مدل GPT به طور بلادرنگ (real-time) در یک بازی برای تولید دیالوگهای شخصیتها استفاده کنید، معمولاً اگر ابتدا آن را با دادههای مشابه fine-tune کنید عملکرد بهتری خواهد داشت . اگر میخواهید از یک مدل برای استخراج موجودیتهای مختلف از مجموعه دادههای مقالات شیمی خود استفاده کنید، ممکن است منطقی باشد که ابتدا یک مدل مبتنی بر انکودر را با مقالات شیمی fine-tune کنید تا به این هدف برسید.
موفقیت مدلهای seq2seq نتیجه توانایی آنها در کدگذاری دنبالههای ورودی با طول متغیر به یک امبدینگ است که اطلاعات ورودی را خلاصه میکند. بخش دیکودر مدل میتواند از این زمینه برای انجام تولید استفاده کند. مدلهای فقط دیکودر در سالهای اخیر به دلیل سادگی، مقیاسپذیری، کارایی و موازیسازی مورد توجه قرار گرفتهاند. سه نوع مدل به طور گستردهای در صنعت بسته به وظیفه استفاده میشوند – هیچ مدل طلایی وجود ندارد که برای همه چیز استفاده شود.
با داشتن بیش از نیم میلیون مدل در دسترس، ممکن است برایتون سوال بشود که کدام یک را باید استفاده کنید. در پستهای بعدی راهنماییهایی در مورد چگونگی انتخاب مدل مناسب برای وظیفه و نیازهای شما ارائه خواهم کرد و همچنین نحوه fine-tuning یک مدل برای نیازهای خاص شما بیان میگردد.
محدودیتها
حال ممکن است بعد این همه خوبی، براتون سول پیش بیاد مشکلات ترنسفورمرها چیست. بیایید به طور خلاصه به برخی از محدودیتها بپردازیم:
- ترنسفورمرها بسیار بزرگ هستند. تحقیقات مداوم نشان داده که مدلهای بزرگتر عملکرد بهتری دارند. اگرچه این بسیار هیجانانگیز است، اما همچنین نگرانیهایی را به همراه دارد. اول، برخی از قدرتمندترین مدلها به دهها میلیون دلار نیاز دارند – فقط برای قدرت محاسباتی. این بدان معناست که تنها مجموعه کوچکی از مؤسسات میتوانند مدلهای پایه بسیار بزرگ را آموزش دهند، که نوع تحقیقاتی را که مؤسسات بدون آن منابع میتوانند انجام دهند محدود میکند. دوم، استفاده از چنین میزان قدرت محاسباتی میتواند پیامدهای اکولوژیکی نیز داشته باشد – آن میلیونها ساعت GPU، البته، با مقدار زیادی برق تأمین میشوند. سوم، حتی اگر برخی از این مدلها منبع باز شوند، اجرای آنها ممکن است به تعداد زیادی GPU نیاز داشته باشد.
- پردازش ترتیبی: اگر به یاد بیاورید، در بخش دیکودر باید تمام توکنهای قبلی را برای هر توکن جدید پردازش کنیم. این بدان معناست که تولید توکن 10,000ام در یک دنباله به طور قابل توجهی بیشتر از تولید توکن اولیه زمان خواهد برد. از نظر علوم کامپیوتر، ترنسفورمرها دارای پیچیدگی زمانی درجه دو با توجه به طول ورودی هستند. این بدان معناست که با افزایش طول ورودی، زمان پردازش به صورت درجه دو افزایش مییابد، که این موضوع مقیاسپذیری آنها به مستندات بسیار طولانی یا استفاده از این مدلها در برخی سناریوهای زمان واقعی را چالش برانگیز میکند. در حالی که ترنسفورمرها در بسیاری از وظایف برتری دارند، نیازهای محاسباتی آنها نیاز به توجه دقیق و بهینهسازی هنگام استفاده در تولید دارند. با این وجود، تحقیقات زیادی برای کارآمدتر کردن ترنسفورمرها برای دنبالههای بسیار طولانی انجام شده است.
- اندازه ورودی ثابت: مدلهای ترنسفورمر میتوانند حداکثر تعداد مشخصی توکن را مدیریت کنند، که این به مدل پایه بستگی دارد. برخی ترنسفورمرها تنها میتوانند 512 توکن را مدیریت کنند، در حالی که تکنیکهای جدید اجازه مقیاسپذیری به صدها هزار توکن را میدهند. تعداد توکنهایی که مدل میتواند به آنها توجه کند، به عنوان پنجره زمینه شناخته میشود. این نکتهای اساسی است که هنگام انتخاب یک مدل از پیش آموزشدیده باید به آن توجه کنید. نمیتوانید به سادگی کتابهای کامل را به ترنسفورمرها بدهید و انتظار داشته باشید که بتوانند آنها را خلاصه کنند.
- محدودیت تفسیرپذیری: ترنسفورمرها اغلب به دلیل کمبود تفسیرپذیری مورد انتقاد قرار میگیرند.
همه موارد فوق زمینههای پژوهشی بسیار فعالی هستند – افراد در حال کاوش چگونگی آموزش و اجرای مدلها با توان محاسباتی کمتر (مثلاً QLoRA)، سریعتر کردن تولید (مثلاً flash attention و تولید کمک شده:assisted generation)، امکان ورودیهای بدون محدودیت (مثلاً RoPE و attention sinks) و تفسیر مکانیزمهای توجه هستند.
یکی از نگرانیهای بزرگ که نیاز به بررسی دارد، وجود سوگیریها در مدلها است. اگر دادههای آموزشی استفاده شده برای آموزش ترنسفورمرها حاوی سوگیریها باشد، مدل میتواند آنها را یاد بگیرد و تداوم بخشد. این یک مسئله گستردهتر در یادگیری ماشینی است، اما برای ترنسفورمرها نیز مرتبط است. فرض کنید میخواهیم محتملترین شغل را پیشبینی کنیم. همانطور که در زیر میبینید، نتایج با استفاده از کلمه “مرد” در مقابل “زن” بسیار متفاوت است.
unmasker = pipeline("fill-mask", model="bert-base-uncased")
result = unmasker("This man works as a [MASK] during summer.")
print([r["token_str"] for r in result])
result = unmasker("This woman works as a [MASK] during summer.")
print([r["token_str"] for r in result])
['farmer', 'carpenter', 'gardener', 'fisherman', 'miner'] ['maid', 'nurse', 'servant', 'waitress', 'cook']
چرا این اتفاق میافتد؟ برای این که pre-training امکانپذیر گردد، محققان معمولاً به مقادیر زیادی داده نیاز دارند که منجر به جمعآوری تمام محتوای موجود میشود. این محتوا ممکن است شامل انواع کیفیتها از جمله محتوای سمی (که تا حدی میتوان آن را فیلتر کرد) باشد. مدل پایه ممکن است در نهایت این سوگیریها را در طول فرآیند fine-tune کردن جذب کرده و ادامه دهد. نگرانیهای مشابهی برای مدلهای مکالمهای نیز وجود دارد، جایی که مدل نهایی ممکن است محتوای سمی تولید کند که از مجموعه دادههای پیشآموزش یاد گرفته است.
ترنسفورمر برای داده غیر متنی
ترنسفورمرها برای بسیاری از وظایف که دادهها را به صورت متن نشان میدهند، استفاده شدهاند. یک مثال واضح تولید کد است – به جای آموزش یک مدل زبان با دادههای انگلیسی، میتوانیم از مقادیر زیادی کد استفاده کنیم و با همان اصولی که یاد گرفتیم، مدل یاد خواهد گرفت که چگونه کد را به صورت خودکار کامل کند. مثال دیگر استفاده از ترنسفورمرها برای پاسخ دادن به سوالات از یک جدول، مانند یک صفحه وب است.
از آنجا که مدلهای ترنسفورمر در حوزه متن بسیار موفق بودهاند، علاقه زیادی برای تطبیق این تکنیکها به سایر مدالیتهها جلب شده است. این منجر به استفاده از مدلهای ترنسفورمر برای وظایفی مانند تشخیص تصویر، بخشبندی، تشخیص اشیاء، درک ویدیو و موارد دیگر شده است.
شبکههای عصبی کانولوشنی به طور گسترده به عنوان مدلهای پیشرفته برای بیشتر تکنیکهای بینایی کامپیوتری استفاده شدهاند. با معرفی ترنسفورمرهای بینایی (ViT)، در سالهای اخیر تحولی در نحوه مواجهه با وظایف بینایی با استفاده از تکنیکهای مبتنی بر توجه و ترنسفورمرها رخ داده است. ViTها به طور کامل از CNNها صرفنظر نمیکنند: در فرآیند پردازش تصویر، CNNها نقشههای ویژگی تصویر را استخراج میکنند تا لبههای سطح بالا، بافتها و الگوهای دیگر را تشخیص دهند. نقشههای ویژگی به دست آمده از CNNها سپس به تکههای ثابت و بدون همپوشانی تقسیم میشوند. این تکهها میتوانند به صورت مشابه با یک توالی از توکنها در نظر گرفته شوند، بنابراین مکانیزم توجه میتواند روابط بین تکهها را در مکانهای مختلف بیاموزد.
متاسفانه، ViTها برای دستیابی به نتایج خوب به دادهها (300 میلیون تصویر!) و محاسبات بیشتری نسبت به CNNها نیاز داشتند. کارهای بیشتری در سالهای اخیر انجام شده است؛ برای مثال، DeiT توانست از مدلهای مبتنی بر ترنسفورمر با مجموعه دادههای متوسط (1.2 میلیون تصویر) استفاده کند، به لطف استفاده از تکنیکهای افزایشی و تنظیمی که در CNNها رایج هستند. DeiT همچنین از یک رویکرد تقطیر استفاده میکند که شامل یک مدل “معلم” (در این مورد یک CNN) است. مدلهای دیگری مانند DETR، SegFormer و Swin Transformer نیز این حوزه را به جلو بردهاند، از بسیاری از وظایف مانند طبقهبندی تصویر، تشخیص اشیاء، بخشبندی تصویر، طبقهبندی ویدیو، درک سند، بازسازی تصویر، افزایش وضوح و غیره پشتیبانی میکنند.
ترنسفورمر همچنین میتوانند برای وظایف صوتی استفاده شوند، مانند رونویسی صدا یا تولید گفتار یا موسیقی مصنوعی. در پسزمینه، همان اصول بنیادی پیشآموزشی و مکانیزمهای توجه باقی میمانند، اما هر مدالیته دادههای مختلفی دارد که نیازمند رویکردها و تغییرات مختلفی است.
مدالیتههای دیگری که ترنسفورمرها در آنها مورد بررسی قرار میگیرند عبارتند از:
- گرافها: یک مطالعه مقدماتی عالی Introduction to Graph Machine Learning اثر Fourrier, 2023 است. استفاده از ترنسفورمرها برای گرافها هنوز در مراحل ابتدایی است، اما نتایج اولیه هیجانانگیزی وجود دارد. برخی از مثالهای وظایفی که شامل دادههای گراف هستند، پیشبینی سمی بودن مولکولها، پیشبینی تکامل سیستمها یا تولید مولکولهای جدید ممکن است.
- دادههای سهبعدی: برای مثال، انجام بخشبندی دادههایی که میتوانند به صورت سهبعدی نمایش داده شوند، مانند ابرهای نقطهای LiDAR در رانندگی خودکار یا اسکنهای CT برای بخشبندی اعضا. مثال دیگر تخمین 6 درجه آزادی یک جسم است که میتواند در برنامههای رباتیک مفید باشد.
- سریهای زمانی: تحلیل قیمت سهام یا پیشبینی آب و هوا.
- چندمدالیته: برخی از مدلهای ترنسفورمر برای پردازش چند نوع داده (مانند متن، تصاویر و صدا) طراحی شدهاند. این امکانها جدیدی را باز میکند، مانند سیستمهای چندمدالیته که میتوانید صحبت کنید، بنویسید یا تصاویر ارائه دهید و یک مدل واحد برای پردازش آنها داشته باشید. مثال دیگر پاسخگویی به سوالات بصری است، که یک مدل میتواند به سوالات درباره تصاویر ارائه شده پاسخ دهد.
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

دیدگاهتان را بنویسید