بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

مقالهی Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization پژوهشی درباره بهبود توانایی استدلال مدلهای زبان بزرگ چندوجهی (MLLMs) است و یک فرآیند بهینهسازی ترجیحی جدید به نام بهینهسازی ترجیحی ترکیبی (MPO) را معرفی میکند. نویسندگان برای مقابله با محدودیتهای مدلهای موجود در استدلال زنجیرهفکر (CoT)، یک مجموعه داده با کیفیت بالا به نام MMPR (شامل تقریباً ۳ میلیون نمونه) را با استفاده از یک فرایند ساخت داده خودکار ایجاد کردند. روش MPO، که ترکیبی از از ترجیح، کیفیت و تولید است، به طور قابل توجهی عملکرد استدلال مدلهای InternVL2-8B و InternVL2-76B را بهبود میبخشد، به طوری که مدل کوچکتر InternVL2-8B-MPO به نتایجی در بنچمارک MathVista دست مییابد که قابل مقایسه با مدل ۱۰ برابر بزرگتر است. در ادامه این مقاله بحث شده است.
مقدمه: پارادوکس تفکر در هوش مصنوعی
این یک باور رایج است که «فکر کردن گام به گام» همیشه به نتایج بهتری منجر میشود. اما در دنیای پیچیده هوش مصنوعی، شهود ما همیشه درست از آب درنمیآید. یک پارادوکس شگفتانگیز در مدلهای زبان چندوجهی (MLLMs) – هوش مصنوعیهایی که هم متن و هم تصویر را درک میکنند – وجود دارد: گاهی اوقات، وادار کردن آنها به استدلال مرحله به مرحله (که به آن «زنجیره تفکر» یا CoT میگویند) در واقع عملکردشان را بدتر میکند.
این کشف غیرمنتظره، محققان را به مسیری جدید هدایت کرد. آنها نه تنها دلیل این پدیده عجیب را کشف کردهاند، بلکه راهحلی هوشمندانه به نام «بهینهسازی ترجیحی ترکیبی» (MPO) ابداع کردهاند. این روش جدید چنان نتایج شگفتانگیزی به همراه داشته که به یک مدل چابک ۸ میلیارد پارامتری اجازه میدهد تا با برادر غولپیکر ۷۶ میلیارد پارامتری خود، شانه به شانه رقابت کند.
۱. مشکل شگفتانگیز: وقتی «فکر کردن» هوش مصنوعی را ضعیفتر میکند
استدلال «زنجیره تفکر» (Chain-of-Thought یا CoT) فرآیندی است که در آن از هوش مصنوعی خواسته میشود تا قبل از دادن پاسخ نهایی، مراحل کار و استدلال خود را نشان دهد. این روش معمولاً برای بهبود دقت در وظایف پیچیده استفاده میشود. اما دادهها داستان دیگری را روایت میکنند.
در نمودار زیر، تمام مدلهایی که زیر خط ۴۵ درجه قرار دارند نشان میدهند که حالت ساده و بدون بهرهگیری از CoT و استدلال مرحلهبهمرحله، بهتر از حالت با استدلال عمل کرده است.
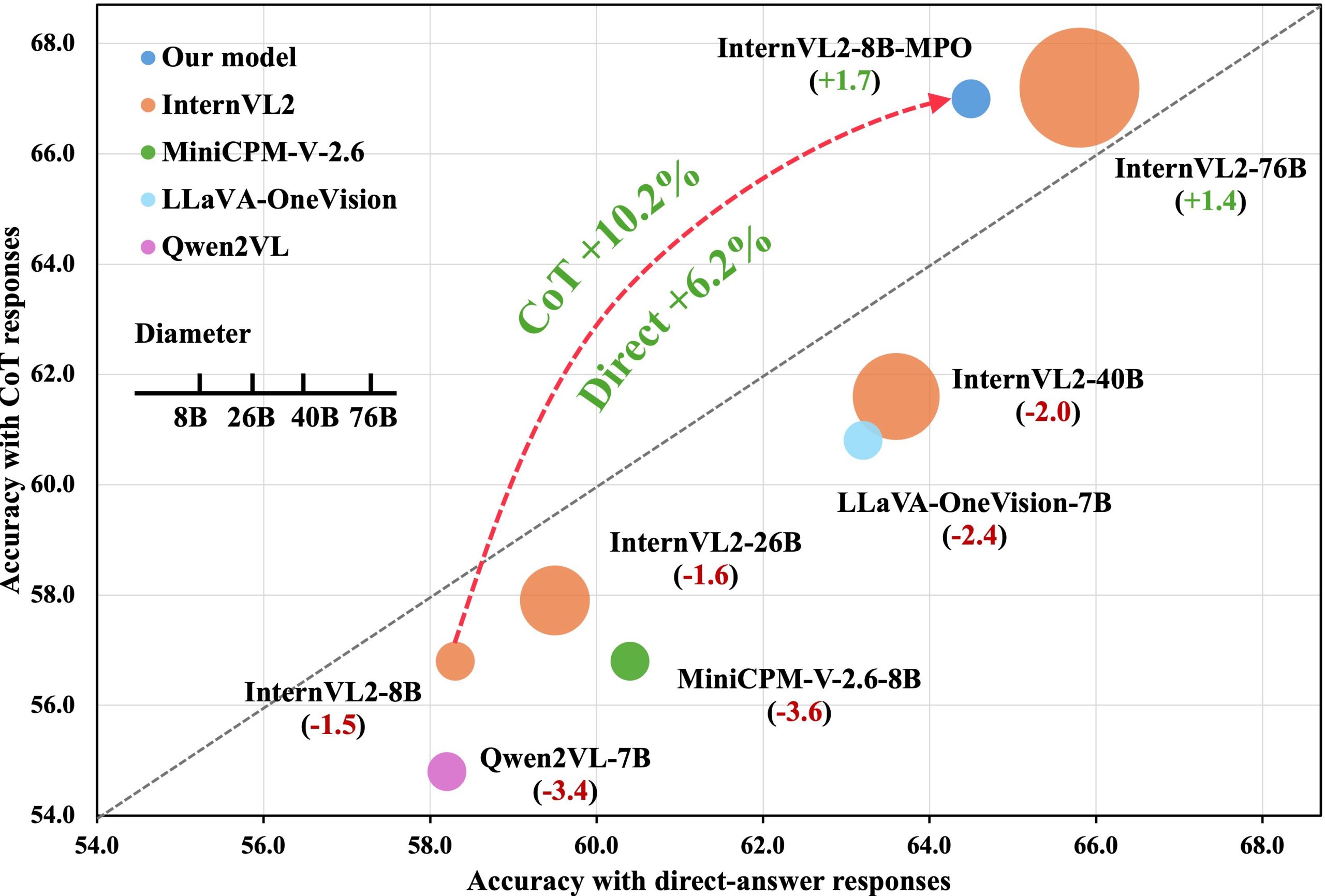
بر اساس تحقیقات، مدل قدرتمند InternVL2-8B در بنچمارک استدلال چندوجهی MathVista، هنگام استفاده از پاسخ مستقیم به امتیاز 58.3% دست مییابد. اما زمانی که از آن خواسته میشود با استدلال CoT پاسخ دهد، امتیاز آن به 56.8% کاهش مییابد. این یک مورد استثنایی نیست؛ مدلهایی مانند Qwen2VL-7B و MiniCPM-V-2.6-8B هنگام «بلند فکر کردن» حتی افت عملکرد شدیدتری را نشان میدهد. این نتیجهگیری کاملاً برخلاف شهود ما در مورد حل مسئله است و نشان میدهد که «بیشتر فکر کردن» برای هوش مصنوعی همیشه به معنای «بهتر فکر کردن» نیست.
۲. مقصر اصلی: «شکاف توزیع» بین آموزش و دنیای واقعی
چرا این اتفاق میافتد؟ مقصر اصلی مفهومی به نام «شکاف توزیع» (distribution shift) است. این پدیده را میتوان به دانشآموزی تشبیه کرد که همیشه با کلید پاسخها تمرین میکند، اما در امتحان واقعی باید به تنهایی و بدون کمک به سوالات پاسخ دهد.
- در مرحله آموزش:
مدلها با استفاده از روشی به نام «teacher forcing» (اجبار معلم) آموزش میبینند. در این روش، برای پیشبینی کلمه بعدی، همیشه کلمات صحیح قبلی به عنوان ورودی به مدل داده میشود. این کار فرآیند یادگیری را سریع و پایدار میکند. - در مرحله استنتاج (دنیای واقعی):
مدل باید کلمه بعدی را بر اساس خروجیهای خودش پیشبینی کند، نه بر اساس یک پاسخ از پیش تعیینشده.
این تفاوت بین محیط آموزشی کنترلشده و دنیای واقعی، «شکاف توزیع» را ایجاد میکند. در واقع، مدل با «چرخهای کمکی» آموزش میبیند، اما در دنیای واقعی باید به تنهایی دوچرخهسواری کند. برای یک پاسخ کوتاه و مستقیم، احتمال زمین خوردن کمتر است. اما برای یک پاسخ طولانی مبتنی بر زنجیره تفکر، یک لغزش کوچک در ابتدا میتواند تا پایان مسیر به یک سقوط کامل منجر شود. هر کلمهای که مدل تولید میکند، فرصت جدیدی برای دورتر شدن از مسیر صحیح است.
۳. راهحل: آموزش «ترجیح» پاسخهای بهتر به هوش مصنوعی
برای حل این مشکل، محققان به سراغ رویکردی متفاوت رفتند: «بهینهسازی ترجیحی» (Preference Optimization یا PO). این روش به جای اینکه فقط پاسخهای صحیح را به مدل نشان دهد (که به آن Supervised Fine-Tuning یا SFT میگویند)، به مدل میآموزد که یک پاسخ «برگزیده» (chosen) را به یک پاسخ «رد شده» (rejected) ترجیح دهد. به عبارت دیگر، هوش مصنوعی یاد میگیرد که نه تنها پاسخ صحیح چیست، بلکه چرا یک پاسخ بهتر از دیگری است.
البته این رویکرد با چالش بزرگی روبرو بود: نیاز به یک مجموعه داده عظیم از این جفتهای ترجیحی (پاسخهای خوب در مقابل بد). برای حل این مشکل، محققان یک خط لوله خودکار برای ساخت مجموعه داده MMPR ایجاد کردند که حاوی حدود ۳ میلیون نمونه برای آموزش این مدلهای هوشمند است.
۴. فرمول سری: رویکرد ترکیبی به نام MPO
صرفاً استفاده از بهینهسازی ترجیحی (مانند DPO) کافی نیست؛ همانطور که محققان دیگر نیز دریافتهاند، این روش گاهی اوقات باعث میشود مدلها متون تکراری و بیمعنی تولید کنند. برای حل این مشکل، محققان MPO یا «بهینهسازی ترجیحی ترکیبی» (Mixed Preference Optimization) را توسعه دادند؛ ترکیبی هوشمندانه از سه هدف آموزشی که در هماهنگی کامل با یکدیگر کار میکنند.
الف) یادگیری ترجیح نسبی
به مدل آموزش داده میشود که بفهمد چرا پاسخ «برگزیده» بهتر از پاسخ «رد شده» است. این کار با استفاده از تابع زیان ترجیحی (بر اساس الگوریتم DPO) انجام میشود.
![\[ L_p = - \log \sigma \left( \beta \log \frac{\pi_\theta(y_c | x)}{\pi_0(y_c | x)} - \beta \log \frac{\pi_\theta(y_r | x)}{\pi_0(y_r | x)} \right) \]](https://class.vision/wp-content/ql-cache/quicklatex.com-3b447cfb18842b7afa429fefced1eb2a_l3.png "Rendered by QuickLaTeX.com")
ب) یادگیری کیفیت مطلق
به مدل آموزش داده میشود که کیفیت یک پاسخ را به طور مستقل ارزیابی کند. این کار با استفاده از تابع زیان کیفیت (بر اساس الگوریتم BCO) انجام میشود که به طور موثر پاسخهای خوب را به ۱ و پاسخهای بد را به ۰ نگاشت میکند.
![\[ L_q = L_q^+ + L_q^- \]](https://class.vision/wp-content/ql-cache/quicklatex.com-69b00c80bdeac9b3dc9eea2fb30a1762_l3.png "Rendered by QuickLaTeX.com")
![\[ L_q^+ = - \log \sigma \left( \beta \log \frac{\pi_\theta(y_c | x)}{\pi_0(y_c | x)} - \delta \right) \]](https://class.vision/wp-content/ql-cache/quicklatex.com-fbb30523cf15c788cab39fc44d6bb033_l3.png "Rendered by QuickLaTeX.com")
![\[ L_q^- = - \log \sigma \left( - \left( \beta \log \frac{\pi_\theta(y_r | x)}{\pi_0(y_r | x)} - \delta \right) \right) \]](https://class.vision/wp-content/ql-cache/quicklatex.com-42826c7ba000ff28d0df222d4947d322_l3.png "Rendered by QuickLaTeX.com")
ج) یادگیری فرآیند تولید
به مدل کمک میشود تا فرآیند تولید پاسخهای باکیفیت را فراموش نکند و از تولید پاسخهای تکراری یا بیمعنی جلوگیری شود. این کار با استفاده از تابع زیان تولید (مشابه SFT) انجام میشود.
![\[ L_g = - \frac{\log \pi_\theta(y_c | x)}{|y_c|} \]](https://class.vision/wp-content/ql-cache/quicklatex.com-b3543796700af7a20b99a372b70abbfc_l3.png "Rendered by QuickLaTeX.com")
در نهایت، MPO این سه تابع زیان را با وزنهای مشخص با هم ترکیب میکند تا یک هدف آموزشی جامع و قدرتمند ایجاد کند:
![\[ L = w_p L_p + w_q L_q + w_g L_g \]](https://class.vision/wp-content/ql-cache/quicklatex.com-81bd31723013d3ad2cbcd18f7a305b6f_l3.png "Rendered by QuickLaTeX.com")
این استراتژی سهجانبه، کلید موفقیت MPO است. تابع زیان ترجیحی (Lp) کیفیت نسبی را آموزش میدهد، تابع زیان کیفیت (Lq) یک حس مطلق از درست و غلط را فراهم میکند، و تابع زیان تولید (Lg) به عنوان یک محافظ حیاتی عمل کرده و از فراموش کردن اصول تولید متن روان توسط مدل جلوگیری میکند — یک عارضه جانبی شناختهشده در DPO خالص. این سه با هم، یک سیگنال آموزشی متعادل و قوی ایجاد میکنند که قدرت استدلال را به طور چشمگیری بهبود میبخشد.
۵. نتیجه شگفتانگیز: وقتی یک مدل کوچک، غولها را به چالش میکشد
نتایج این روش جدید واقعاً شگفتانگیز است. مدل ۸ میلیارد پارامتری InternVL2-8B که با روش MPO آموزش دیده، در بنچمارک چالشبرانگیز MathVista به دقت 67.0% دست یافته است.
برای درک اهمیت این عدد، باید آن را در بستر مناسب قرار دهیم:
* این یک بهبود چشمگیر ۸.۷ واحدی نسبت به نسخه اصلی خود (با امتیاز ۵۸.۳٪) است.
* نکته اصلی اینجاست: این امتیاز جدید با عملکرد یک مدل ۱۰ برابر بزرگتر، یعنی InternVL2-76B (با امتیاز ۶۷.۵٪)، تقریباً برابر است.
این نتیجه نشان میدهد که MPO نه تنها بسیار مؤثر است، بلکه پتانسیل مقیاسپذیری بالایی دارد. این روش راه را برای ساخت مدلهای هوش مصنوعی کارآمدتر هموار میکند که برای رسیدن به عملکرد بالا، لزوماً نیازی به منابع محاسباتی عظیم ندارند.
نتیجهگیری: هوشمندانهتر، نه فقط بزرگتر
این تحقیق مسیری جذاب را طی کرد: از کشف یک مشکل شگفتانگیز و غیرمنتظره در استدلال هوش مصنوعی تا ارائه یک راهحل ترکیبی زیبا که نتایجی قدرتمند به همراه داشت. این پیشرفت به ما یادآوری میکند که آینده هوش مصنوعی تنها در ساخت مدلهای بزرگتر خلاصه نمیشود، بلکه در آموزش دادن به آنها برای تشخیص بهتر و درک اینکه چرا یک پاسخ بهتر از دیگری است، نهفته است.
همانطور که هوش مصنوعی به تکامل خود ادامه میدهد، این سوال مطرح میشود: آیا بزرگترین پیشرفتها نه از مقیاس بیرحمانه، بلکه از فلسفههای آموزشی ظریفی مانند MPO که حس عمیقتری از قضاوت را القا میکنند، حاصل خواهد شد؟
مطالب زیر را حتما مطالعه کنید

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 1

دیدگاهتان را بنویسید