معماری های یادگیری عمیق
ظهور هوش مصنوعی
بیش از 70 سال از عمر معماری های پیوندگرا می گذرد، اما معماری های جدید و واحدهای پردازش گرافیکی (GPU) آنها را به خط مقدم هوش مصنوعی مبدل ساخته است. یادگیری عمیق یک رویکرد واحد نیست، بلکه کلاسی از الگوریتمها و توپولوژیهاست که میتوانید از آن ها برای طیف گستردهای از مسائل استفاده کنید.
با این که یادگیری عمیق چیز جدیدی نیست ولی به دلیل وجود شبکههای عصبی لایهای عمیق و استفاده از پردازندههای گرافیکی برای تسریع در اجرا، رشد انفجاری را تجربه میکنند. کلان داده نیز در این رشد تاثیرگذار بوده است. از آنجایی که یادگیری عمیق به آموزش شبکه های عصبی با داده های نمونه و کارایی آنها بر اساس موفقیت شان متکی است، هر چه داده ها بیشتر باشد، زیربنای این ساختارهای یادگیری عمیق بهتر خواهد بود.
تعداد معماری ها و الگوریتم هایی که در یادگیری عمیق مورد استفاده قرار می گیرند، گسترده و متنوع است. این بخش به بررسی شش مورد از معماری های یادگیری عمیق در 20 سال اخیر می پردازد. قابل ذکر است که دو روش حافظه کوتاه مدت طولانی (LSTM) و شبکه های عصبی پیچشی (CNN) دو مورد از قدیمی ترین روشها و در عین حال پرکاربردترین آنها در زمینه های مختلف هستند.
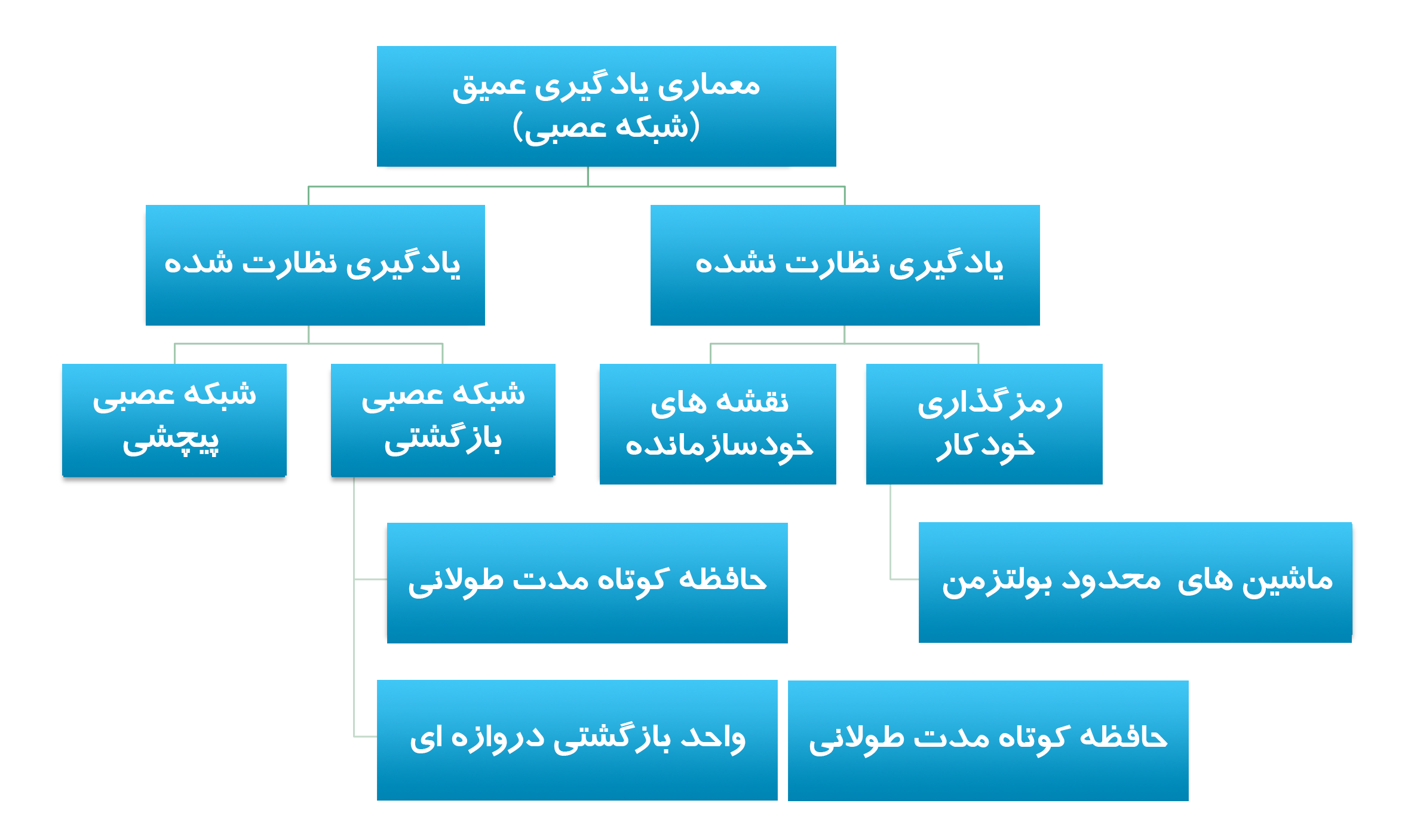
این مقاله معماریهای یادگیری عمیق را به یادگیری نظارتشده و نظارت نشده طبقهبندی کرده و چندین معماری یادگیری عمیق رایج را معرفی میکند: شبکههای عصبی پیچشی ، شبکههای عصبی بازگشتی (RNN)، واحد حافظه کوتاهمدت طولانی/ بازگشتی دروازهای (GRU)، نقشه خودسازمانده (SOM) ، رمزگذارهای خودکار (AE) و ماشین محدود Boltzman (RBM). همچنین یک نمای کلی از شبکه های باور عمیق (DBN) و شبکه های انباشته عمیق (DSN) را نیز ارائه می دهد.
شبکه عصبی مصنوعی (ANN) معماری زیربنایی یادگیری عمیق است. بر اساس ANN، چند نوع الگوریتم اختراع شده است. برای آشنایی با اصول یادگیری عمیق و شبکه های عصبی مصنوعی، مقاله مقدمه یادگیری عمیق را مطالعه کنید.
یادگیری عمیق نظارت شده
یادگیری نظارت شده به فضای مسئله ای اشاره دارد که در آن هدف مورد پیش بینی بطور واضح در داده هایی که برای آموزش استفاده می شود برچسب گذاری می شود.
در این بخش، دو مورد از محبوبترین معماریهای یادگیری عمیق تحت نظارت در سطح بالا را معرفی میکنیم. شبکههای عصبی پیچشی و شبکههای عصبی بازگشتی و برخی از انواع آنها.
شبکه های عصبی پیچشی
CNN یک شبکه عصبی چند لایه است که از نظر بیولوژیکی از قشر بینایی حیوانات الهام گرفته است. این معماری به ویژه در زمینه پردازش تصویر مفید است. اولین CNN توسط Yann LeCun ایجاد شد. در آن زمان، معماری بر روی تشخیص کاراکترهای دست نویس، مانند تفسیر کد پستی تمرکز داشت. به عنوان یک شبکه عمیق، لایههای اولیه ویژگیها (مانند لبهها) را تشخیص میدهند و لایههای بعدی دوباره این ویژگیها را در ویژگیهای سطح بالاتر ورودی ترکیب میکنند.
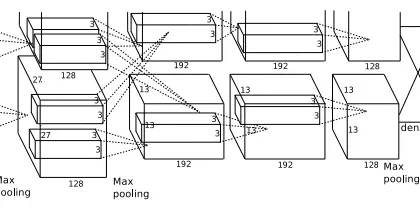
معماری LeNet CNN از چند لایه تشکیل شده است که ویژگی را استخراج و سپس طبقه بندی را انجام می دهد (تصویر زیر را ببینید). تصویر به receptive field یا میدان های تاثیر تقسیم می شود که به یک لایه پیچشی وارد می شود، و سپس ویژگی ها را از تصویر ورودی استخراج می کنند. مرحله بعدی ادغام یا pooling است که ابعاد ویژگی های استخراج شده را کاهش (از طریق نمونه برداری پایین) و در عین حال مهم ترین اطلاعات را حفظ می کند (معمولاً از طریق حداکثر pooling). سپس مرحله پیچش و pooling دیگری انجام می شود که به یک پرسپترون چند لایه کاملا متصل تفکیک شده اند. لایه خروجی نهایی این شبکه مجموعه ای از گره ها است که ویژگی های تصویر را مشخص می کند (در این مورد، یک گره به ازای هر تعداد شناسایی شده). شبکه با استفاده از back-propagation یا انتشار معکوس آموزش می بیند.
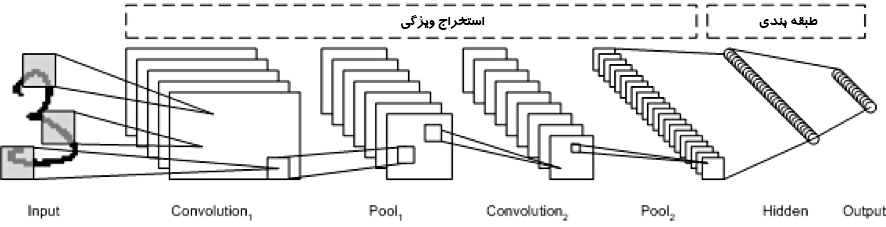
استفاده از لایههای عمیق پردازش، پیچشی، pooling ، و یک لایه طبقهبندی کاملاً متصل، دریچه نوینی را به روی کاربردهای جدید و مختلف شبکههای عصبی یادگیری عمیق گشود. علاوه بر پردازش تصویر، CNN با موفقیت در تشخیص ویدیو و پردازش زبان طبیعی استفاده شده است.
مثال از کاربردها: تشخیص تصویر، تجزیه و تحلیل ویدئو، و پردازش زبان طبیعی
شبکه های عصبی بازگشتی
RNN یکی از معماری های شبکه پایه است که سایر معماری های یادگیری عمیق از روی آن ساخته شده اند. تفاوت اصلی بین یک شبکه چندلایه معمولی و یک شبکه بازگشتی این است که به جای اتصالات کاملاً feed-forward ، یک شبکه بازگشتی می تواند دارای اتصالاتی باشد که به لایه های قبلی (یا به همان لایه) بازخورد می دهند. این بازخورد به RNN ها اجازه می دهد تا حافظه ورودی های گذشته و مشکلات مدل را به موقع حفظ و بررسی کنند.
RNN ها از مجموعه ای غنی از معماری ها تشکیل شده اند (در ادامه یک توپولوژی محبوب به نام LSTM را بررسی خواهیم کرد). وجه تمایز اصلی بازخورد درون شبکه است که می تواند خود را از یک لایه پنهان، لایه خروجی یا ترکیبی از آنها نشان دهد.
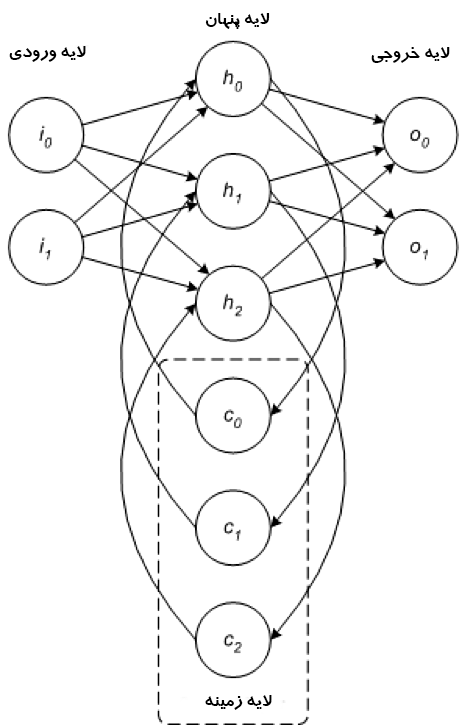
RNNها را میتوان در زمان unfold کرد و با انتشار معکوس استاندارد یا با استفاده از گونهای از انتشار معکوس که به آن انتشار معکوس در زمان (BPTT) میگویند، آموزش داد.
مثال از کاربردها: تشخیص گفتار و تشخیص دست خط
شبکه های LSTM
LSTM در سال 1997 توسط Hochreiter و Schimdhuber ایجاد شد، اما محبوبیت آن در سال های اخیر به عنوان یک معماری RNN برای کاربردهای مختلف افزایش یافته است. LSTM ها را در محصولاتی که هر روز استفاده می کنید، مانند گوشی های هوشمند، خواهید یافت. IBM از LSTMها در IBM Watson® برای تعیین نقطه عطف تشخیص گفتار مکالمه استفاده کرد.
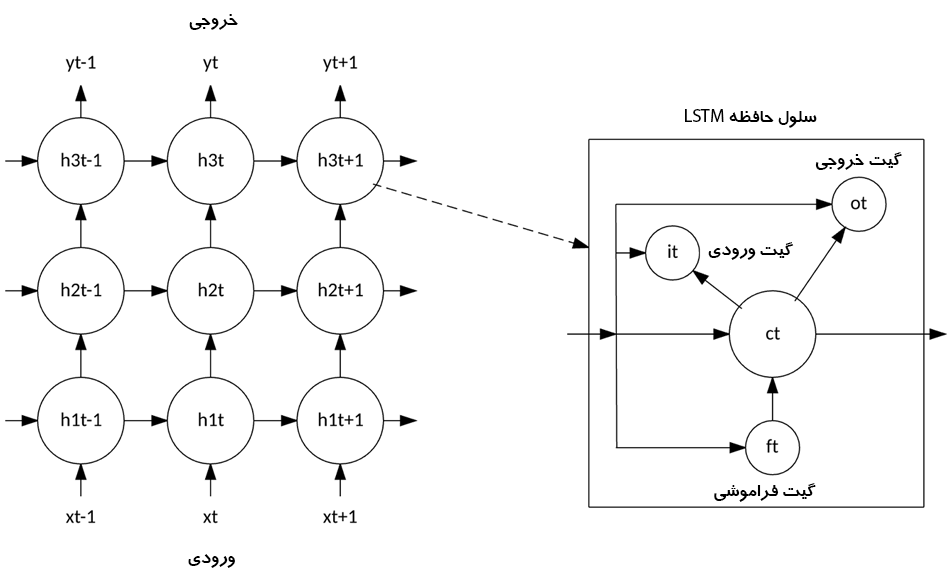
LSTM از معماری شبکه عصبی مبتنی بر نورون معمولی فاصله گرفت و در عوض مفهوم سلول حافظه را معرفی کرد. سلول حافظه می تواند مقدار خود را برای مدت کوتاه یا طولانی به عنوان تابعی از ورودی های خود حفظ کند، و به سلول اجازه می دهد آنچه را که مهم است و نه فقط آخرین مقدار محاسبه شده خود را به خاطر بسپارد.
سلول حافظه LSTM شامل سه گیت است که نحوه جریان اطلاعات به داخل یا خارج از سلول را کنترل می کند. گیت ورودی کنترل می کند که چه زمانی اطلاعات جدید می توانند به حافظه جریان یابد. گیت فراموشی زمانی را کنترل می کند که یک قطعه از اطلاعات موجود فراموش شود و به سلول اجازه می دهد تا داده های جدید را به خاطر بسپارد. در نهایت، گیت خروجی زمانی را کنترل می کند که اطلاعات موجود در سلول در خروجی سلول استفاده شود. همچنین سلول دارای وزن هایی است که هر گیت را کنترل می کند. الگوریتم آموزشی، معمولاً BPTT، این وزنها را بر اساس خطای خروجی شبکه دقیقا تنظیم میکند.
اپلیکیشن های اخیر CNN ها و LSTM ها سیستم های زیرنویس تصویر و ویدیو را تولید کردند که در آن یک تصویر یا ویدیو به زبان طبیعی شرح داده می شود. CNN پردازش تصویر یا ویدئو را پیاده سازی می کند و LSTM برای تبدیل خروجی CNN به زبان طبیعی آموزش دیده است.
مثال از کاربردها: سیستم های زیرنویس تصویر و ویدئو
شبکه های GRU
در سال 2014، ساده سازی LSTM به نام واحد بازگشتی دروازه ای معرفی شد. این مدل دارای دو گیت است که در آن از گیت خروجی موجود در مدل LSTM خبری نیست. این گیت ها یک گیت update و یک گیت reset هستند. گیت update نشان می دهد که چه مقدار از محتویات سلول قبلی باید حفظ شود. گیت reset نحوه ترکیب ورودی جدید را با محتویات سلول قبلی تعریف می کند. یک GRU می تواند یک RNN استاندارد را به سادگی با تنظیم گیت reset روی 1 و گیت update روی 0 مدل کند.
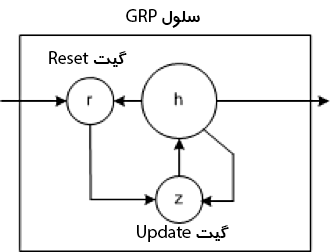
GRU ساده تر از LSTM است، می تواند سریع تر آموزش داده شود و در اجرا کارآمدتر باشد. با این حال، LSTM می تواند واضح تر باشد و با داده های بیشتر می تواند به نتایج بهتری دست یابد.
مثال از کاربردها: فشرده سازی متن زبان طبیعی، تشخیص دست خط، تشخیص گفتار، تشخیص ژست، نوشتن شرح تصویر
یادگیری عمیق نظارت نشده
یادگیری بدون نظارت به فضای مساله ای اشاره دارد که در داده هایی که برای آموزش استفاده می شوند هیچ برچسب هدفی وجود ندارد.
این بخش سه معماری یادگیری عمیق بدون نظارت را مورد بحث قرار می دهد: نقشه های خودسازمانده، رمزگذارهای خودکار و ماشین های محدود بولتزمن. همچنین در خواهیم یافت که چگونه شبکه های باور عمیق و شبکه های انباشته عمیق بر اساس معماری بدون نظارت زیربنایی ساخته می شوند.
نقشه های خود سازمانده
نقشه خود سازمانده (SOM) توسط دکتر Teuvo Kohonen در سال 1982 اختراع شد و معمولا به عنوان نقشه Kohonen شناخته می شد. SOM یک شبکه عصبی بدون نظارت است که با کاهش ابعاد ورودی، خوشه هایی از مجموعه داده های ورودی را ایجاد می کند. SOM ها از چند جهت با شبکه عصبی مصنوعی معمول متفاوت هستند.
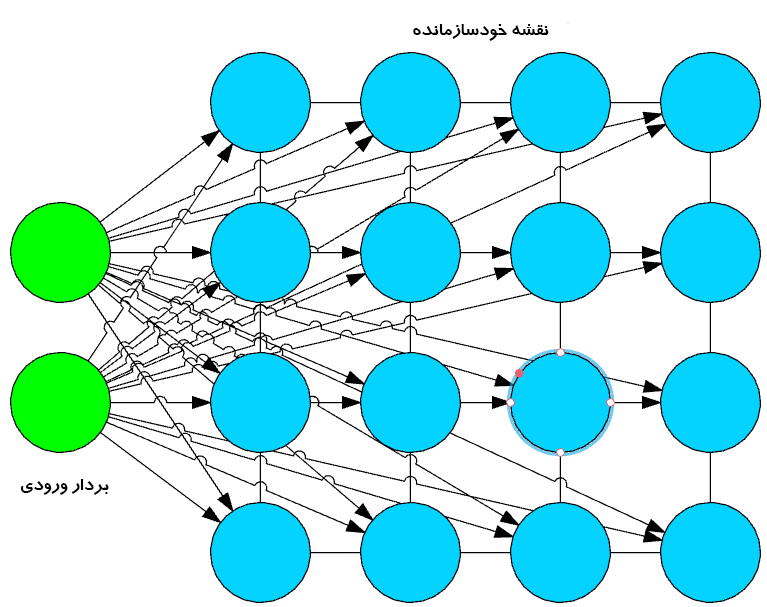
اولین تغییر مهم این است که وزن ها به عنوان مشخصه گره عمل می کنند. پس از نرمال شدن ورودی ها، ابتدا یک ورودی تصادفی انتخاب می شود. وزنهای تصادفی نزدیک به صفر برای هر ویژگی رکورد ورودی مقداردهی اولیه میشوند. حال این وزن ها گره ورودی را نشان می دهند. چند ترکیب از این وزنهای تصادفی، تغییرات گره ورودی را نشان میدهند. فاصله اقلیدسی بین هر یک از این گره های خروجی با گره ورودی محاسبه می شود. گرهی با کمترین فاصله به عنوان دقیق ترین نمایش ورودی اعلام و به عنوان بهترین واحد تطبیق یا BMU مشخص می شود. با این BMUها به عنوان نقاط مرکزی، واحدهای دیگر به طور مشابه محاسبه شده و به خوشه ای که از آن فاصله دارد اختصاص داده می شود. شعاع نقاط اطراف وزن BMU بر اساس مجاورت به روز می شود. شعاع کوچک شده است.
در مرحله بعد یک SOM، هیچ تابع فعال سازی اعمال نمی شود، و از آنجا که هیچ برچسب هدفی برای مقایسه با آن وجود ندارد، مفهومی برای محاسبه خطا و انتشار معکوس وجود ندارد.
مثال از کاربردها: کاهش ابعاد، خوشهبندی ورودیهای با ابعاد بالا به خروجی دو بعدی، نتیجه درجه تابشی، و تجسم خوشهای
رمزگذارهای خودکار
اگرچه تاریخچه زمانی که رمزگذارهای خودکار اختراع شدند مبهم است، اما اولین استفاده ثبت شده از رمزگذارهای خودکار توسط LeCun در سال 1987 انجام شد. این نوع از ANN از 3 لایه تشکیل شده است: لایه های ورودی، پنهان و خروجی.
ابتدا لایه ورودی با استفاده از یک تابع کدگذاری مناسب در لایه پنهان کدگذاری می شود. تعداد گره ها در لایه پنهان بسیار کمتر از تعداد گره های لایه ورودی است. لایه پنهان حاوی نمایش فشرده ورودی اصلی است. هدف لایه خروجی بازسازی لایه ورودی با استفاده از یک تابع رمزگشا است.
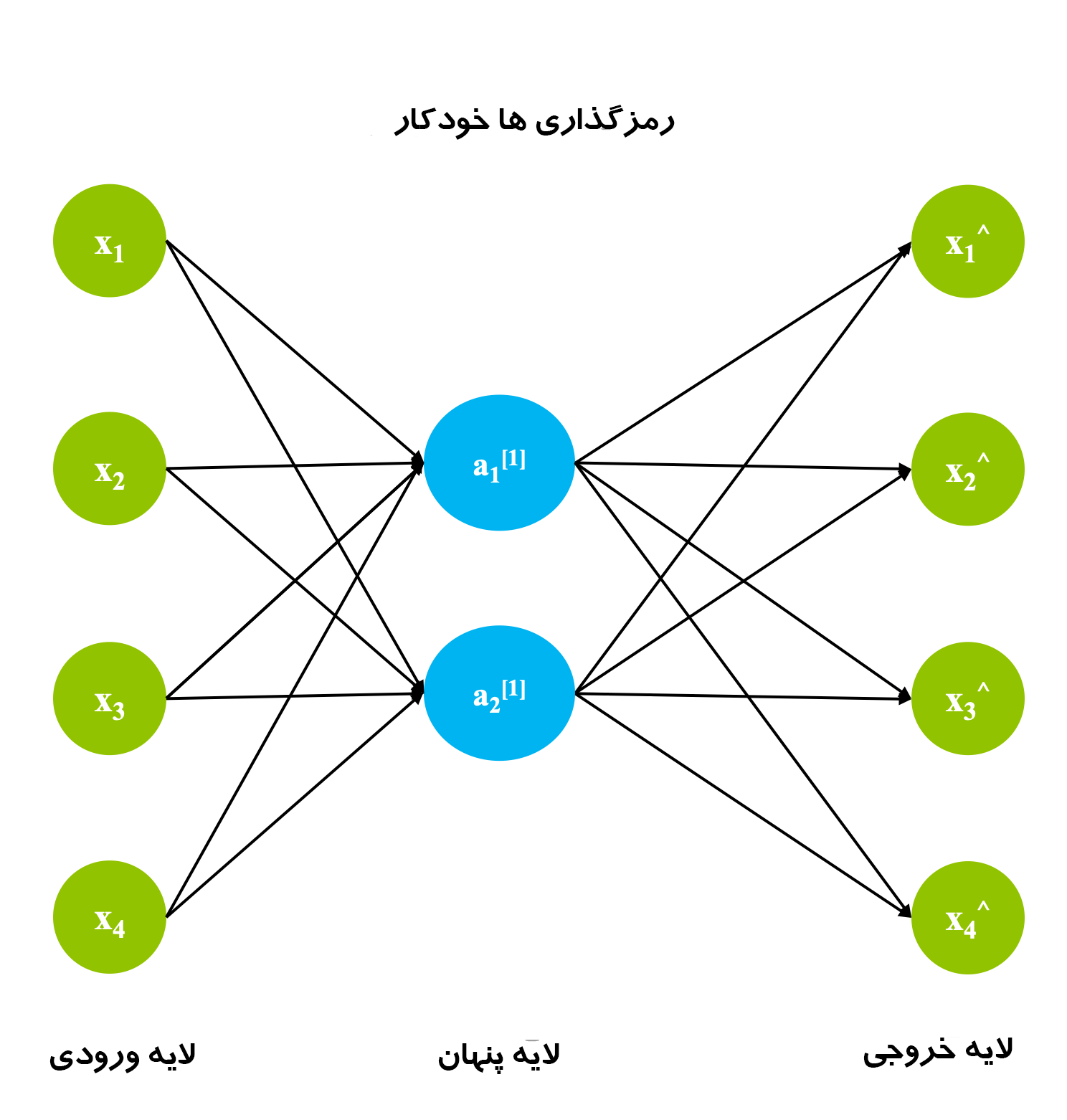
در مرحله آموزش، تفاوت بین لایه ورودی و خروجی با استفاده از تابع خطا محاسبه و وزنها برای به حداقل رساندن خطا تنظیم میشوند. برخلاف تکنیکهای مرسوم یادگیری بدون نظارت، که در آن هیچ دادهای برای مقایسه خروجیها وجود ندارد، رمزگذارهای خودکار به طور مداوم با استفاده از پس انتشار یا backward propagation یاد میگیرند. به همین دلیل، رمزگذارهای خودکار به عنوان الگوریتم های خود نظارت طبقه بندی می شوند.
مثال از کاربردها: کاهش ابعاد، درون یابی داده ها، و فشرده سازی/فشرده سازی داده ها
ماشین های محدود بولتزمن
اگرچه RBM ها خیلی دیرتر محبوب شدند، اما در ابتدا توسط Paul Smolensky در سال 1986 اختراع شدند و به عنوان هارمونیوم شناخته شدند.
RBM یک شبکه عصبی دو لایه است. لایه ها لایه های ورودی و پنهان هستند. همانطور که در شکل زیر نشان داده شده است، در RBM ها هر گره در یک لایه پنهان به هر گره در یک لایه قابل مشاهده متصل است. در ماشین سنتی بولتزمن، گرههای درون لایه ورودی و پنهان نیز به هم متصل میشوند. به دلیل پیچیدگی محاسباتی، گره های درون یک لایه در ماشین بولتزمن محدود به هم متصل نیستند.
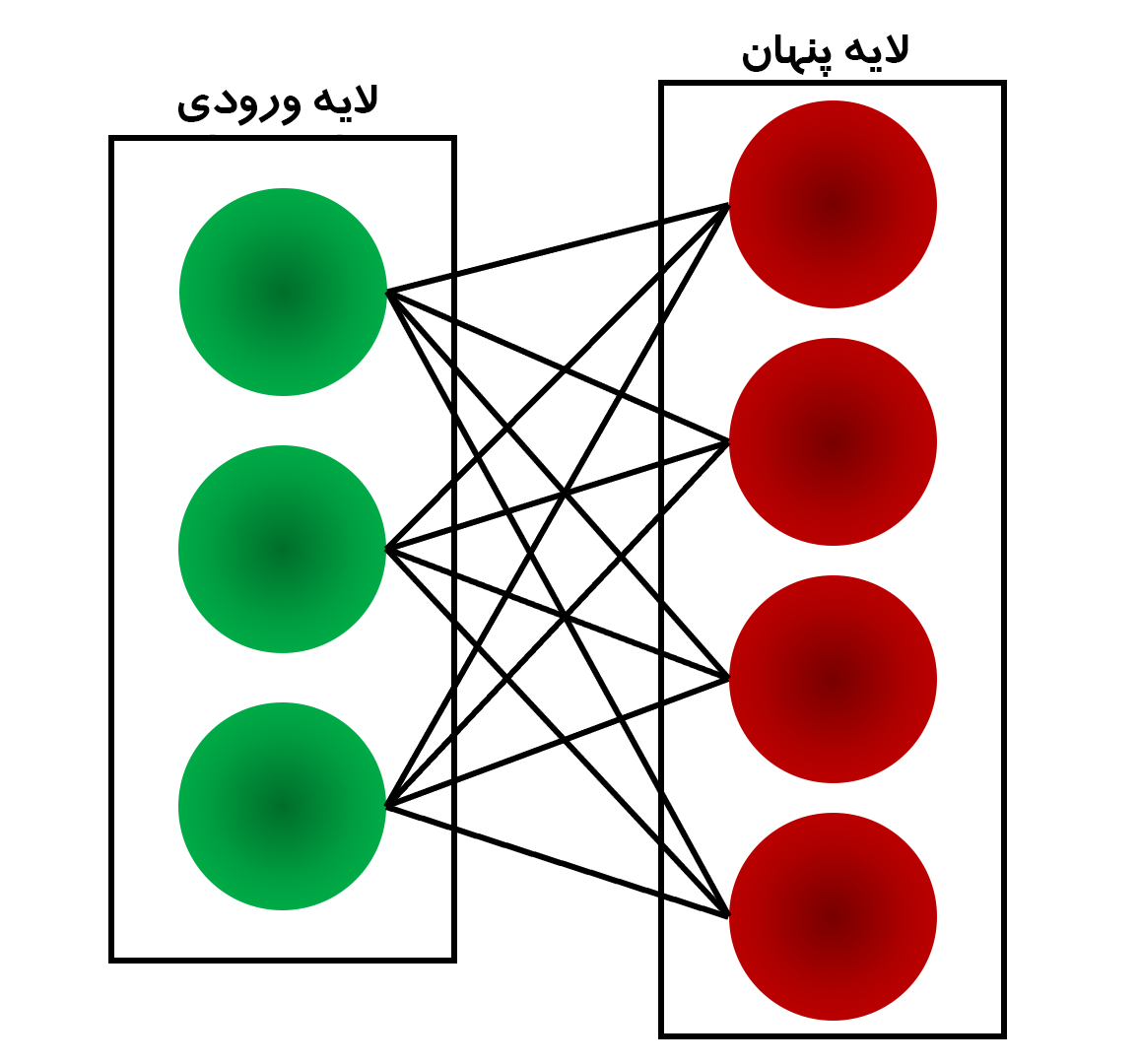
در طول مرحله آموزش، RBM ها توزیع احتمال مجموعه آموزشی را با استفاده از یک رویکرد تصادفی محاسبه می کنند. هنگامی که آموزش شروع می شود، هر نورون به طور تصادفی فعال می شود. مدل دارای جهت گیری پنهان و آشکار مربوطه نیز است. با وجودی که جهت گیری پنهان در فاز رو به جلو برای ایجاد فعال سازی استفاده می شود، جهت گیری قابل مشاهده به بازسازی ورودی کمک می کند.
از آنجا که در یک RBM ورودی بازسازی شده همیشه با ورودی اصلی متفاوت است، آنها را به عنوان مدل های مولد نیز می شناسند.
به دلیل تصادفی بودن ذاتی، پیشبینیهای یکسان خروجیهای متفاوتی را به همراه دارد. در واقع، این مهم ترین تفاوت با رمزگذار خودکار است که یک مدل قطعیست.
مثال از کاربردها: کاهش ابعاد و فیلترینگ مشارکتی
شبکه های باور عمیق
DBN یک معماری شبکه معمولی، اما شامل یک الگوریتم آموزشی جدید است. DBN یک شبکه چند لایه است (معمولاً عمیق و چندین لایه پنهان) که در آن هر جفت لایه متصل یک RBM است. به این ترتیب، DBN به عنوان پشته ای از RBM ها نشان داده می شود.
در DBN، لایه ورودی ورودیهای سنسوری خام را نشان میدهد و هر لایه پنهان، نمایشهای انتزاعی این ورودی را میآموزد. لایه خروجی که تا حدودی متفاوت از لایه های دیگر رفتار می کند، طبقه بندی شبکه را پیاده سازی می کند. آموزش در دو مرحله انجام می شود: پیش تمرین نظارت نشده و بهینه سازی و تنظیم دقیق نظارت شده.
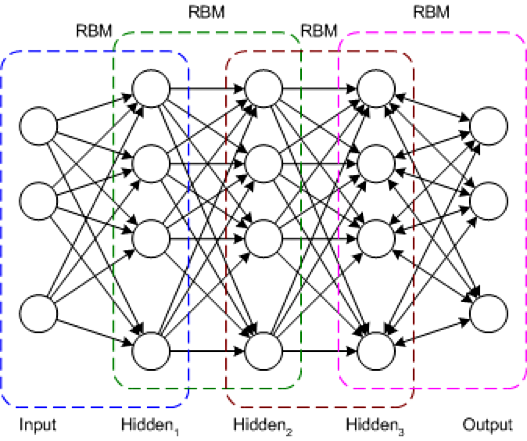
در پیشآموزش بدون نظارت، هر RBM برای بازسازی ورودی خود آموزش داده میشود (به عنوان مثال، اولین RBM لایه ورودی را به اولین لایه پنهان بازسازی میکند). RBM بعدی به طور مشابه آموزش داده می شود، اما اولین لایه پنهان به عنوان لایه ورودی (یا قابل مشاهده) در نظر گرفته شده و RBM با استفاده از خروجی های اولین لایه پنهان به عنوان ورودی آموزش داده می شود. این روند تا زمانی ادامه می یابد که هر لایه آموزش داده شود. زمانی که پیشآموزش کامل شد، تنظیم دقیق آغاز میشود. در این مرحله، گرههای خروجی برچسبهایی هستند که به آنها معنا می دهند (آنچه در بافت شبکه نشان میدهند). سپس آموزش شبکه کامل با استفاده از یادگیری گرادیان کاهشی یا پس انتشار برای تکمیل فرآیند آموزش اعمال می شود.
مثال از کاربردها: تشخیص تصویر، بازیابی اطلاعات، درک زبان طبیعی و پیشبینی شکست
شبکه های انباشته عمیق
معماری نهایی DSN است که شبکه convex عمیق نیز نامیده می شود. یک DSN با چارچوبهای یادگیری عمیق معمول متفاوت است زیرا اگرچه از یک شبکه عمیق تشکیل شده است، اما در واقع مجموعهای عمیق از شبکههای جداگانه است که هر یک دارای لایههای پنهان خاص خود است. این معماری پاسخی به یکی از مشکلات یادگیری عمیق، یعنی پیچیدگی آموزش است. هر لایه در معماری یادگیری عمیق به طور تصاعدی پیچیدگی آموزش را افزایش می دهد، بنابراین DSN آموزش را نه به عنوان یک مساله تکی بلکه به عنوان مجموعه ای از مسائل آموزشی مجزا می بیند.
DSN از مجموعه ای از ماژول ها تشکیل شده است که هر کدام یک زیرشبکه در سلسله مراتب کلی DSN هستند. در یک نمونه از این معماری، سه ماژول برای DSN ایجاد شده است. هر ماژول از یک لایه ورودی، یک لایه پنهان و یک لایه خروجی تشکیل شده است. ماژول ها یکی روی دیگری چیده می شوند، بطوری که ورودی های یک ماژول از خروجی های لایه قبلی و بردار ورودی اصلی تشکیل شده است. این لایه بندی به شبکه کلی اجازه می دهد تا طبقه بندی پیچیده تری را نسبت به یک ماژول واحد یاد بگیرد.
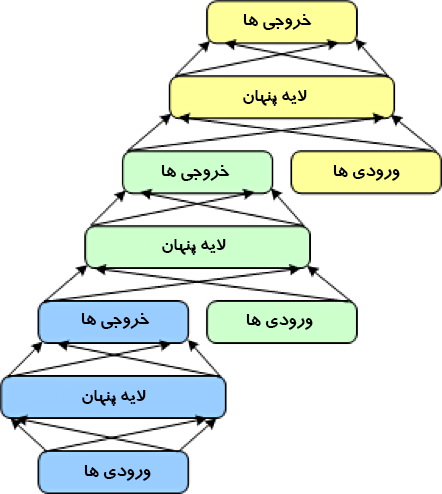
DSN اجازه آموزش ماژول های جداگانه را می دهد و با توجه به توانایی آموزش موازی آن را کارآمد می کند. بهجای پس انتشار در کل شبکه، آموزش نظارت شده بصورت پسانتشار برای هر ماژول اجرا میشود. برای بسیاری از مسائل، DSN ها می توانند عملکرد بهتری نسبت به DBN های معمولی داشته باشند، و آنها را به یک معماری شبکه محبوب و کارآمد تبدیل می کند.
مثال از کاربردها: بازیابی اطلاعات و تشخیص گفتار مداوم
پیشرفت
یادگیری عمیق توسط طیفی از معماری ها نشان داده می شود که می توانند راه حل هایی را برای مجموعه گسترده ای از مسائل ایجاد کنند. این راهحلها میتوانند شبکههای متمرکز بر feed-forward یا شبکههای بازگشتی باشند که امکان بررسی ورودیهای قبلی را فراهم میکنند. اگرچه ساختن این نوع معماریهای عمیق میتواند پیچیده باشد، اما راهحلهای منبع باز مختلفی مانند Caffe، Deeplearning4j، TensorFlow و DDL برای استفاده سریع در دسترس قرار دارند.
مطالب زیر را حتما مطالعه کنید
مجموعه داده شناسایی حرکات دست
آموزش کامل پیرامون تحلیل مولفههای متصل و تابع Connected Components در OpenCV

بزرگنمایی ویدیویی اویلری

چالش ایمیجنت (ImageNet) چیست؟ (+ویدیو)
لیبل زنی خودکار داده ها SegGPT
دیدگاهتان را بنویسید