سوالات رایج یادگیری عمیق و بینایی کامپیوتر

- دیپ لرنینگ(یادگیری عمیق) چیست و چه تفاوتی با ماشین لرنینگ (یادگیری ماشین) دارد؟
یادگیری عمیق زیرمجموعه ای از یادگیری ماشینی است. در یادگیری ماشین ما میتوانیم از انواع روش ها نظیر آماری، همسایه ها و … استفاده کنیم. یکی از زیر مجموعه های یادگیری ماشین شبکه های عصبی مصنوعی است که در طراحی آن از ساختار و عملکرد مغز الهام گرفته شده است. به دلایلی نظیر محدودیت داده و حجم محاسبات قبلا در شبکه های عصبی نیز از نهایت 1 یا 2 لایه (که نشان دهنده حجم محاسبات است) استفاده میشد. امروزه با پیشرفت ها ما شبکه عصبی هایی با لایه های بیشتر داریم. شبکه عصبی ای که بیش از 2 لایه پنهان داشته باشد رایادگیری عمیق یا دیپ لرنینگ مینامیم. پس به عبارتی دیپ لرنینگ یک شاخه از ماشین لرنینگ است. - بهترین فریمورکهای (چارچوب های) یادگیری عمیق چیست؟
چارچوب های یادگیری عمیق یا دیپ لرنینگ بسیاری موجود است.
برخی از محبوب ترین آنها عبارتند از TensorFlow، PyTorch، Caffe،Keras، Mxnet و CNTK.
تقریبا از تمام این فریم ورک ها برای بینایی کامپیوتر نیز استفاده میشود.
اما امروزه Tensorflow 2 (که ترکیب تنسرفلو و keras است) و PyTorch محبوبتر از بقیه هستند. - چگونه می توان یادگیری عمیق را برای مسائل طبقه بندی تصاویر استفاده کرد؟
مسائل طبقه بندی تصویر یا Image Classification را می توان با استفاده از یادگیری عمیق و با آموزش یک شبکه عصبی کانولوشنالی (CNN) بر روی مجموعه داده بزرگی از تصاویر برچسب دار حل کرد. CNN ویژگی ها و الگوهای موجود در تصاویر را می آموزد و سپس از این دانش برای پیش بینی تصاویر جدید و دیده نشده استفاده می کند. - شبکه عصبی کانولوشنالی (CNN) چیست و چگونه کار می کند؟
شبکه عصبی کانولوشنالی (CNN) نوعی شبکه عصبی است که به طور خاص برای تشخیص و پردازش تصویر طراحی شده است. از چندین لایه، از جمله لایههای کانولوشن، واحدهای فعالسازی و واحدهای ادغام(pooling) تشکیل شده است که ویژگیهایی را از تصویر استخراج کرده و با ترکیب این ویژگی ها و ساخت ویژگی های پیچیده تر در نهایت از آنها برای پیشبینی استفاده میکند. - چگونه می توانم یک مدل یادگیری عمیق برای تشخیص اشیا (Object detection) در تصاویر یا فیلم ها آموزش دهم؟
برای آموزش یک مدل یادگیری عمیق برای تشخیص اشیا، می توانید از چارچوبی مانند API تشخیص اشیاء TensorFlow به نام “TensorFlow’s Object Detection API”استفاده کنید. این ابزار از یک CNN برای شناسایی و یافتن موقعیت اشیاء در تصاویر یا ویدیوها استفاده می کند. مدلهای موجود در این فریم ورک بر روی مجموعه داده بزرگی از تصاویر حاشیهنویسی یا لیبل زده شده آموزش داده شده و شما میتوانید آن را روی مجموعه دادههای کوچکتر خودتان fine-tune کنید.
البته ابزارهای دیگری نظیر darknet و … نیز وجود دارد. - یادگیری انتقالی (transfer learning) چیست و چگونه می توان از آن در بینایی کامپیوتری استفاده کرد؟
در یادگیری انتقالی یا Transfer learning به جای آموزش یک مدل از ابتدا، از یک مدل یادگیری عمیق از پیش آموزش دیده به عنوان نقطه شروع برای یک کار جدید استفاده میکنیم. این کار اغلب در بینایی کامپیوتر انجام می شود، اما در تشخیص متن و … هم میتوان از این روش استفاده کرد. در تسکهای مرتبط با بینایی کامپیوتر مدل های از پیش آموزش داده شده روی مجموعه داده های تصویری بزرگ مانند ImageNet را می توان برای کارهای خاص مانند تشخیص اشیا یا تقسیم بندی معنایی یا حتی طبقه بندی اما روی داده ی جدید استفاده کرد. - سوالات شما
شما نیز اگر سوالی دارید در کامنت این پست بپرسید!
مطالب زیر را حتما مطالعه کنید

مدل هوش مصنوعی چیست؟
مدل هوش مصنوعی (AI model) برنامهای است که روی مجموعهای...
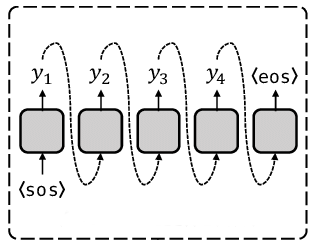
مدلهای خودهمبسته یا Autoregressive
در دنیای پرشتاب هوش مصنوعی، مدلهای خودهمبسته (Autoregressive) به عنوان...
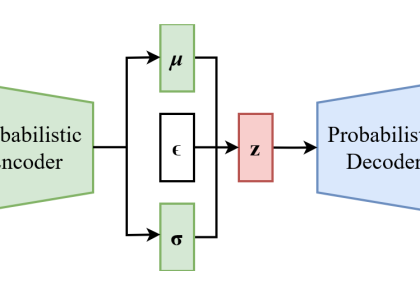
خودرمزگذار متغیر یا VAE چیست و چگونه کار میکند؟
چگونگی عملکرد خودرمزگذار متغیر (Variational Autoencoder یا VAE): قبلا پیرامون...
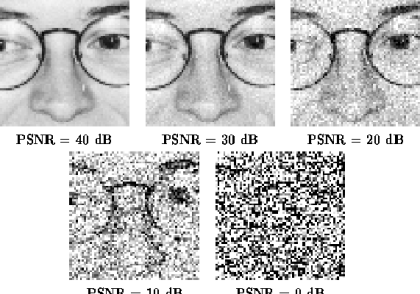
PSNR چیست؟
اصطلاح نسبت اوج سیگنال به نویز (Peak Signal-to-Noise Ratio یا...
دیدگاهتان را بنویسید