-
×
 مبانی هوش مصنوعی و یادگیری ماشین 1 × 600.000 تومان
مبانی هوش مصنوعی و یادگیری ماشین 1 × 600.000 تومان -
×
 دورهی آموزشی ویدیویی Graph Neural Network 1 × 1.300.000 تومان
دورهی آموزشی ویدیویی Graph Neural Network 1 × 1.300.000 تومان -
×
 دوره جامع یادگیری عمیق: تسلط بر هوش مصنوعی با 40 ساعت آموزش (Tensorflow/keras) 1 × 2.599.000 تومان
دوره جامع یادگیری عمیق: تسلط بر هوش مصنوعی با 40 ساعت آموزش (Tensorflow/keras) 1 × 2.599.000 تومان -
×
 دوره آموزشی مقدماتی شبکه های عصبی عمیق در Tensorflow/Keras 1 × 900.000 تومان
دوره آموزشی مقدماتی شبکه های عصبی عمیق در Tensorflow/Keras 1 × 900.000 تومان -
×
 آموزش Python(پایتون) برای هوش مصنوعی 1 × 0 تومان
آموزش Python(پایتون) برای هوش مصنوعی 1 × 0 تومان





جمع : 5.399.000 تومان
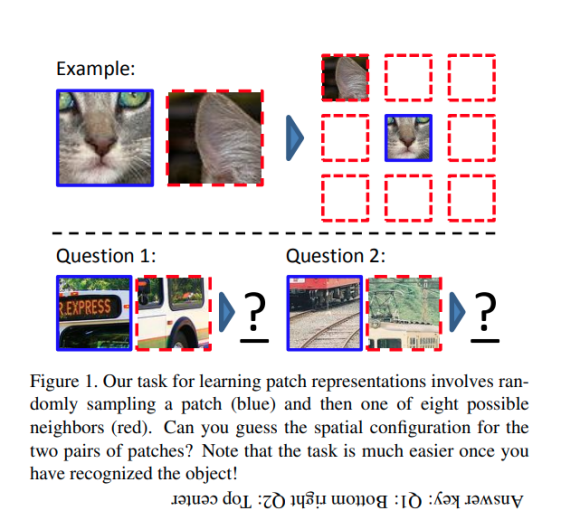
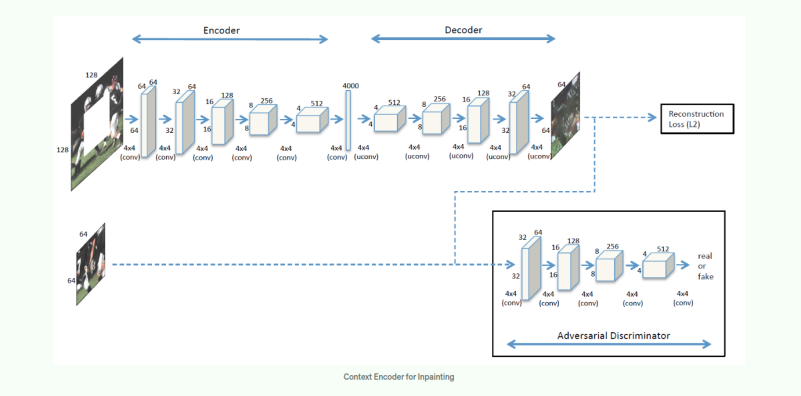
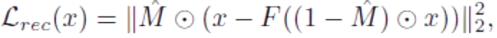
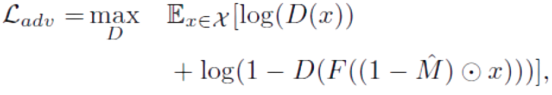
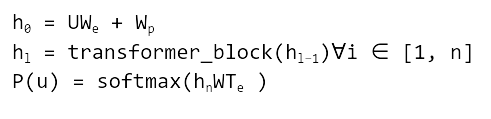
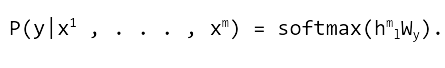
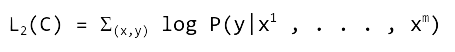
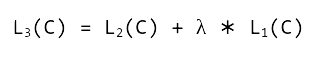






دیدگاهتان را بنویسید