ترنسفورمر – بخش اول
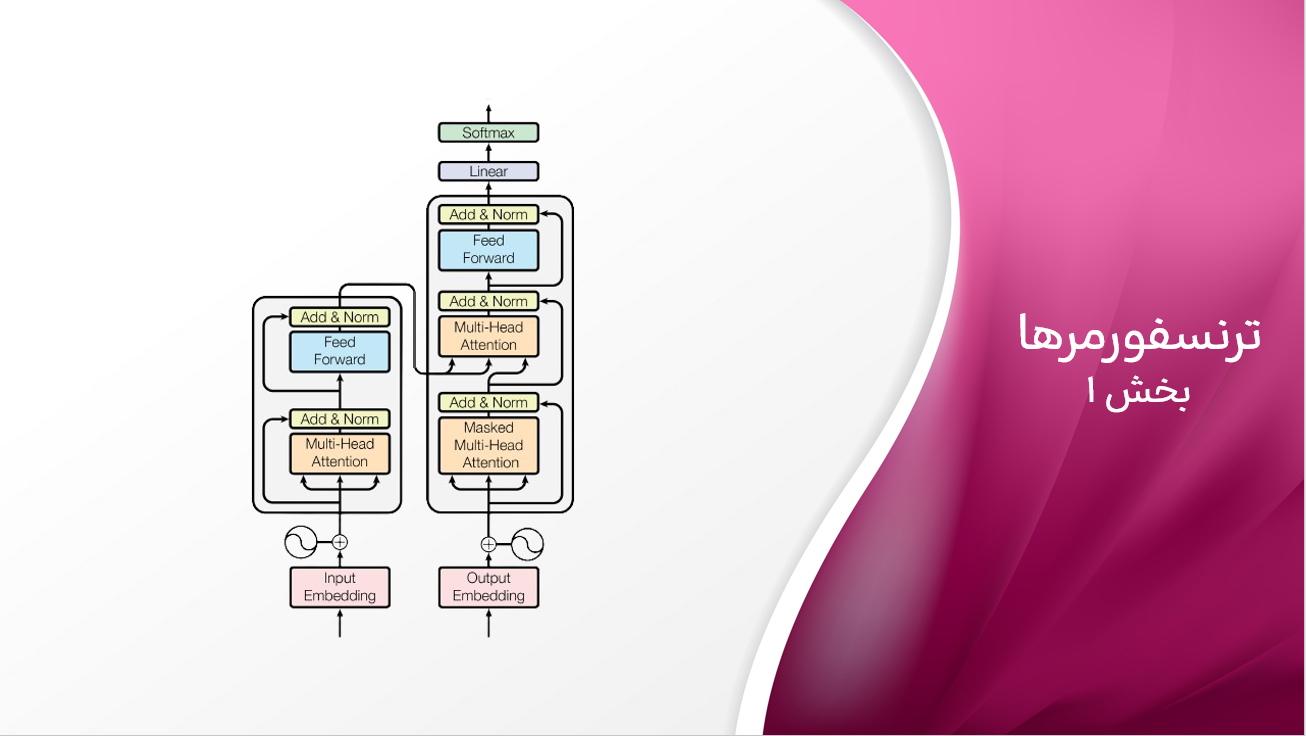
بسیاری از افراد موج اخیر پیشرفتهای هوش مصنوعی مولد را به معرفی یک کلاس از مدلها به نام “ترنسفورمرها” در سال ۲۰۱۷ نسبت میدهند. شناختهشدهترین کاربرد این مدلها مدلهای زبانی بزرگ (LLMs) قدرتمند مانند لاما و GPT-4 است که روزانه توسط صدها میلیون نفر استفاده میشوند. ترانسفورمرها به ستون فقرات برنامههای هوش مصنوعی مدرن تبدیل شدهاند و از چتباتها و سیستمهای جستجو گرفته تا ترجمه ماشینی و خلاصهسازی محتوا را قدرت میدهند. آنها حتی فراتر از متن هم رفتهاند و در زمینههایی مانند بینایی کامپیوتر، تولید موسیقی و تا کردن پروتئینها نیز انقلابی ایجاد کردهاند. در این سلسله پست، ایدههای اصلی پشت ترنسفورمرها و نحوه کار آنها را بررسی خواهیم کرد و تمرکز ما بر یکی از رایجترین کاربردها: مدل زبانی خواهد بود.
پیش از اینکه به جزئیات ترنسفورمرها بپردازیم، بیایید یک قدم به عقب برداریم و بفهمیم مدل زبانی چیست. مدل زبانی (LM) در واقع یک مدل احتمالاتی است که یاد میگیرد کلمه بعدی (یا نشانه بعدی) را در یک دنباله بر اساس کلمات پیشین یا اطراف پیشبینی کند. این کار ساختار و الگوهای زیربنایی زبان را میگیرد و به آن اجازه میدهد متن واقعی و منسجم تولید کند. یک مثال از مدل زبانی، گوشی های هوشمند شما است که وقتی پیامک یا متنی مینوسید به صورت خودکار کلماتی را به شما پیشنهاد میدهد!
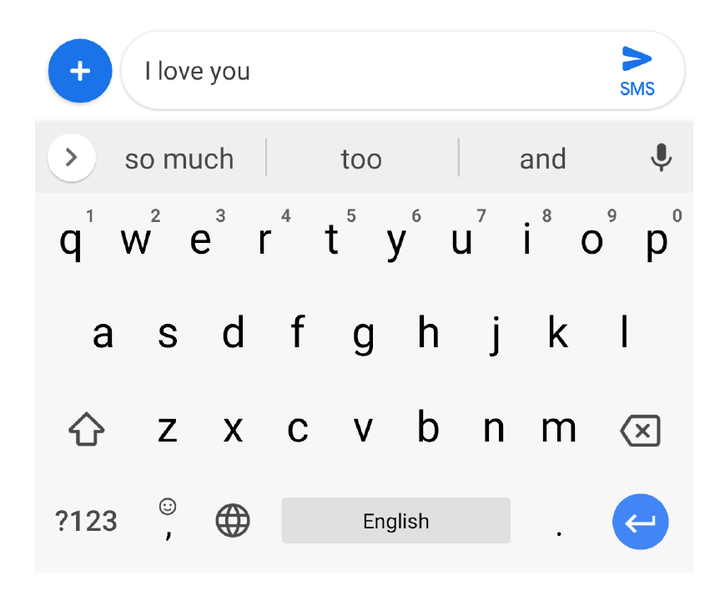
مثلا در تصویر بالا وقتی نوشته اید I Love you خود گوشی همراه شما واژه هایی مثل so much و too و and را پیشنهاد داده است. این در واقع یک مدل زبانی است که بر مبنای احتمالات وقوع یک کلمه بعد از تعدای کلمه پیشنهاد میدهد.
حال سوال پیش میاید که کاربرد ترنسفورمرها در اینجا چیست؟ برخلاف مدلهای زبانی سنتی که از پنجرههای ثابت اندازه یا شبکههای عصبی بازگشتی (RNNs) استفاده میکنند، ترنسفورمرها برای پردازش وابستگیهای طولانیمدت و روابط پیچیده بین کلمات به طور کارآمدتر و بیانگرانهتر طراحی شدهاند. برای مثال، تصور کنید که میخواهید از یک مدل زبانی برای خلاصه کردن یک مقاله خبری استفاده کنید که ممکن است شامل صدها یا حتی هزاران کلمه باشد. مدلهای زبانی سنتی با متون طولانی مشکل دارند، بنابراین خلاصه ممکن است جزئیات مهم ابتدای مقاله را از دست بدهد. اما مدلهای زبانی مبتنی بر ترنسفورمرها نتایج قوی در این کار نشان میدهند. علاوه بر ایجاد متون با کیفیت، ترنسفورمرها دارای ویژگیهای دیگر مانند موازیسازی کارآمد آموزش، مقیاسپذیری و انتقال دانش، که آنها را محبوب و مناسب برای وظایف متعدد میسازد نیز هستند. در قلب این نوآوری مکانیزم توجه-به-خود قرار دارد که به مدل اجازه میدهد اهمیت هر کلمه را در کل متن وزندهی کند.
برای کمک به درک بهتر نحوهی کار مدلهای زبانی، در ادامه این آموزش از نمونه کدهایی استفاده شده است.
مدل زبانی در عمل
در این بخش، یک مدل ترنسفورمر موجود از پیشآموزشدادهشده را بارگیری کرده و با آن تعامل خواهیم کرد تا در ابتدا درک سطح بالایی از نحوه کار آنها به دست آوریم. ما از مدل GPT-2 استفاده خواهیم کرد که در سال ۲۰۱۹ به دلیل قابلیتهای چشمگیر تولید متن خود در آن زمان خبرساز شد. اگرچه این مدل بر اساس استانداردهای امروزی مدلی کوچک و تقریباً قدیمی است، اما GPT-2 همچنان نمونه خوبی از نحوه کار مدلهای زبانی را میتواند به ما نشان دهد و همان اصول در مورد مدلهای بزرگتر (بیش از ۱۰۰ برابر بزرگتر!) و قدرتمندتری که از آن زمان تا کنون منتشر شدهاست، اعمال میشود.
توکنسازی متن (Tokenization):
بیایید با یک مثال شروع کنیم!
برای مثال، با توجه به عبارت “شب تاریک و طوفانی بود“، ما میخواهیم مدل چند کلمه دیگر برای ادامه آن تولید کند. مدلها نمیتوانند متن را مستقیماً به عنوان ورودی دریافت کنند؛ ورودی آنها باید دادهای باشد که به صورت اعداد نمایش داده شود. برای وارد کردن متن به یک مدل، ابتدا باید روشی برای تبدیل دنبالهها به اعداد پیدا کنیم. این فرآیند را Tokenization مینامند که یک گام حیاتی در مراحل پردازش زبان طبیعی (NLP) است. (لازم به ذکر است در این متن به هر دو فاز توکنسازی و وکتورسازی که در برخی از متون با مفاهیم متفاوت بیان میگردد را باهم توکنسازی نامیده که برای توصیف فرآیند تبدیل یک جمله به دنبالهای از اعداد استفاده شده است.)
یک گزینه آسان این است که متن را به کاراکترهای جداگانه تقسیم کرده و به هر کاراکتر یک شناسه عددی منحصر به فرد اختصاص دهیم. این روش برای زبانهایی مانند چینی که هر کاراکتر اطلاعات معنایی زیادی را حمل میکند، مفید باشد.
کاراکترهای چینی (هانزی) به طور ذاتی حاوی اطلاعات معنایی هستند. برخلاف الفباهای لاتین مانند انگلیسی یا فارسی که در آن هر حرف به یک صدا یا مجموعه ای از صداها نگاشت می شود، هر کاراکتر چینی معنای کاملی را نشان می دهد.
در زبانهایی مانند انگلیسی، این روش یک مجموعه Token (بیایید بهش vocabulary یا واژگان بگوییم) بسیار کوچک ایجاد میکند و هنگام استنتاج، توکنهای ناشناخته بسیار کمی وجود خواهد داشت (کاراکترهایی که در طول آموزش دیده نشده است!).
Vocabulary به مجموعه ای از تمام کلمات یا توکن های منحصر به فردی اطلاق می شود که در یک مجموعه داده یا متن خاص یافت می شوند.
با این حال، این روش نیازمند توکنهای بسیاری برای نمایش یک رشته است که برای عملکرد بد است و برخی از ساختار و معنای متن را از بین میبرد – یک نقطه ضعف برای دقت. هر کاراکتر اطلاعات بسیار کمی را حمل میکند که یادگیری ساختار زیربنایی متن را برای مدل سخت میکند.
رویکرد دیگر این است که متن به کلمات جداگانه تقسیم گردد. در حالی که این روش اجازه میدهد هر توکن حاوی اطلاعات معنایی باشد، دارای نقاط ضعفی است که باید با کلمات ناشناخته بیشتری (مثلاً، تایپهای اشتباه، اصطلاحات عامیانه و غیره) سروکار داشته باشیم. یا باید با شکلهای مختلف یک کلمه (مثلاً “run“، “runs“، “running” و غیره) سروکار داشته باشیم و ممکن است با واژگان(vocabulary) بسیار بزرگ مواجه شویم که برای زبانهایی مانند انگلیسی میتواند به راحتی بیش از نیم میلیون کلمه باشد. استراتژیهای مدرن توکنسازی، تعادلی بین این دو افراط برقرار میکنند، متن را به زیرکلماتی تقسیم میکنند که هم ساختار و معنای متن را حفظ میکنند و هم قادر به رسیدگی به کلمات ناشناخته و شکلهای مختلف یک کلمه هستند.
کاراکترهایی که معمولاً با هم یافت میشوند (مانند رایجترین کلمات) میتوانند یک توکن واحد اختصاص داده شوند که نماینده کل کلمه یا گروه است. کلمات طولانی یا پیچیده، یا کلماتی با چندین تغییر، ممکن است به چندین توکن تقسیم شوند که هر کدام معمولاً نماینده بخش معناداری از کلمه هستند. البته بهترین توکنسازی وجود ندارد؛ هر مدل زبانی با یک روش Tokenization خودش منتشر میشود. تفاوت بین
(tokenizer) در تعداد توکنهای پشتیبانیشده و استراتژی توکنسازی نهفته است.
بیایید ببینیم tokenizer استفاده شده در مدل GPT-2 چگونه یک جمله را پردازش میکند.!
در کد زیر ابتدا tokenizer مربوط به GPT-2 را بارگیری خواهیم کرد. سپس، متن ورودی (که “پرامپت (prompt)” هم نامیده میشود) را به tokenizer میدهیم تا رشتهی ورودی را به اعداد نماینده توکنها رمزگذاری کند. همچنین از decode() استفاده خواهیم کرد تا هر شناسه را به توکن مربوطه تبدیل کنیم.
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
input_ids = tokenizer("It was a dark and stormy", return_tensors="pt").input_ids
input_ids
tensor([[1026, 373, 257, 3223, 290, 6388, 88]])
for t in input_ids[0]:
print(t, "\t:", tokenizer.decode(t))
tensor(1026) : It tensor(373) : was tensor(257) : a tensor(3223) : dark tensor(290) : and tensor(6388) : storm tensor(88) : y
همانطور که میبینید، Tokenizer رشته ورودی را به مجموعهای از توکنها تقسیم میکند و به هر کدام یک شناسه منحصر به فرد اختصاص میدهد.
اکثر کلمات توسط یک توکن نمایندگی میشوند، اما “stormy” با دو توکن نمایندگی شده است: یکی برای “storm” (شامل فاصله قبل از کلمه) و دیگری برای پسوند “y“. این به مدل اجازه میدهد تا بیاموزد که “stormy” با “storm” مرتبط است و اینکه پسوند “y” در انگلیسی اغلب برای تبدیل اسامی به صفات استفاده میشود. با واژگان حدود ۵۰,۰۰۰ توکن، Tokenizer موجود در GPT-2 میتواند تقریباً هر متن ورودی را به طور کارآمد نمایش دهد و به طور متوسط حدود ۱.۳ توکن در هر کلمه دارد.
نکته:
با اینکه معمولاً درباره آموزش Tokenizer صحبت میکنیم، این هیچ ارتباطی با آموزش مدل ندارد. آموزش مدل بهطور تصادفی (غیرقابلپیشبینی: non-deterministic) است، در حالی که یک Tokenizer را با استفاده از یک فرآیند آماری که مشخص میکند کدام زیرکلمات برای یک مجموعه داده معین بهترین انتخاب هستند تعیین میشود. نحوه انتخاب این که چگونه زیرکلمات را در الگوریتم Tokenizer انتخاب کنیم یک تصمیم طراحی تعیینپذیر است. ما به استراتژیهای مختلف Tokenizer نمیپردازیم، اما برخی از محبوبترین رویکردهای زیرکلمات عبارتند از Byte-level BPE، که در GPT-2 استفاده میشود، WordPiece و SentencePiece.
پیشبینی احتمالات
GPT-2 به عنوان یک مدل زبان علّی یا causal language model (که به آن خودهمبسته: auto-regressive نیز گفته میشود) آموزش داده شده است، به این معنی که آموزش دیده تا توکن بعدی را در یک دنباله با توجه به توکنهای قبلی پیشبینی کند.
کتابخانهtransformers ابزارهای سطح بالایی دارد که به ما امکان استفاده از چنین مدلی برای تولید متن یا انجام وظایف دیگر میدهد. درک اینکه چگونه مدل پیشبینیهای خود را با بررسی مستقیم آنها در این کار مدلسازی زبان انجام میدهد، مفید است.
با بارگذاری مدل شروع میکنیم:
from transformers import AutoModelForCausalLM
gpt2 = AutoModelForCausalLM.from_pretrained("gpt2")
نکته
به استفاده از AutoTokenizer و AutoModelForCausalLM توجه کنید. کتابخانهtransformers از صدها مدل و Tokenizerمربوط به آنها پشتیبانی میکند.
به جای یادگیری نام هر Tokenizerو کلاس مدل، ما از AutoTokenizer و AutoModelFor* استفاده خواهیم کرد.
برای مدل خودکار، ما نیاز داریم مشخص کنیم که برای کدام وظیفه از مدل استفاده میکنیم، مانند طبقهبندی (AutoModelForSequenceClassification) یا تشخیص اشیا (AutoModelForObjectDetection).
در مورد GPT-2، ما از کلاسی که مربوط به وظیفه مدلسازی زبان علّی است استفاده خواهیم کرد. هنگام استفاده از کلاسهای خودکار، transformers یک کلاس پیشفرض مناسب را بر اساس پیکربندی مدل انتخاب خواهد کرد. به عنوان مثال، در پس این کد، از GPT2Tokenizer و GPT2LMHeadModel استفاده خواهد کرد.
outputs = gpt2(input_ids) outputs.logits.shape # An output for each input token
torch.Size([1, 7, 50257])
بُعد اول خروجی تعداد بچها (1، زیرا ما فقط یک دنباله را از طریق مدل اجرا کردهایم) است. بُعد دوم طول دنباله، یا تعداد توکنهای دنباله ورودی (در مورد ما 7) است. بُعد سوم نیز اندازه واژگان است. ما برای هر توکن در دنباله اصلی یک لیست شامل تقریباً ۵۰ هزار عدد دریافت میکنیم. اینها خروجیهای خام مدل یا logitها هستند که با توکنهای موجود در واژگان مطابقت دارند. برای هر توکن ورودی، مدل پیشبینی میکند که هر توکن در واژگان چقدر احتمال دارد که دنباله را تا آن نقطه ادامه دهد. با جمله نمونه ما، مدل logitها را برای “It”، “It was”، “It was a”، و غیره پیشبینی خواهد کرد. مقادیر بالاتر logit به این معنی است که مدل توکن مربوطه را به عنوان ادامه محتملتر دنباله در نظر میگیرد. جدول زیر دنبالههای ورودی، محتملترین شناسه توکن و توکن مربوطه آن را نشان میدهد.
logitها خروجی خام مدل هستند (یک لیست از اعداد مانند [0.1، 0.2، 0.01، …]). ما میتوانیم از logitها برای انتخاب محتملترین توکن برای ادامه دنباله استفاده کنیم. با این حال، ما همچنین میتوانیم logitها را به احتمالات تبدیل کنیم، همانطور که به زودی خواهیم دید.
| دنباله ورودی | شناسه محتملترین توکن بعدی | توکن مربوطه |
|---|---|---|
| It | 318 | is |
| It was | 257 | a |
| It was a | 845 | very |
| It was a dark | 1755 | night |
| It was a dark and | 4692 | cold |
| It was a dark and storm | 88 | y |
| It was a dark and stormy | 1755 |
(let’s figure this one) |
argmax() میتوانیم شاخص توکن با بالاترین مقدار را پیدا کنیم:final_logits = gpt2(input_ids).logits[0, -1] # The last set of logits final_logits.argmax() # The position of the maximum
tensor(1755)
عدد 1755 با شناسه توکنی که مدل آن را بهعنوان محتملترین دنباله برای رشته ورودی “It was a dark and stormy” در نظر میگیرد، مطابقت دارد. با رمزگشایی این توکن، میتوانیم ببینیم که این مدل چندین کلیشه داستانی را میشناسد:
tokenizer.decode(final_logits.argmax())
' night'
پس “night” محتملترین توکن است. این با توجه به آغاز جملهای که بهعنوان ورودی ارائه دادیم منطقی است. در واقع مدل با استفاده از الگوریتمی به نام توجه-به-خود (Self-attention) که اساس سازنده ترنسفورمرهاست یاد میگیرد که چگونه به توکنهای دیگر توجه کند. بهطور شهودی، توجه-به-خود به مدل اجازه میدهد تا تشخیص دهد هر توکن چقدر به معنای عبارت کمک میکند.
نکته
مدلهای ترنسفورمر شامل بسیاری از این لایههای توجه هستند که هر یک در یک جنبه خاص از ورودی تخصص دارند. برخلاف سیستمهای اکتشافی (heuristics)، این جنبهها یا ویژگیها در طول آموزش یاد گرفته میشوند، نه اینکه از پیش تعیین شده باشند.
حالا بیایید ببینیم کدام توکنهای دیگر نامزدهای احتمالی بودند با انتخاب ۱۰ مقدار برتر:
import torch
top10_logits = torch.topk(final_logits, 10)
for index in top10_logits.indices:
print(tokenizer.decode(index))
night day evening morning afternoon summer time winter weekend ,
ما باید logitها را به احتمالات تبدیل کنیم تا ببینیم مدل در مورد هر پیشبینی چقدر اطمینان دارد. این کار را با مقایسه هر مقدار با سایر مقادیر پیشبینی شده و نرمالسازی انجام میدهیم تا همه اعداد مجموعاً برابر با ۱ شوند. این دقیقاً همان کاری است که softmax() انجام میدهد. کد زیر از softmax() استفاده میکند تا ۱۰ توکن برتر از نظر احتمال و احتمالات مربوط به آنها را بر اساس مدل چاپ کند:
top10 = torch.topk(final_logits.softmax(dim=0), 10)
for value, index in zip(top10.values, top10.indices):
print(f"{tokenizer.decode(index):<10} {value.item():.2%}")
night 46.18% day 23.46% evening 5.87% morning 4.42% afternoon 4.11% summer 1.34% time 1.33% winter 1.22% weekend 0.39% , 0.38%
قبل از ادامه، پیشنهاد می کنیم کد بالا را خودتان اجرا کرده و آزمایش کنید. چندتا ایده که توصیه میشود آنها را امتحان کنید:
- تغییر چند کلمه: سعی کنید صفتها (مثلا، “dark” و “stormy”) را در ورودی تغییر داده و مشاهده کنید چگونه پیشبینیهای مدل تغییر میکند.
آیا کلمه پیشبینیشده همچنان “night” است؟
احتمالات چگونه تغییر میکند؟ - تغییر رشته ورودی: رشته های ورودی مختلف را امتحان کرده و مشاهده کنید چگونه پیشبینیهای مدل تغییر می کند.
آیا پیشبینیهای مدل منطقی است؟ - گرامر: اگر رشته ای که از نظر گرامری جمله صحیحی نباشد را ارائه کنید چه اتفاقی می افتد؟
مدل چگونه با آن برخورد می کند؟
به احتمالات برتر نگاه کنید!
تولید متن
هنگامی که چگونگی پیشبینیهای مدل برای توکن بعدی در یک توالی را بدانیم، تولید متن با بازخوراندن مکرر پیشبینیهای مدل به خودش آسان خواهد شد. میتوانیم gpt2(ids)را فراخوانی کرده، یک ID توکن جدید تولید کنیم، آن را به لیست اضافه کرده و دوباره تابع را فراخوانی کنیم. برای راحتتر کردن تولید چندین کلمه، مدلهای خودهمبسته transformers یک متد generate() دارند که برای این حالت ایدهآل است.
با یک مثال آن را بررسی کنیم:
output_ids = gpt2.generate(input_ids, max_new_tokens=20)
decoded_text = tokenizer.decode(output_ids[0])
print("Input IDs", input_ids[0])
print("Output IDs", output_ids)
print(f"Generated text: {decoded_text}")
Input IDs tensor([1026, 373, 257, 3223, 290, 6388, 88])
Output IDs tensor([ 1026, 373, 257, 3223, 290, 6388, 88, 1755, 13,
383, 2344, 373, 19280, 11, 290, 262, 15114, 547,
7463, 13, 383, 2344, 373, 19280, 11, 290, 262])
Generated text: It was a dark and stormy night. The wind was blowing,
and the clouds were falling. The wind was blowing, and the
وقتی در بخش قبلی متد gpt2() را اجرا کردیم، لیستی از logitها برای هر توکن از میان واژگان (50257) را برگرداند. سپس، احتمالات را محاسبه و محتملترین توکن را انتخاب کردیم.
generate()این منطق را برایمان ساده میکند. این متد چندین بار پیشبینی را انجام داده، توکن بعدی را به طور مکرر پیشبینی کرده و آن را به توالی ورودی اضافه میکند. generate() به ما IDهای توکن توالی نهایی را ارائه میدهد که خروجی آن هر دو توکن ورودی و جدید را شامل میشود. سپس، با استفاده از متد decode() ازtokenizer میتوانیم آن را دوباره به متن تبدیل کنیم.
روشهای بسیاری برای تولید متن وجود دارد. روشی که در اینجا انجام دادیم، انتخاب محتملترین توکن بود که به greedy decoding شناخته میشود. اگرچه این روش ساده است، گاهی اوقات میتواند به نتایج غیر بهینه منجر شود، به ویژه برای تولید توالیهای متنی طولانیتر greedy decoding میتواند مشکلساز باشد چراکه به احتمال کلی یک جمله توجه نکرده و فقط بر روی کلمه بعدی تمرکز میکند. به عنوان مثال، با توجه به کلمه شروع Sky و انتخابهای blueو rocketsبرای کلمه بعدی، greedy decoding ممکن است Sky blue را ترجیح دهد زیرا blue در ابتدا بیشتر محتمل به نظر میرسد که پس از Sky بیاید. با این حال، این روش ممکن است یک توالی کلی هماهنگتر و محتملتر مانند Sky rockets soar ( به معنی موشک های آسمان اوج می گیرند) را نادیده بگیرد. بنابراین، greedy decoding گاهی اوقات میتواند از محتملترین توالی کلی صرف نظر کرده و به تولید متن کمتر بهینه منجر شود.
به جای یک توکن در هر زمان، تکنیکهایی مانند beam search چندین ادامه ممکن از توالی را بررسی میکنند و محتملترین توالی از ادامهها را برمیگردانند. این روش محتملترین num_beams از فرضیهها را در طول تولید نگه داشته و محتملترین را انتخاب میکند.
beam_output = gpt2.generate(
input_ids,
num_beams=5,
max_new_tokens=30,
)
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
It was a dark and stormy night. "It was dark and stormy," he said. "It was dark and stormy," he said.
همانطور که متوجه شدید، خروجی شامل تکرارهای زیادی از یک توالی است. پارامترهای متعددی وجود دارند که میتوانیم کنترل کنیم تا نتیجهی بهتری داشته باشیم.
به دو مثال زیر توجه کنید:
- repetition_penalty مقداری که برای توکنهای از قبل تولید شده جریمه در نظر میگیرد تا از تکرار جلوگیری شود. مقدار پیشفرض 1.2 معمولا خوب است.
- bad_words_ids لیستی از توکنهایی که نباید تولید شوند (مثلاً برای جلوگیری از تولید کلمات توهینآمیز).
حال ببینیم با جریمه دادن به تکرار چه چیزی به دست میآوریم:
beam_output = gpt2.generate(
input_ids,
num_beams=5,
repetition_penalty=1.2,
max_new_tokens=38,
)
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
It was a dark and stormy night. "There was a lot of rain," he said. "It was very cold." He said he saw a man with a gun in his hand.
این نتیجه بسیار بهتر است.
از کدام استراتژی تولید استفاده کنیم؟ همانطور که در یادگیری ماشین معمول است این پاسخ بستگی به مساله دارد!
Beam search زمانی خوب عمل میکند که طول متن مورد نظر تا حدی قابل پیشبینی باشد. این مورد در وظایفی مانند خلاصهسازی یا ترجمه صادق است اما نه برای تولید بازمتن، جایی که طول خروجی میتواند بسیار متغیر باشد و منجر به تکرار گردد. اگرچه میتوانیم مدل را به گونهای مهار کنیم که از تکرار خود جلوگیری کند، این کار میتواند منجر به عملکرد ضعیفتر نیز شود. همچنین توجه داشته باشید که beam search نسبت به greedy search کندتر خواهد بود زیرا نیاز دارد تا برای چندین beam به صورت همزمان استنتاج انجام دهد، که میتواند برای مدلهای بزرگ مشکلساز باشد.
وقتی با greedy search و beam search تولید میکنیم، مدل را به تولید متنی با توزیع کلمات بعدی با احتمال بالا سوق میدهیم. جالب است که زبان انسانی با کیفیت بالا چنین توزیعی را دنبال نمیکند. متن انسانی تمایل به غیرقابل پیشبینی بودن بیشتری دارد. یک مقاله عالی در مورد این مشاهده ضد شهودی(counter-intuitive)، مقالهی The Curious Case of Neural Text Degeneration است. نویسندگان فرض میکنند که زبان انسانی از کلمات قابل پیشبینی اجتناب میکند – مردم بهینهسازی میکنند تا چیزهای واضح را بیان نکنند. این مقاله یک روش به نام nucleus sampling را پیشنهاد میکند.
با نمونهگیری، توکن بعدی را با نمونهگیری از توزیع احتمالی توکنهای بعدی انتخاب میکنیم. این بدان معناست که نمونهگیری یک فرآیند تولید تعیینشده نیست. اگر توکنهای ممکن بعدی night (60%)، day (35%) و apple (5%) باشند، به جای انتخاب night (با greedy search)، از توزیع نمونهگیری خواهیم کرد. به عبارت دیگر، ۵٪ احتمال انتخاب “apple” وجود دارد حتی اگر یک توکن با احتمال پایین باشد و منجر به تولید نامعقول شود. نمونهگیری از ایجاد متن تکراری جلوگیری کرده و در نتیجه منجر به تولیدهای متنوعتری میشود. نمونهگیری در transformers با استفاده از پارامتر do_sample انجام میشود.
from transformers import set_seed
# Setting the seed ensures we get the same results every time we run this code
set_seed(70)
sampling_output = gpt2.generate(
input_ids,
do_sample=True,
max_length=34,
top_k=0, # We'll come back to this parameter
)
print(tokenizer.decode(sampling_output[0], skip_special_tokens=True))
It was a dark and stormy day until it broke down the big canvas on my sleep station, making me money dilapidated, and, with a big soothing m ug
ما میتوانیم توزیع احتمالی را قبل از نمونهگیری از آن تغییر داده، و آن را با استفاده از یک پارامتر دما(temperature) “تیزتر” یا “مسطحتر” کنیم. temperatureبالاتر از یک باعث افزایش تصادفی بودن توزیع میشود که میتوانیم از آن برای تشویق به تولید توکنهای کمتر محتمل استفاده کنیم. temperatureبین 0 و 1 تصادفی بودن را کاهش میدهد، احتمال توکنهای محتملتر را افزایش میدهد و از پیشبینیهایی که ممکن است بیش از حد غیرمنتظره باشند جلوگیری میکند. temperature برابر با 0 نیز تمام احتمال را به محتملترین توکن بعدی منتقل میکند که معادل با greedy decoding است. اثر این پارامتر temperatureرا بر متن تولید شده در مثال زیر مقایسه کنید.
sampling_output = gpt2.generate(
input_ids,
do_sample=True,
temperature=0.4,
max_length=40,
top_k=0,
)
print(tokenizer.decode(sampling_output[0], skip_special_tokens=True))
It was a dark and stormy night, and I was alone. I was in the middle o f the night, and I was suddenly awakened bygoodness, and I was thinkin g of the old man
sampling_output = gpt2.generate(
input_ids,
do_sample=True,
temperature=0.001,
max_length=40,
top_k=0,
)
print(tokenizer.decode(sampling_output[0], skip_special_tokens=True))
It was a dark and stormy night. The wind was blowing, and the clouds w ere falling. The wind was blowing, and the clouds were falling. The wi nd was blowing, and the clouds were
sampling_output = gpt2.generate(
input_ids,
do_sample=True,
temperature=3.0,
max_length=40,
top_k=0,
)
print(tokenizer.decode(sampling_output[0], skip_special_tokens=True))
It was a dark and stormy corporation street compliment ideallylake ame nded Churchill ty set crou 175 dualKing Bucc ceiling wrapped.......my tryhouse fragileREG Robinson lower display magn Simon spectral warmth HP274 Lur Welsh
خب، تست اول بسیار منسجمتر از تست دوم است. دومی که از temperature بسیار پایین استفاده میکند، تکراری است (مشابه greedy decoding). در نهایت، نمونه سوم با temperature بسیار بالا، متن بیمعنا تولید میکند.
یک پارامتر که احتمالاً متوجه آن شدهاید، پارامتر top_k است. top_k چیست؟ نمونهگیری Top-K یک روش نمونهگیری ساده است که در آن تنها K توکن بعدی محتمل در نظر گرفته میشوند. برای مثال، با استفاده از top_k=5، روش تولید ابتدا پنج توکن محتملترین را فیلتر کرده و احتمالات را مجدداً توزیع میکند تا مجموع آنها به یک برسد.
sampling_output = gpt2.generate(
input_ids,
do_sample=True,
max_length=40,
top_k=10,
)
print(tokenizer.decode(sampling_output[0], skip_special_tokens=True))
It was a dark and stormy night and I was not expecting to be here at 9 :30 AM. It felt cold and rainy. I didn't know why I was here. There wa s no
خب… این میتواند بهتر باشد. یکی از مشکلات نمونهگیری Top-K این است که تعداد کاندیداهای مرتبط در عمل میتواند بسیار متفاوت باشد. اگر top_k=5 را تعریف کنیم، برخی توزیعها هنوز شامل توکنهایی با احتمال بسیار پایین خواهند بود، در حالی که برخی دیگر فقط شامل توکنهایی با احتمال بالا خواهند بود.
استراتژی نهایی تولید که بررسی خواهیم کرد، نمونهگیری Top-p (که به عنوان نمونهگیری nucleus نیز شناخته میشود) است. به جای نمونهگیری از K کلمه با بالاترین احتمال، از تمام کلمات محتملی که مجموع احتمالشان از یک مقدار مشخص بیشتر است استفاده خواهیم کرد. اگر از top_p=0.94 استفاده کنیم، ابتدا فقط کلمات محتملی را نگه میداریم که مجموع احتمال آنها 0.94 یا بیشتر است. سپس احتمالها را دوباره توزیع میکنیم و نمونهگیری معمولی را انجام میدهیم. بیایید آن را در عمل ببینیم.
sampling_output = gpt2.generate(
input_ids,
do_sample=True,
max_length=40,
top_p=0.94,
top_k=0,
)
print(tokenizer.decode(sampling_output[0], skip_special_tokens=True))
It was a dark and stormy hour, a formation of what looked like beggar to an armoire-upper of the home that flickered down the cobbled main r oad, leaned slowly against
هم Top-K و هم Top-p به طور معمول در عمل استفاده میشوند. حتی میتوان آنها را ترکیب کرد تا کلمات با احتمال پایین حذف شوند و کنترل بیشتری بر تولید داشته باشیم. مشکل روشهای تولید تصادفی این است که متن تولید شده لزوماً دارای انسجام نیست.
ما سه روش مختلف تولید را بررسی کردهایم: جستجوی حریصانه، دیکدینگ beam-search، و نمونهگیری (با کنترل بیشتر با temperature، Top-K و Top-p).
در اینجا چند پیشنهاد برای آزمایش کردن در صورتی که تمایل دارید بیشتر آزمایش کنید، ارائه شده است:
- با مقادیر مختلف پارامترها آزمایش کنید. افزایش تعداد beams چگونه بر کیفیت تولید شما تأثیر میگذارد؟ اگر مقدار
top_pخود را کاهش یا افزایش دهید چه اتفاقی میافتد؟ - یک روش برای کاهش تکرار در Beam Search، معرفی جریمه برای n-grams (توالی کلمات با n کلمه) است. این کار با استفاده از پارامتر
no_repeat_ngram_sizeقابل تنظیم است که از تکرار همان n-gram جلوگیری میکند. برای مثال، اگر ازno_repeat_ngram_size=4استفاده کنید، تولید هرگز شامل چهار کلمه متوالی یکسان نخواهد بود. - یک روش جدیدتر به نام جستجوی تضادی (contrastive search)، میتواند خروجی بلند و منسجمی تولید کند و در عین حال از تکرار جلوگیری کند. این کار با در نظر گرفتن هر دو احتمالهای پیشبینی شده توسط مدل و شباهت با متن قبلی انجام میشود. این میتواند با استفاده از
penalty_alphaوtop_kکنترل شود.
اگر همه اینها بیش از حد تجربی به نظر میرسد، به این دلیل است که همین طور است. تولید متن یک حوزه فعال پژوهشی است و مقالات جدیدی با پیشنهادات مختلف، مانند فیلترینگ پیچیدهتر، منتشر میشوند. ما به طور مختصر اینها را در فصل آخر بحث خواهیم کرد. هیچ قانون واحدی برای همه مدلها کار نمیکند، بنابراین همیشه مهم است که با تکنیکهای مختلف آزمایش کنید.
تعمیم بدون نیاز به آموزش (Zero-Shot Generalization)
تولید متن قطعا یک کاربرد جذاب و سرگرمکننده از ترنسفورمرها است، اما نوشتن داستان جعلی دربارهی تکشاخها دلیل محبوبیت این مدلها نیست!
اولین مثال در بلاگپست مربوط به انتشار GPT-2 یک خبر معروف در مورد تک شاخ ها بود (https://openai.com/research/better-language-models).
برای پیشبینی خوب توکن بعدی، این مدلها باید مقدار زیادی دربارهی جهان پیرامون یاد بگیرند. ما میتوانیم از این قابلیت برای انجام وظایف مختلف استفاده کنیم. به عنوان مثال، به جای آموزش یک مدل اختصاصی برای ترجمه، میتوانیم یک مدل زبانی قدرتمند را با یک پرامپت مانند این ورودی دهیم:
ترجمه جمله زیر از انگلیسی به فرانسوی: ورودی: The cat sat on the mat. ترجمه:
هر چه مدل قدرتمندتر باشد، میتواند وظایف بیشتری را بدون آموزش اضافی انجام دهد. این انعطافپذیری، ترنسفورمرها را بسیار قدرتمند کرده که در سالهای اخیر باعث محبوبیت آنها شده است.
برای دیدن این موضوع در عمل، بیایید از GPT-2 به عنوان یک مدل طبقهبندی استفاده کنیم. به طور خاص، ما نقدهای فیلم را در دو کلاس مثبت یا منفی طبقهبندی خواهیم کرد، یک تسک کلاسیک در حوزه پردازش زبان طبیعی (NLP)!
برای جذابتر شدن کار، ما از رویکرد بدون نیاز به آموزش (zero-shot) استفاده خواهیم کرد، به این معنا که به مدل هیچ دادهی برچسبداری نخواهیم داد. در عوض، با یک پرامپت از آن میخواهیم احساسات را پیشبینی کند!
برای انجام این کار، نقد را در قالب یک الگوی پرامپت قرار میدهیم که به مدل زمینهای میدهد تا متوجه شود که از آن چه میخواهیم. پس از قرار دادن پرامپت در مدل، به پیشبینی آن برای توکن بعدی نگاه میکنیم و میبینیم که کدام توکن محتملتر است: “positive” یا “negative”؟ برای این کار، بیایید IDهای مربوط به این توکنها را پیدا کنیم.
# Check the token IDs for the words ' positive' and ' negative'
# (note the space before the words)
tokenizer.encode(" positive"), tokenizer.encode(" negative")
([3967], [4633])
def score(review):
"""Predict whether it is positive or negative
This function predicts whether a review is positive or negative
using a bit of clever prompting. It looks at the logits for the
tokens ' positive' and ' negative' (note the space before the
words), and returns the label with the highest score.
"""
prompt = f"""Question: Is the following review positive or
negative about the movie?
Review: {review} Answer:"""f
input_ids = tokenizer(prompt, return_tensors="pt").input_ids #1
final_logits = gpt2(input_ids).logits[0, -1] #2
if final_logits[3967] > final_logits[4633]: #3
print("Positive")
else: #3
print("Negative")
نکات کد بالا که در کامنت با شماره 1 تا 3 مشخص شده است:
- پرامپت را توکنگذاری کن
- logitهای مربوط به هر توکن در واژگان را بگیر. توجه داشته باشید که ما از
gpt2()به جایgpt2.generate()استفاده میکنیم، زیراgpt2()لاگیتهای مربوط به هر توکن در واژگان را برمیگرداند، در حالی کهgpt2.generate()فقط توکن انتخاب شده را برمیگرداند. - بررسی کن که آیا logit برای توکن مثبت بیشتر از logit برای توکن منفی است یا خیر.
میتوانیم این دستهبندیکنندهی zero-shot را روی چند مرور جعلی امتحان کنیم تا ببینیم چگونه عمل میکند:
score("This movie was terrible!")
Negativ
score("That was a delight to watch, 10/10 would recommend :)")
Positive
score("A complex yet wonderful film about the depravity of man") # A mistake
Negative
Hands-On Generative AI with Transformers and Diffusion Models
مطالب زیر را حتما مطالعه کنید

بهینهسازی ترجیحی برای استدلال چندوجهی و مقاله MPO

معرفی Min P: روش جدید نمونهبرداری توکن برای LLMها

مدلهای انتشار (Diffusion Models) و کتابخانه diffusers – بخش 2

فوق العاده مناسب و مشخصا متشکل از مجموعه ای از زحمات و تلاش برای گسترش دانش. ادامه بدید جناب اخوان