ترنسفورمر (Transformer) چیست؟
ترنسفورمر یک معماری جدید شبکه عصبی است که در تسکهایی نظیر ترجمه ماشینی استفاده میشود. مزیت این روش نسبت به روشهایی نظیر شبکه های recurrent نظیر RNNها، LSTM و GRU علاوه بر افزایش دقت چشمگیر (در برخی از تسکها)، موازی سازی است. چرا که در یک واحد بازگشتی شما باید ورودی هر لحظه زمانی را به مدل بدهید و پس از به روز شدن حافظه آن واحد ورودی لحظهی بعدی را بدهید که این کار باعث کند شدن آموز و پاسخ مدل خواهد شد. اما در ترنسفورمرها ورودی در یک لحظه به مدل داده شده و با روش های دیگر ترتیب کلمات یا ورودی از جنس سری زمانی را به شبکه میفهمانیم.
معماری ترنسفورمر اولین بار در مقالهی Attention is All You Need مطرح شد. پیادهسازی تنسرفلوی آن نیز به عنوان بخشی از بسته Tensor2Tensor در دسترس است. همچنین گروه NLP دانشگاه هاروارد یک راهنمای حاشیه نویسی مقاله با پیاده سازی PyTorch ایجاد کرده که به درک مقاله میتواند کمکتان کند.
توجه یا Attention
توجه یک مفهوم است که به بهبود عملکرد برنامههای ترجمه ماشین (machine translation) شبکه عصبی کمک کرده است. اگر قبلا دورهی شبکههای بازگشتی (RNN) ها را دیده باشید، در قسمت آخر در مورد مکانیزم توجه صحبت شده است.
یک نگاه سطح بالا به ترنسفورمرها

با نگاه اولیه به داخل این جعبهسیاه، یک خودرمزگذار (اتوانکودر) شامل یک مؤلفهی رمزگذاری، یک مؤلفه رمزگشایی و اتصالات آنها را میتوان دید.
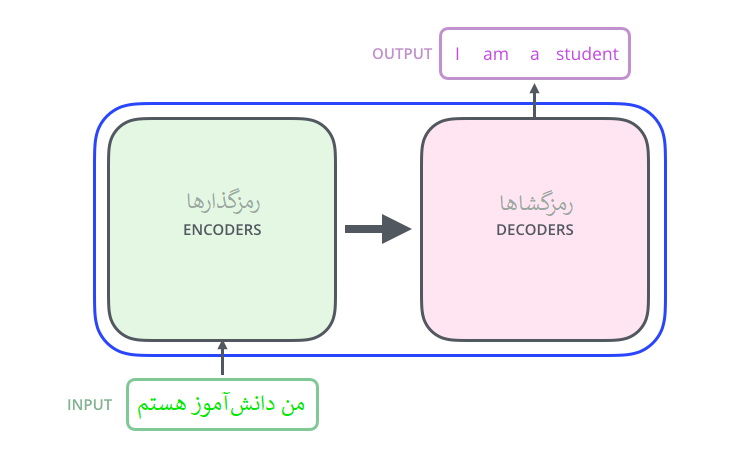
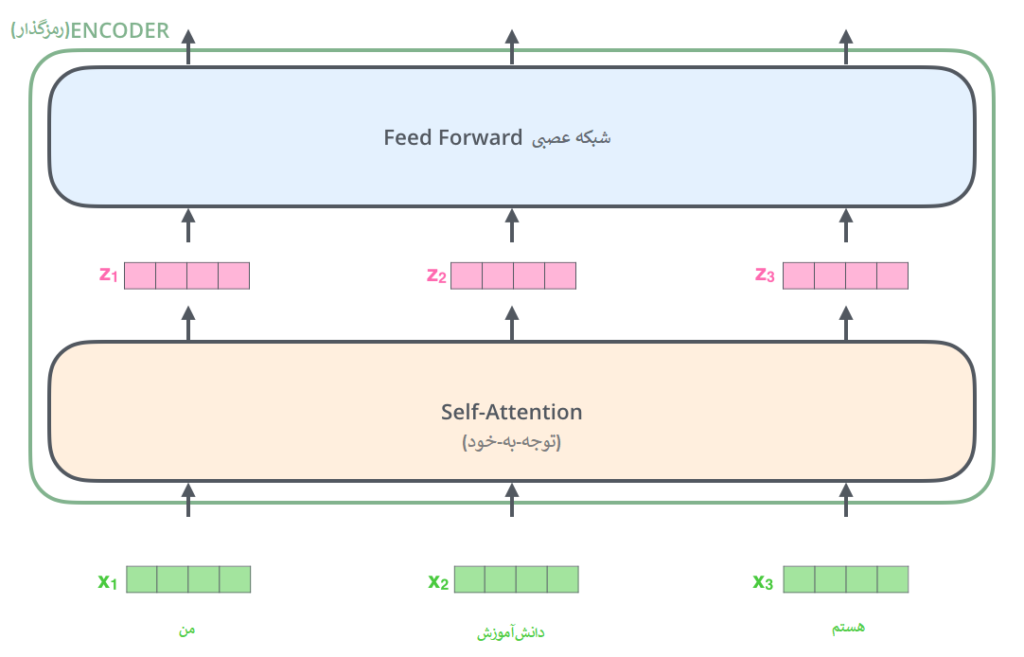
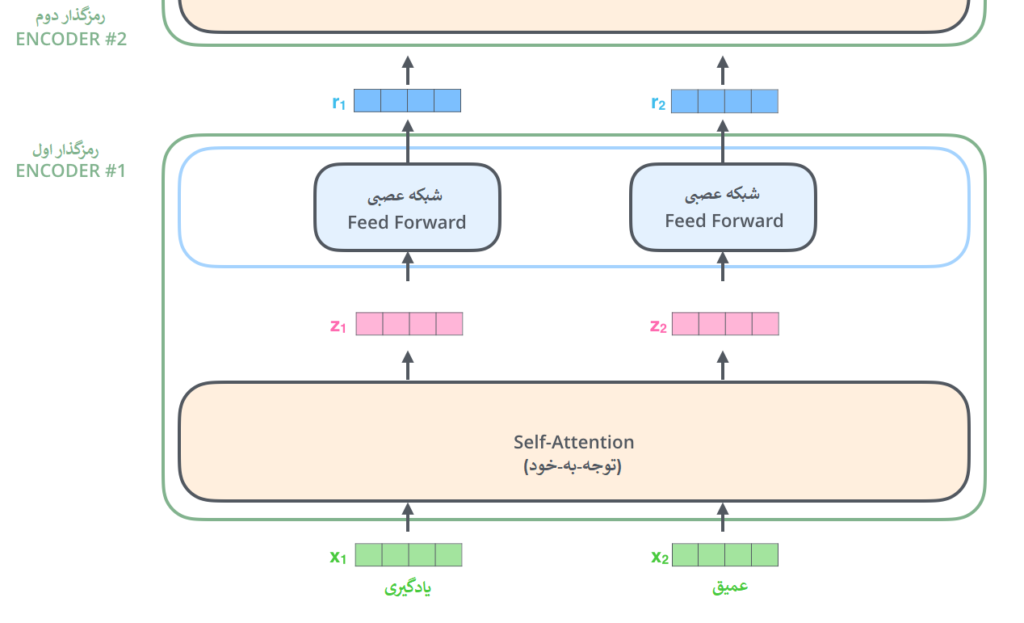
مؤلفه رمزگذاری شامل تعدادی رمزگذار(انکودر) پشت هم است (شش عدد از آنها را روی هم قرار می دهد – هیچ چیز جادویی در مورد عدد شش وجود ندارد، قطعاً می توان با ترتیبات دیگری آزمایش کرد). جزء رمزگشایی نیز شامل به همان تعداد واحد رمزگشا(دیکودر) است.
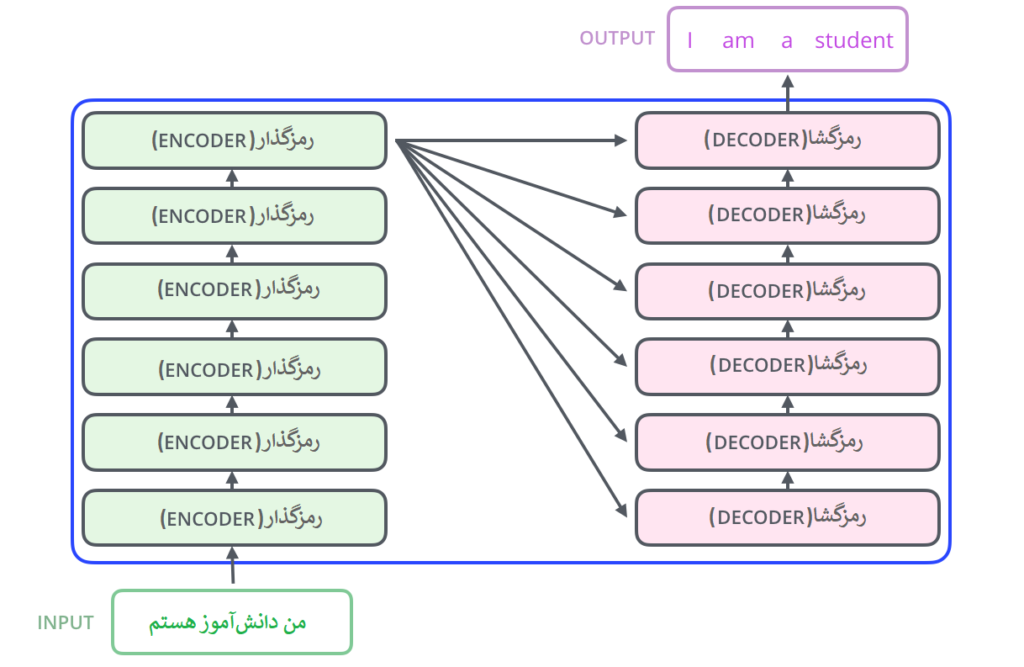
رمزگذارها از نظر ساختار همه باهم یکسانند، البته بدیهی است که هر رمزگذار وزن های خودش را دارد. هر واحد رمزگذار به دو زیر لایه مطابق تصویر زیر تقسیم می شود:
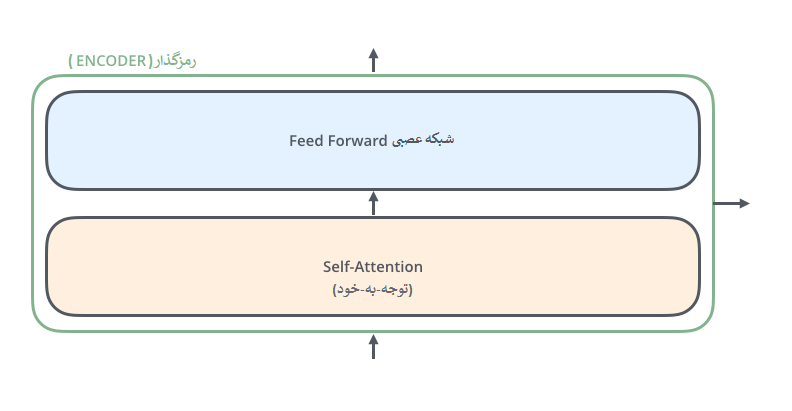
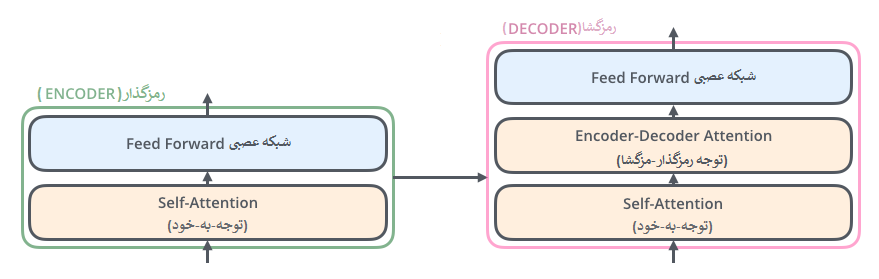
هر رمزگذار ابتدا ورودیش را به یک لایهی توجه-به-خود (Self-attention) میدهد. لایهای که به رمزگذار کمک میکند تا در کد کردن هر کلمه، کلمات دیگر در جمله ورودی را نیز در نظر بگیرد، دلیل اینکار در ادامه توضیح داد خواهد شد.
سپس خروجی لایهی توجه-به-خود به یک شبکه عصبی داده می شود. این شبکه عصبی بهطور مستقل برای هر موقعیت از کلمات یک جمله اعمال میشود.
رمزگشا نیز هر دو لایه را دارد، اما بین آنها یک لایه توجه وجود دارد که به رمزگشا کمک می کند تا روی قسمت های مربوطه جمله ورودی تمرکز کند (همان چیزی که مکانیزم توجه در مدل های seq2seq انجام می دهد).
درک تصویری تنسورها
اکنون که اجزای اصلی مدل را دیدیم، بیایید به بررسی بردارها/تنسورهای مختلف و چگونگی جران این تنسورها از ورودی تا خروجی یک مدل آموزش دیده بپردازیم.
همانطور که در اکثر کاربردهای پردازش زبان طبیعی یا NLP ما کلمات ورودی را به یک بردار امبدینگ (Embedding) تبدیل میکنیم، در اینجا هم همین کار را انجام میدهیم.

اکنون در حال رمزگذاری هستیم!
توجه-به-خود در سطح بالا
”The animal didn’t cross the street because it was too tired”
- “در طبیعت شیر به عنوان یک شکارچی خطرناک شناخته میشود.”
- “نوشیدن روزانه حداقل یک لیوان شیر برای رشد و استحکام استخوانها ضروری است.”

جزئیات بیشتر توجه-به-خود (Self-Attention)
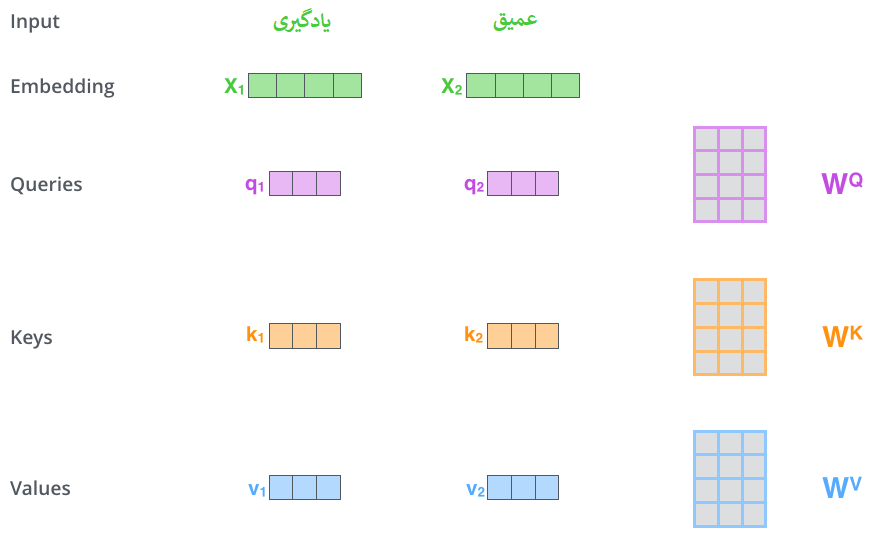
ضرب x1 در ماتریس وزن WQ، q1، بردار “پرسش” (query) مرتبط با آن کلمه را تولید میکند. در نهایت، یک پروجکشن “پرسش” (query)، یک پروجکشن “کلید” (key) و یک پروجکشن “مقدار” (value) از هر کلمه در جمله ورودی ایجاد میکنیم.
بردارهای “پرسش” (query)، “کلید” (key) و “مقدار” (value) چه هستند؟
اینها انتزاعاتی هستند که برای محاسبه و تفکر درباره توجه (attention) مفید هستند. هنگامی که ادامه مطلب را بخوانید و با نحوه محاسبه توجه آشنا شوید، تقریباً همه چیزهایی که باید در مورد نقش هر یک از این بردارها بدانید را خواهید دانست.
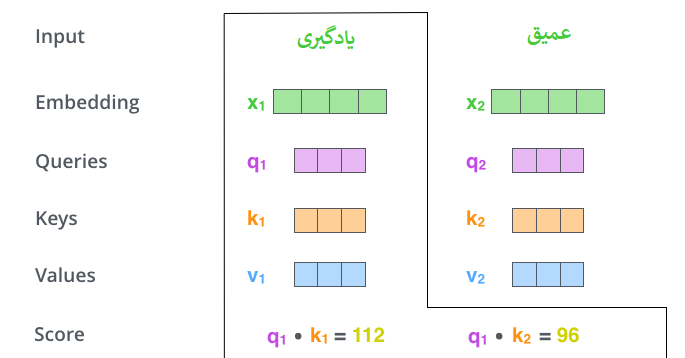
مرحله دوم در محاسبه توجه بهخود (self-attention) این است که یک امتیاز (score) محاسبه کنید. فرض کنید در حال محاسبه توجه بهخود برای اولین کلمه در این مثال، “یادگیری” هستیم. باید هر کلمه از جمله ورودی را نسبت به این کلمه امتیازدهی کنیم. این امتیاز تعیین میکند که چقدر باید بر سایر قسمتهای جمله ورودی تمرکز کنیم زمانی که کلمهای را در یک موقعیت خاص رمزگذاری میکنیم.
امتیاز با گرفتن حاصلضرب نقطهای (dot product) بردار پرسش (query) با بردار کلید (key) کلمه مربوطهای که در حال امتیازدهی آن هستیم محاسبه میشود. بنابراین اگر در حال پردازش توجه بهخود برای کلمهای در موقعیت شماره 1 باشیم، اولین امتیاز حاصلضرب نقطهای q1 و k1 خواهد بود. امتیاز دوم حاصلضرب نقطهای q1 و k2 خواهد بود.
مرحله سوم و چهارم این است که امتیازها را بر 8 تقسیم کنیم (ریشه مربع بُعد بردارهای کلید استفاده شده در مقاله – 64. این کار منجر به داشتن گرادیانهای پایدارتر میشود. ممکن است مقادیر دیگری نیز در اینجا وجود داشته باشد، اما این مقدار پیشفرض است)، سپس نتیجه را از طریق عملیات softmax عبور دهیم. Softmax امتیازها را نرمالسازی میکند تا همه آنها مثبت شده و مجموعشان برابر با 1 شود.
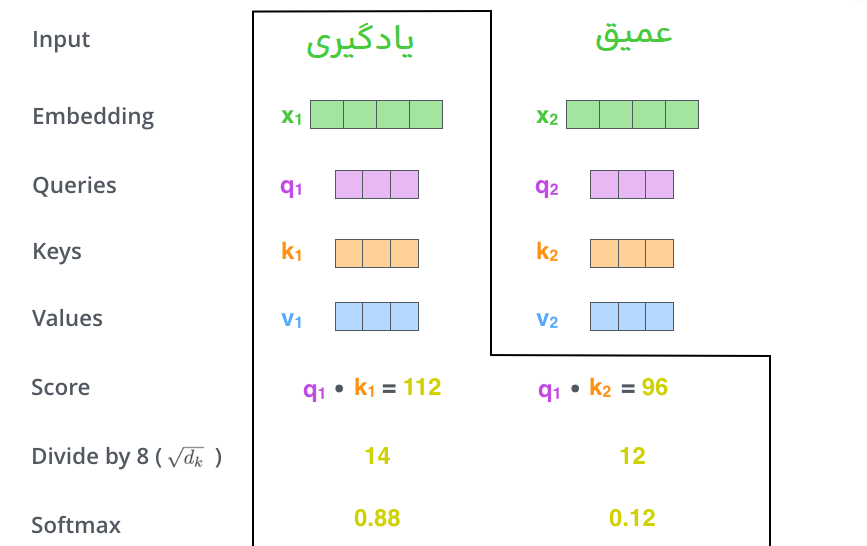
این امتیاز softmax تعیین میکند که هر کلمه در این موقعیت چقدر بیان شود. واضح است که کلمه در این موقعیت بالاترین امتیاز softmax را خواهد داشت، اما گاهی اوقات مفید است که به کلمه دیگری که به کلمه فعلی مرتبط است توجه کنیم.
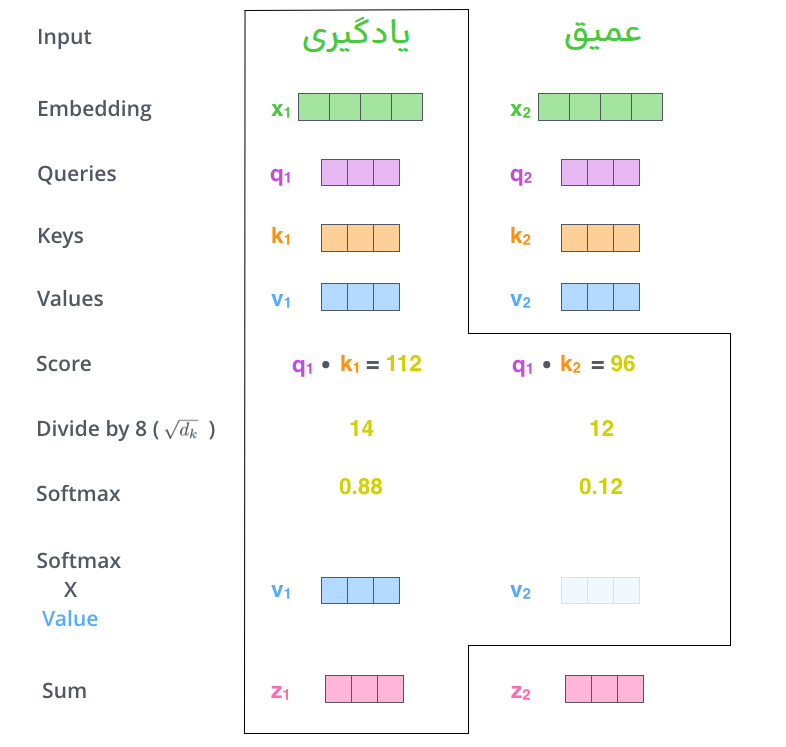
مرحله پنجم این است که هر بردار مقدار (value) را با امتیاز softmax ضرب کنیم (برای آمادهسازی جهت جمع کردن آنها). منطق در اینجا این است که مقادیر کلمه(های)ی که میخواهیم بر روی آنها تمرکز کنیم را دست نخورده نگه داریم و کلمات غیرمرتبط را نادیده بگیریم (با ضرب آنها در اعداد بسیار کوچک مثل 0.001، به عنوان مثال).
مرحله ششم این است که بردارهای مقدار وزندار را جمع کنیم. این کار خروجی لایه توجه بهخود را در این موقعیت (برای اولین کلمه) تولید میکند.
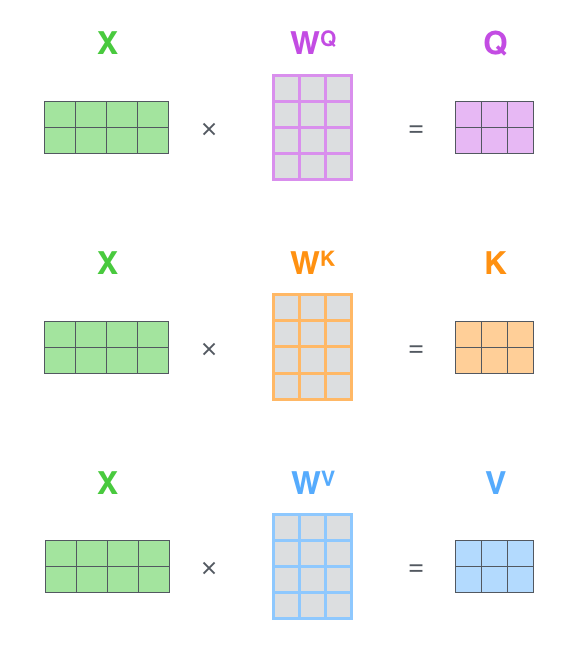
محاسبه توجه-به-خود به صورت ماتریسی
اولین گام محاسبه ماتریسهای Query، Key و Value است. این کار را با بستهبندی امبدینگها در یک ماتریس X و ضرب آن در ماتریسهای وزنی که آموزش دادهایم (WQ، WK، WV) انجام میدهیم.
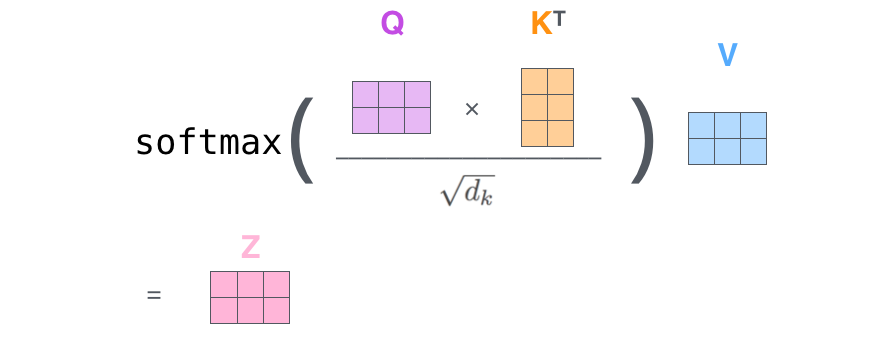
محاسبه توجه به خود (Self-Attention) به صورت ماتریسی
هیولایی با سرهای بسیار
مقاله با افزودن مکانیزمی به نام “توجه چندسر” (Multi-headed Attention)، لایه توجه به خود را بهبود بخشید. این کار به دو صورت عملکرد لایه توجه را ارتقا میدهد:
- افزایش توانایی مدل در تمرکز روی موقعیتهای مختلف: بله، در مثال بالا، z1 شامل بخشهایی از هر رمزگذاری دیگر میشود، اما ممکن است همچنان تحت تأثیر کلمه اصلی قرار گیرد. اگر جملهای مانند “The animal didn’t cross the street because it was too tired” را ترجمه میکنیم، دانستن اینکه “it” به چه کلمهای اشاره میکند، مفید خواهد بود.
- ایجاد چندین “زیر فضای بازنمایی” برای لایه توجه: با استفاده از توجه چندسر، نه تنها یک مجموعه ماتریس وزن پرسش/کلید/مقدار (Query/Key/Value) خواهیم داشت، بلکه چندین مجموعه وجود خواهد داشت. ترنسفورمر از هشت سر توجه استفاده میکند، بنابراین در نهایت برای هر رمزگذار/رمزگشا هشت مجموعه داریم. هر یک از این مجموعهها بهطور تصادفی مقداردهی اولیه میشود. سپس پس از آموزش، هر مجموعه برای نگاشت امبدینگهای ورودی (یا بردارهای حاصل از رمزگذارها/رمزگشاهای پایینتر) به یک زیر فضای بازنمایی متفاوت استفاده میشود.
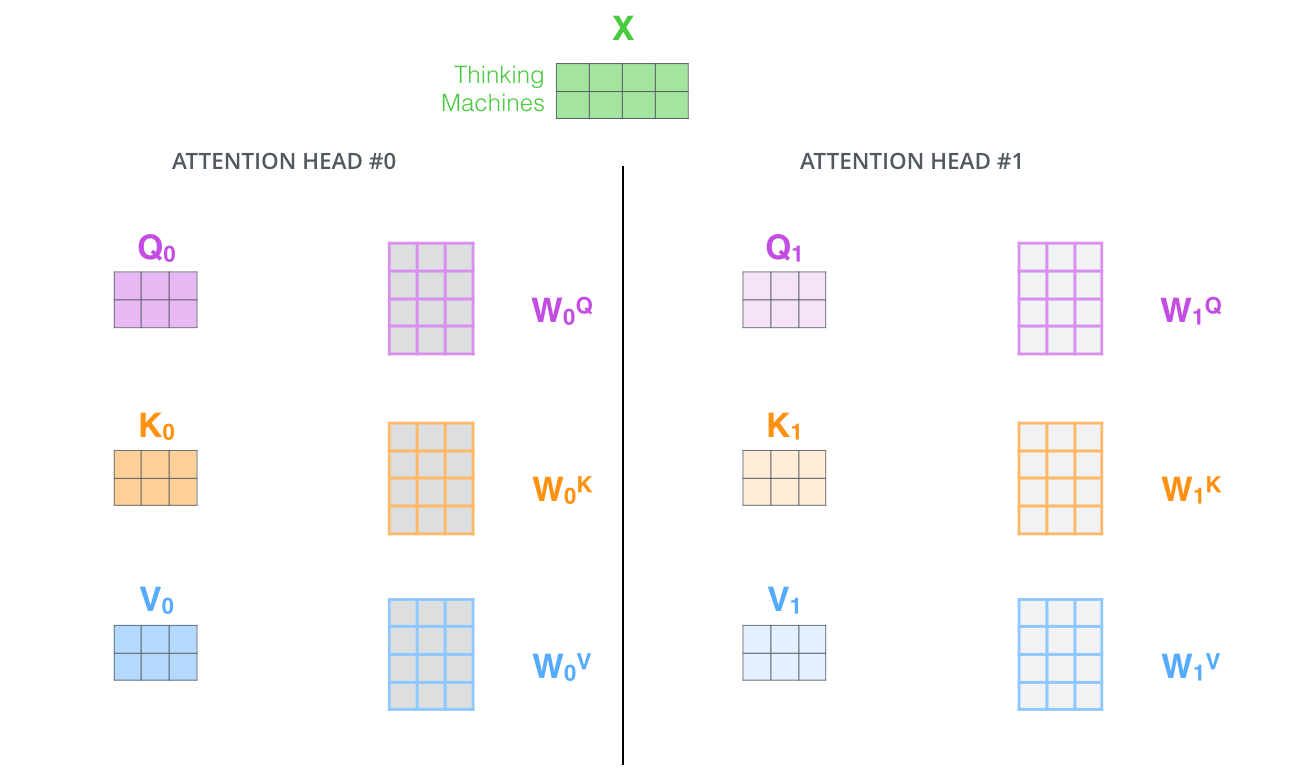
در توجه چندسر (Multi-headed Attention)، برای هر سر ماتریسهای وزن  ،
،  و
و  جداگانه نگه میداریم که در نتیجه، ماتریسهای // متفاوتی تولید میشوند. همانطور که قبلاً انجام دادیم،
جداگانه نگه میداریم که در نتیجه، ماتریسهای // متفاوتی تولید میشوند. همانطور که قبلاً انجام دادیم،  را در ماتریسهای
را در ماتریسهای  ،
،  و
و  ضرب میکنیم تا ماتریسهای // را تولید کنیم.
ضرب میکنیم تا ماتریسهای // را تولید کنیم.
اگر محاسبه توجه-به-خود که قبلاً توضیح داده شد را با استفاده از هشت مجموعه مختلف ماتریسهای وزن، هر بار بهطور جداگانه انجام دهیم، در نهایت با هشت ماتریس  مختلف مواجه خواهیم شد. به عبارت دیگر، با انجام محاسبه توجه به خود برای هر یک از سرهای مختلف، هر سر با استفاده از ماتریسهای وزن مخصوص به خود، نمای متفاوتی از اطلاعات ورودی را تولید میکند و در نتیجه، هشت نمای متفاوت از خروجیها خواهیم داشت.
مختلف مواجه خواهیم شد. به عبارت دیگر، با انجام محاسبه توجه به خود برای هر یک از سرهای مختلف، هر سر با استفاده از ماتریسهای وزن مخصوص به خود، نمای متفاوتی از اطلاعات ورودی را تولید میکند و در نتیجه، هشت نمای متفاوت از خروجیها خواهیم داشت.
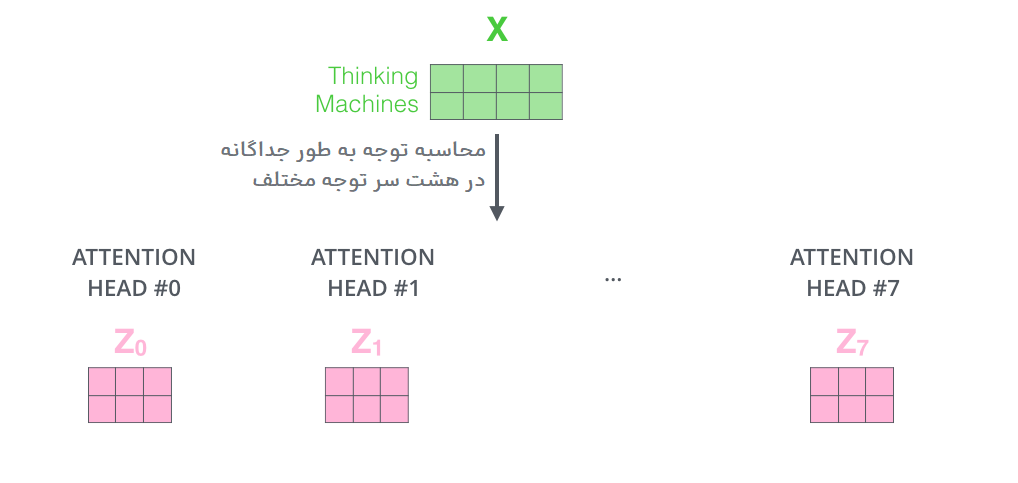
این مسئله چالشبرانگیز است. لایه feed-forward انتظار هشت ماتریس را ندارد – بلکه انتظار یک ماتریس واحد (یا به عبارت دیگر، یک بردار برای هر کلمه) را دارد. بنابراین، نیاز داریم که این هشت ماتریس را به یک ماتریس واحد تبدیل کنیم.
چگونه این کار را انجام میدهیم؟ ما ماتریسها را با هم ادغام (concatenate) میکنیم و سپس آنها را با ماتریس وزنی اضافی WOW_O ضرب میکنیم.
![]()
منبع: https://jalammar.github.io/illustrated-transformer/
مطالب زیر را حتما مطالعه کنید

راهنمای قدم به قدم کرایه کارت گرافیک (GPU) با Vast.ai برای پروژههای هوش مصنوعی
فاینتیونینگ (Fine-tuning) چیست؟

۱۹ نکته ضروری برای آموزش شبکههای عصبی عمیق

با تشکر از صرف وقت با ارزشتان
این پست آموزشی بسیار مفید و راهگشا بود. کاش بزودی نسخه کاملتری از ان منتشر شود